从零开始:Java实现自定义网络爬虫教程
需积分: 11 84 浏览量
更新于2024-07-27
收藏 2.49MB PDF 举报
网络爬虫教程: "自己动手写网络爬虫" 这本书深入探讨了如何构建和实现一个基本的网络爬虫,特别是在Java编程环境下。章节首先介绍了网络爬虫的基础概念,包括搜索引擎的工作原理,如Spider(网络蜘蛛)的角色,以及为何即使大型搜索引擎如百度和Google已经自动化抓取大量信息,个体或企业依然需要自行编写爬虫的原因。它们可能需要定制化的数据源,用于数据仓库分析或特定领域的信息挖掘,甚至个人投资者可能利用爬虫获取股市信息。
第1章全面剖析网络爬虫时,重点讲解了抓取网页的基本操作。抓取网页的核心步骤包括通过URL向服务器发送请求,获取响应,并处理HTTP状态码。URL在这个过程中扮演关键角色,它是一个统一资源标识符,用来定位网络上的各种资源,如HTML文档、图片、视频等。URI通常由三部分构成:访问机制、主机名和资源路径。
1.1 抓取网页的实践操作
这部分具体演示了如何使用Java来抓取网页。学习者会被引导从理解URL开始,了解如何在浏览器中输入URL,如输入http://www.lietu.com,浏览器实际上是作为客户端与服务器进行交互,请求资源并将其下载到本地。此外,还会介绍如何通过浏览器查看和分析网页的源代码,以便更好地理解抓取过程。
1.1.1 深入理解URL和URI
在这里,作者强调了理解URL背后的概念对于编写爬虫的重要性。URI是通用的,它不仅限于HTTP协议,还可以适用于其他协议。通过深入解析URI的组成部分,读者可以掌握如何构建和解析不同的URL,这对于动态网页和API调用尤为重要。
本章节内容涵盖了网络爬虫的基本技术原理和实践应用,包括URL和URI的结构,抓取过程中的HTTP状态码管理,以及如何使用Java进行网页抓取。读者将在此基础上建立起编写自己的网络爬虫的能力,无论是为了商业分析、学术研究还是个人兴趣,都将为他们提供宝贵的工具和知识。
12
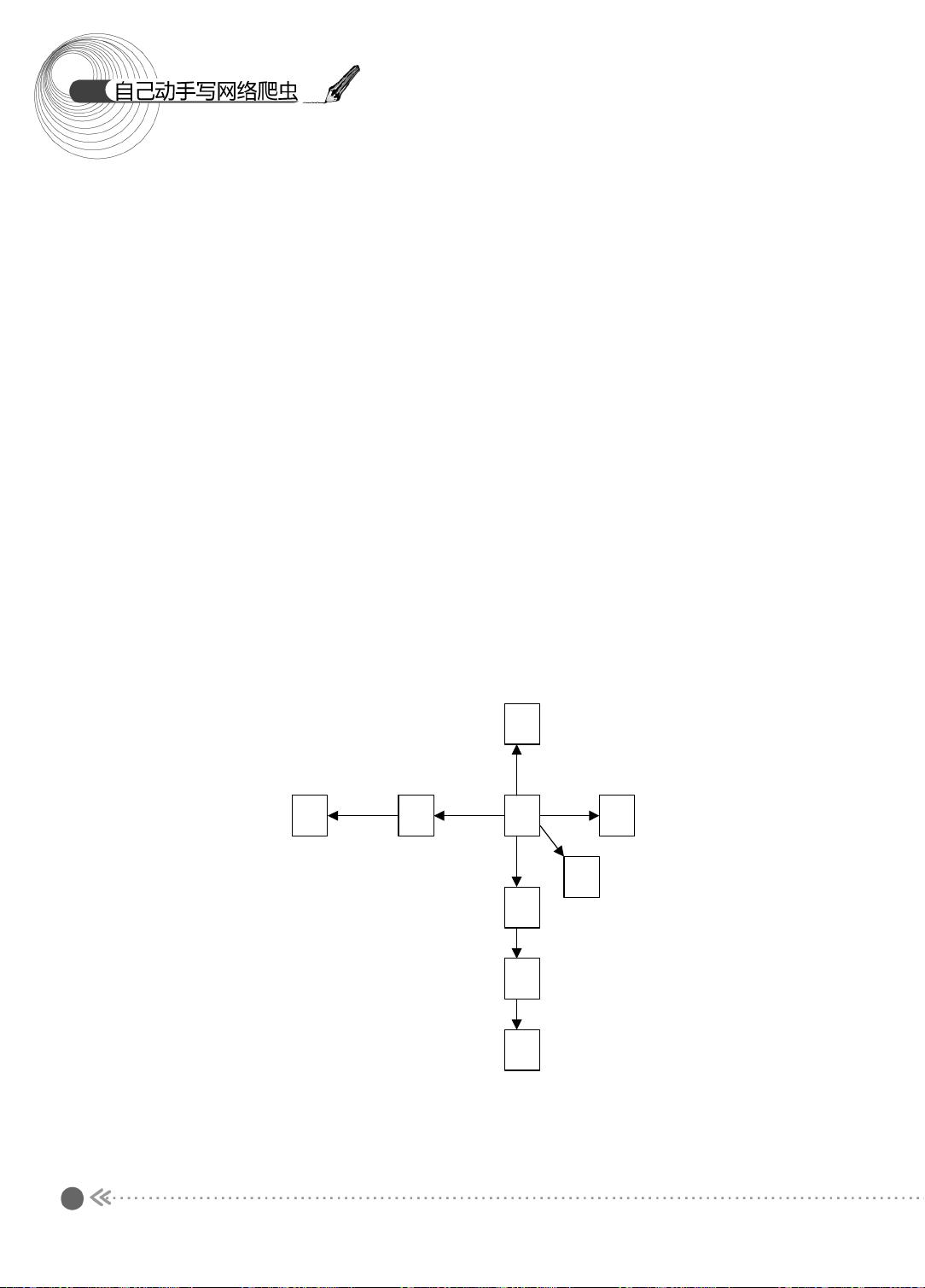
