




B树家族详解:B树、B+树、B*树到R树
"B树、B+树、B*树和R树是数据库和文件系统中常用的高效数据结构,尤其在处理大量数据时。本文详细介绍了这些数据结构的原理和应用场景,旨在帮助初学者理解它们的工作机制。"
文章首先介绍了动态查找树的不同类型,包括二叉查找树、平衡二叉查找树和红黑树。这些树结构的查找效率与树的深度紧密相关,降低树的深度可以提高查找速度。然而,在实际的大规模数据存储场景中,如数据库索引,由于每个节点能存储的数据有限,二叉查找树可能会变得非常深,导致频繁的磁盘I/O操作,从而降低查询效率。
为了解决这个问题,多路查找树的概念被引入,特别是平衡多路查找树——B树。B树是一种自平衡的多叉树,它的设计目标是减少磁盘I/O操作,通过增大每个节点的子节点数量来减小树的高度。B树的关键特性在于它能够保持数据平衡,使得在树的任何层次,节点的最大和最小孩子数差距不大,从而降低了树的高度。
接着,文章进一步介绍了B+树,它是B树的一种变体,所有数据都存储在叶子节点中,并且叶子节点之间通过指针连接,方便进行范围查询。B+树的这一特性使其在数据库索引中表现优秀,尤其是对于范围查询和全表扫描。
B*树是B+树的改进版本,它在非叶子节点也包含了指向数据的指针,进一步提高了查询效率,减少了磁盘I/O次数。这使得B*树在数据存储系统中也得到了广泛应用。
最后,文章提到了R树,这是一种多维空间数据索引结构,适用于地理信息系统或图像数据库等处理多维数据的场景。R树能够有效地管理空间对象,支持高效的范围查询和覆盖查询。
总结来说,B树、B+树和B*树是为了解决大规模数据存储和检索的效率问题而设计的,它们通过优化树结构以减少磁盘I/O,提高查询性能。R树则在多维数据场景下提供了优秀的解决方案。这些数据结构的理解和应用对于理解和设计高效的数据库系统至关重要。

