Google MapReduce编程模型与大规模数据处理
需积分: 10 184 浏览量
更新于2024-07-16
收藏 563KB PDF 举报
"Google-MapReduce中文版1.0版,由阎伟编著,提供了一种编程模型和处理大规模数据集的算法实现。MapReduce包含Map函数和Reduce函数,用于处理key/value对数据,适合并行化处理。该实现可在大量普通机器组成的集群上运行,自动处理数据分割、调度、错误处理和通信。MapReduce已在Google内部广泛应用,每天执行上千个任务,处理TB级别的数据。"
MapReduce是Google提出的一种分布式计算框架,它简化了在大规模数据集上进行处理的复杂性,使得没有并行计算经验的程序员也能高效地利用分布式系统。这个模型的核心由两个主要部分构成:Map阶段和Reduce阶段。
1. Map阶段:用户定义的Map函数接收一组key/value对作为输入,对每个输入对进行独立处理,然后生成新的中间key/value对。这个阶段的主要目的是将原始数据转化为更适合聚合的形式。例如,对于文本分析,Map函数可能将每个单词作为key,出现次数作为value。
2. Reduce阶段:Reduce函数接着处理Map阶段产生的中间key/value对。它将所有具有相同中间key的value进行合并,通常涉及到聚合操作,如求和、平均或最大值等。这一步骤允许对Map阶段的结果进行汇总,生成最终的结果。
MapReduce的架构设计考虑了大规模分布式环境的挑战,如数据分布、容错性和性能优化。系统会自动将输入数据分割成多个块,并在集群中的多台机器上并行执行Map任务。同时,Reduce任务通过shuffle阶段,将相同的中间key的value分组,以便于Reduce函数处理。此外,MapReduce框架还处理了节点故障,当某个工作节点失效时,它能够重新调度任务到其他可用节点,确保计算的连续性。
在Google的实践中,MapReduce被广泛应用于各种数据处理任务,如构建搜索引擎的倒排索引、分析网络日志、统计网页链接关系等。由于其简单易用和强大的处理能力,MapReduce成为了大数据处理领域的一个里程碑,为后来的Hadoop和其他分布式计算框架奠定了基础。
MapReduce提供了一个抽象层,将复杂的分布式计算细节隐藏起来,让开发者能够专注于业务逻辑,而无需深入了解底层的分布式系统实现。这种设计理念极大地促进了大数据处理技术的发展,使得更多企业和开发者能够处理和分析前所未有的大规模数据。
Google MapReduce 中文版 1.0 版
作者/编著者:阎伟 邮件: andy.yanwei@163.com 博客: http://andyblog.sinaapp.com 微博:http://weibo.com/2152410864 5/24
