"Docker配置Hadoop技术平台指南:集群搭建与调优"
需积分: 0 53 浏览量
更新于2024-03-20
收藏 999KB PDF 举报
使⽤Docker搭建Hadoop技术平台是当前企业构建大数据处理平台的主流方式之一。本次搭建的Hadoop集群共有5台机器,分别为 h01、h02、h03、h04、h05,其中 h01 为 master 节点,其余为 slave 节点。在配置虚拟机时,建议每台机器至少拥有1盒2线程、8G内存和30G硬盘的资源,而最初使用4G内存时,HBase和Spark运行出现异常。本次搭建所使用的技术版本包括:JDK 1.8、Scala 2.11.12、Hadoop 3.3.3、Hbase 3.0.0和Spark 3.3.0。
首先,需要在Ubuntu 22.04系统上安装Docker。在Ubuntu系统下,对Docker的所有操作都需要使用sudo权限,如果当前用户已经是root账号,则不需要加sudo命令。没有使用sudo权限的话,Docker相关命令将无法执行。在Ubuntu系统中,安装Docker一般通过apt-get命令进行操作。安装完成后,可以使用docker version命令来验证是否安装成功,并查看当前版本信息。
接下来是搭建Hadoop平台的具体步骤。首先在每台机器上安装Java、Scala、Hadoop、Hbase和Spark这些组件。确保每个节点都安装了上述软件,并且配置了相应的环境变量。在配置Hadoop时,需要在hadoop-env.sh中设置JAVA_HOME和HADOOP_CONF_DIR等环境变量,以确保Hadoop能够正确运行。在配置Hbase时,需要修改hbase-site.xml配置文件,包括对HMaster、HRegionServer等参数进行设置。而对于Spark的配置,则需要在spark-env.sh中设置JAVA_HOME和SPARK_HOME等环境变量,以确保Spark可以正常工作。
在搭建集群时,需要在每台机器上配置hosts文件,以便节点之间可以相互通信。将每个节点的主机名和对应的IP地址添加到hosts文件中。此外,在每个节点上还需要配置ssh免密登录,以实现集群节点之间的通信和管理。
最后,需要在master节点上启动Hadoop和Hbase集群,以及Spark集群。通过启动start-all.sh脚本来启动Hadoop和Hbase集群,启动Spark集群需要使用start-master.sh和start-slaves.sh脚本。在集群启动完成后,可以通过浏览器访问Hadoop的Web界面来查看集群的运行状态,包括HDFS的存储情况、MapReduce任务的运行情况等。同时,也可以通过Spark的Web界面来监控Spark应用程序的运行情况,包括任务的执行情况、资源的使用情况等。
通过本次搭建Hadoop平台的实践,不仅可以加深对Hadoop、Hbase和Spark等大数据处理技术的理解,还可以提高对Docker容器化技术的应用能力。搭建Hadoop平台不仅可以帮助企业更好地处理大数据,提升数据处理效率,还可以为企业提供更多的数据应用和挖掘机会。因此,掌握Docker搭建Hadoop技术平台的方法和技术要点是非常重要的。希望本文的介绍和总结对大家有所帮助,谢谢!
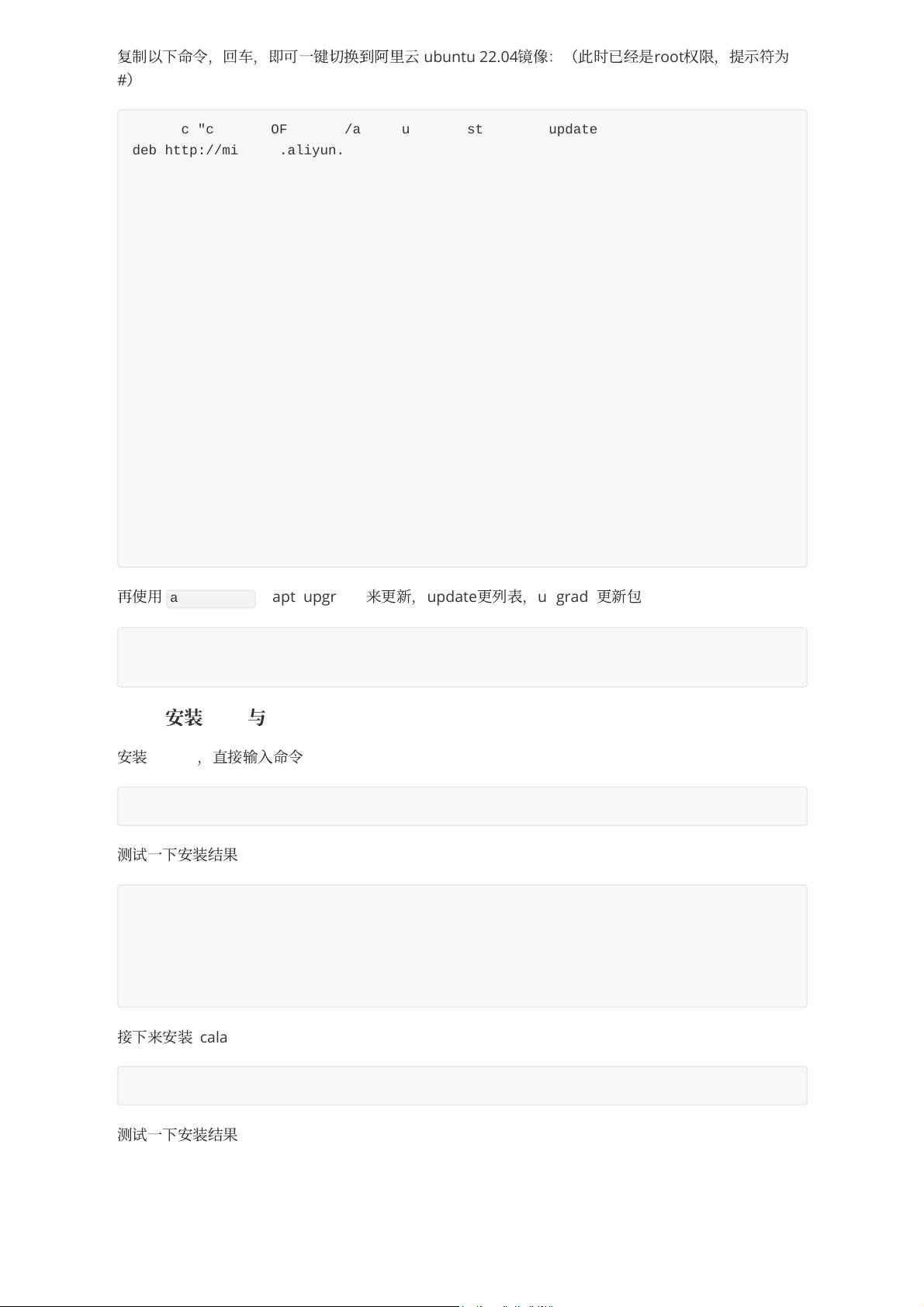
复
制
以
下
命
令
,
回
⻋
,
即
可
⼀
键
切
换
到
阿
⾥
云
ubuntu 22.04
镜
像
:
(
此
时
已
经
是
root
权
限
,
提
⽰
符
为
#
)
再
使
⽤
apt update / apt upgrade
来
更
新
,
update
更
列
表
,
upgrade
更
新
包
2.1.2
安
装
Java
与
Scala
安
装
jdk 1.8
,
直
接
输
⼊
命
令
测
试
⼀下
安
装
结
果
接
下
来
安
装
scala
测
试
⼀下
安
装
结
果
bash -c "cat << EOF > /etc/apt/sources.list && apt update