int file_num;
/*文件名(key)*/
char * file_name[max_file_num];
/*指向子节点的指针*/
BTNode * BTptr[max_file_num+1];
/*文件在硬盘中的存储位置*/
FILE_HARD_ADDR offset[max_file_num];
}BTNode;
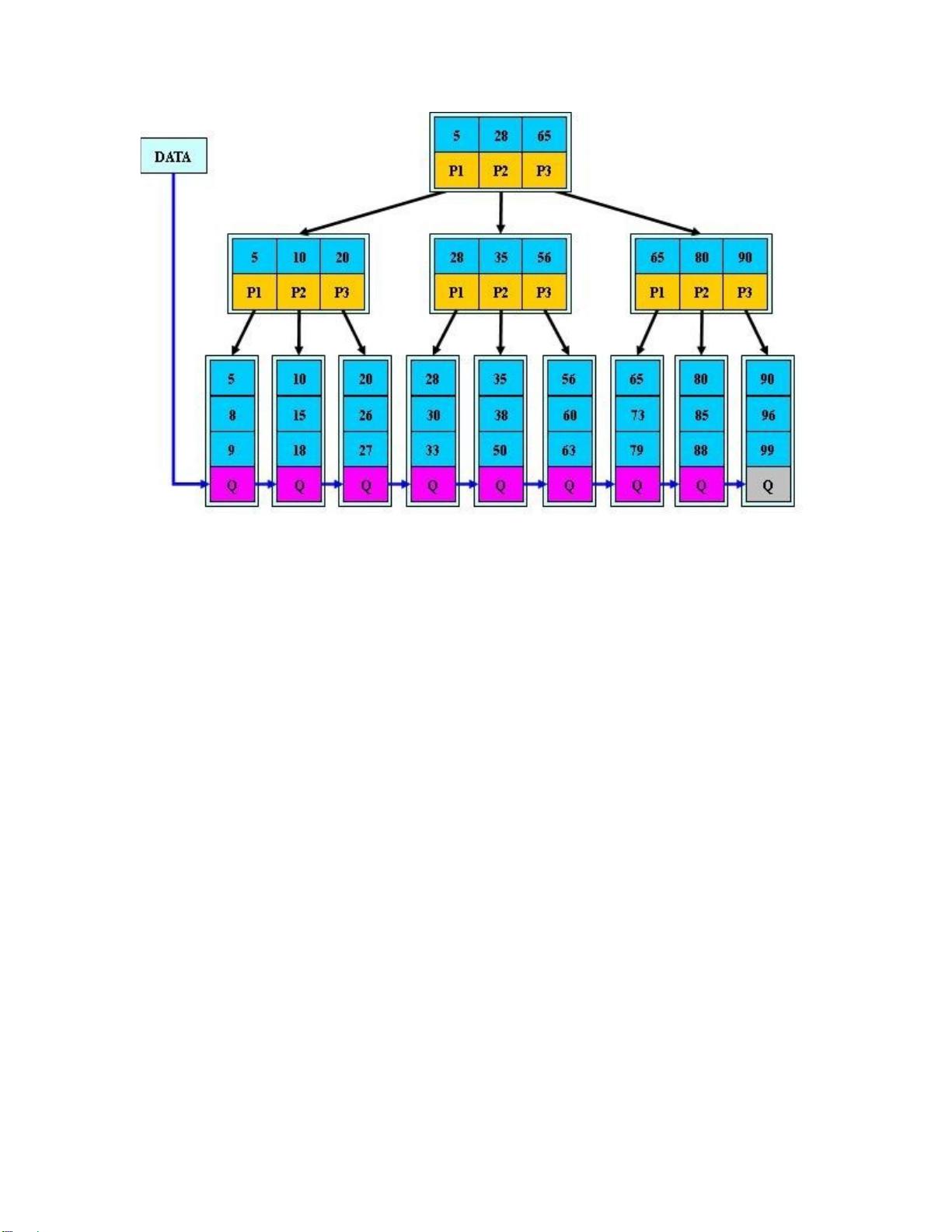
假如每个盘块可以正好存放一个 B 树的结点(正好存放 2 个文件名)。那么一个 BTNode 结
点就代表一个盘块,而子树指针就是存放另外一个盘块 的地址。
下面,咱们来模拟下查找文件 29 的过程:
(1) 根据根结点指针找到文件目录的根磁盘块 1,将其中的信息导入内存。【磁盘 IO 操
作 1 次】
(2) 此时内存中有两个文件名 17,35 和三个存储其他磁盘页面地址的数据。根据算法我
们发现 17<29<35,因此我们找到指针 p2。
(3) 根据 p2 指针,我们定位到磁盘块 3,并将其中的信息导入内存。【磁盘 IO 操作 2 次】
(4) 此时内存中有两个文件名 26,30 和三个存储其他磁盘页面地址的数据。根据算法我
们发现 26<29<30,因此我们找到指针 p2。
(5) 根据 p2 指针,我们定位到磁盘块 8,并将其中的信息导入内存。【磁盘 IO 操作 3 次】
(6) 此时内存中有两个文件名 28,29。根据算法我们查找到文件 29,并定位了该文件内
存的磁盘地址。
分析上面的过程,发现需要 3 次磁盘 IO 操作和 3 次内存查找操作。关于内存中的文件名查找,
由于是一个有序表结构,可以利用折半查找提高效率。至于 3 次磁盘 IO 操作时影响整个 B 树
查找效率的决定因素。
当然,如果我们使用平衡二叉树的磁盘存储结构来进行查找,磁盘 IO 操作最少 4 次,最多 5
次。而且文件越多,B 树比平衡二叉树所用的磁盘 IO 操作次数将越少,效率也越高。
4.B
+
-tree
B
+
-tree:是应文件系统所需而产生的一种 B-tree 的变形树。
一棵 m 阶的 B+树和 m 阶的 B 树的差异在于:
1.有 n 棵子树的结点中含有 n 个关键字; (而 B 树是 n 棵子树有 n-1 个关键字)
2.所有的叶子结点中包含了全部关键字的信息,及指向含有这些关键字记录的指针,
且叶子结点本身依关键字的大小自小而大的顺序链接。 (而 B 树的叶子节点并没有包括全
部需要查找的信息)
3.所有的非终端结点可以看成是索引部分,结点中仅含有其子树根结点中最大(或最
小)关键字。 (而 B 树的非终节点也包含需要查找的有效信息)
剩余32页未读,继续阅读
相关推荐





hanzejl
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开








最新资源
- BP神经网络在人脸识别中的应用与Matlab实现
- FF HSE基金会现场总线高速以太网通信研究及实现
- Springboot项目DemoOne:快速搭建与数据库实践指南
- 江海鹰Pspice课件精要解读
- 为Chrome扩展Easy Access-crx打造快捷网址
- 智能建筑办公楼解决方案详细介绍
- EtherCAT协议中文原版资料大全
- STM32-CAN-OBD解决方案与应用指南
- kubectl-check:高效检测Kubernetes资源状态插件
- ISO26262标准解读及翻译文档
- HTTPCore 4.4.5 版本压缩包内容及使用教程
- 9Cr2轧棍钢焊接工艺的详细操作指南
- 基于Tensorflow实现的128关键点人脸识别技术
- MacOS虚拟机模板制作指南及资源下载
- 《五夜弗雷迪》与NextJS开发教程
- STM32超声波成像技术资料解压缩






