(例如,hash(key) mod R), Reduce 调用也被分布到多台机器上执行。分区数量(R)和分区函数由用户来指
定。
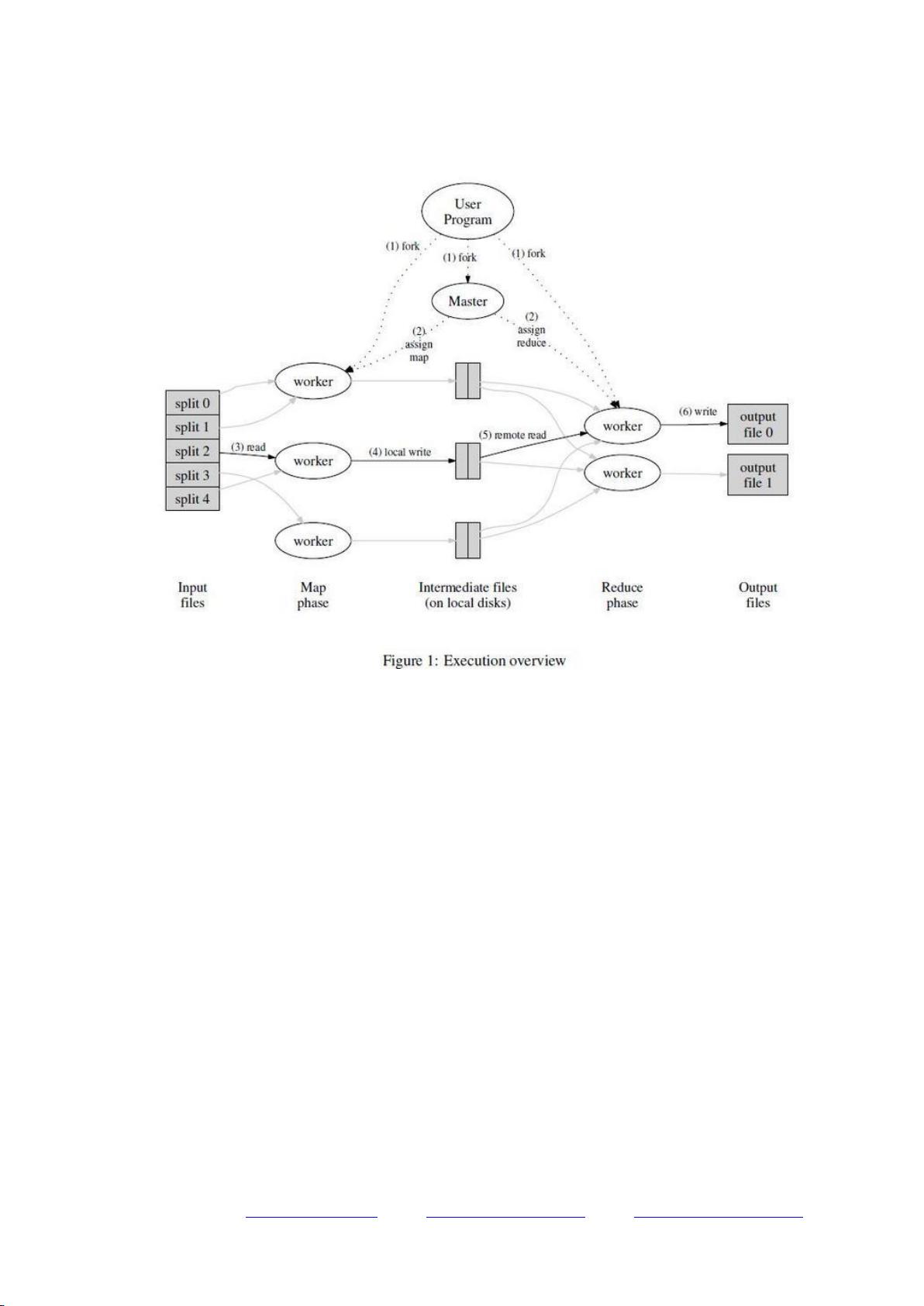
图 1 展示了我们的 MapReduce 实现中操作的全部流程。当用户调用 MapReduce 函数时,将发生下面的一
系列动作(下面的序号和图 1 中的序号一一对应):
1. 用户程序首先调用的 MapReduce 库将输入文件分成 M 个数据片度,每个数据片段的大小一般从
16MB 到 64MB(可以通过可选的参数来控制每个数据片段的大小)。然后用户程序在机群中创建大量
的程序副本。
2. 这些程序副本中的有一个特殊的程序–master。副本中其它的程序都是 worker 程序,由 master 分配
任务。有 M 个 Map 任务和 R 个 Reduce 任务将被分配,master 将一个 Map 任务或 Reduce 任务分配
给一个空闲的 worker。
3. 被分配了 map 任务的 worker 程序读取相关的输入数据片段,从输入的数据片段中解析出 key/value
pair,然后把 key/value pair 传递给用户自定义的 Map 函数,由 Map 函数生成并输出的中间 key/value
pair,并缓存在内存中。
4. 缓存中的 key/value pair 通过分区函数分成 R 个区域,之后周期性的写入到本地磁盘上。缓存的
key/value pair 在本地磁盘上的存储位置将被回传给 master,由 master 负责把这些存储位置再传送给
Reduce worker。
剩余23页未读,继续阅读

gogobody
- 粉丝: 31
- 资源: 10
 我的内容管理
展开
我的内容管理
展开







最新资源
- Fall2019-group-20:GitHub Classroom创建的Fall2019-group-20
- cv-exercise:用于学习Web开发的仓库
- 雷赛 3ND583三相步进驱动器使用说明书.zip
- Rocket-Shoes-Context
- tsmc.13工艺 standardcell库pdk
- 回归应用
- 汇川—H2U系列PLC模拟量扩展卡用户手册.zip
- mysql-5.6.4-m7-winx64.zip
- PortfolioV2.0:作品集网站v2.0
- 线性代数(第二版)课件.zip
- 直线阵采用切比学夫加权控制主旁瓣搭建OFDM通信系统的框架的实验-综合文档
- quicktables:字典的超快速列表到Python 23的预格式化表转换库
- 彩色无纸记录仪|杭州无纸记录仪.zip
- DiagramDSL:方便的DSL构建图
- api.vue-spotify
- LLDebugTool:LLDebugTool是面向开发人员和测试人员的调试工具,可以帮助您在非xcode情况下分析和处理数据。