deb http://mirrors.aliyun.com/ubuntu/ jammy main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ jammy main restricted universe
multiverse
deb http://mirrors.aliyun.com/ubuntu/ jammy-security main restricted universe
multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ jammy-security main restricted universe
multiverse
deb http://mirrors.aliyun.com/ubuntu/ jammy-updates main restricted universe
multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ jammy-updates main restricted universe
multiverse
deb http://mirrors.aliyun.com/ubuntu/ jammy-proposed main restricted universe
multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ jammy-proposed main restricted universe
multiverse
deb http://mirrors.aliyun.com/ubuntu/ jammy-backports main restricted universe
multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ jammy-backports main restricted
universe multiverse
EOF"
root@27941809078c:/# apt update
root@27941809078c:/# apt upgrade
root@27941809078c:/# apt install openjdk-8-jdk
root@27941809078c:/# java -version
openjdk version "1.8.0_312"
OpenJDK Runtime Environment (build 1.8.0_312-8u312-b07-0ubuntu1-b07)
OpenJDK 64-Bit Server VM (build 25.312-b07, mixed mode)
root@27941809078c:/#
root@27941809078c:/# apt install scala
剩余22页未读,继续阅读
107 浏览量
131 浏览量
283 浏览量
2025-01-06 上传
144 浏览量
138 浏览量
133 浏览量
206 浏览量


欣婷
- 粉丝: 1105
 我的内容管理
展开
我的内容管理
展开







最新资源
- Python大数据应用教程:基础教学课件
- Android事件分发库:对象池与接口回调实现指南
- C#开发的斗地主网络版游戏特色解析
- 微信小程序地图功能DEMO展示:高德API应用实例
- 构建游戏排行榜API:Azure Functions和Cosmos DB的结合
- 实时监控系统进程CPU占用率方法与源代码解析
- 企业商务谈判网站模板及技术源码资源合集
- 实现Webpack构建后自动上传至Amazon S3
- 简单JavaScript小计算器的制作教程
- ASP.NET中jQuery EasyUI应用与示例解析
- C语言实现AES与DES加密算法源码
- 开源项目实现复古游戏机控制器输入记录与回放
- 掌握Android与iOS异步绘制显示工具类开发
- JAVA入门基础与多线程聊天售票系统教程
- VB API实现串口通信的调试方法及源码解析
- 基于C#的仓库管理系统设计与数据库结构分析