1
的遍历的方式对互联网这个超级大 “ 图 ” 进行访问。图的遍历通常可分为宽度优先遍历和
深度优先遍历两种方式。但是深度优先遍历可能会在深度上过 “ 深 ” 地遍历或者陷入 “ 黑
洞 ” ,大多数爬虫都不采用这种方式。另一方面,在爬取的时候,有时候也不能完全按照
宽度优先遍历的方式 , 而是给待遍历的网页赋予一定的优先级 , 根据这个优先级进行遍历
,
这种方法称为带偏好的遍历。本小节会分别介绍宽度优先遍历和带偏好的遍历。
1.2.1 图的宽度优先遍历
下面先来看看图的宽度优先遍历过程 。 图的宽度优先遍历 (BFS) 算法是一个分层搜索的
过程,和树的层序遍历算法相同。在图中选中一个节点,作为起始节点,然后按照层次遍
历的方式,一层一层地进行访问。
图的宽度优先遍历需要一个队列作为保存当前节点的子节点的数据结构。具体的算法
如下所示:
(1) 顶点 V 入队列。
(2) 当队列非空时继续执行,否则算法为空。
(3) 出队列,获得队头节点 V ,访问顶点 V 并标记 V 已经被访问。
(4) 查找顶点 V 的第一个邻接顶点 col 。
(5) 若 V 的邻接顶点 col 未被访问过,则 col 进队列。
(6) 继续查找 V 的其他邻接顶点 col ,转到步骤 (5) ,若 V 的所有邻接顶点都已经被访
问过,则转到步骤 (2) 。
下面,我们以图示的方式介绍宽度优先遍历的过程,如图 1.3 所示。
G
B
A
C
D
F
E
I
H
图 1.3 宽度优先遍历过程

剩余67页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
2024-12-23 上传
2024-12-23 上传
2024-12-23 上传

code_nx
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- C8051下载线制作
- Java学习从入门到精通
- 国家标准软件开发规范---软件需求说明书规范.pdf
- 毕业设计计算机相关文章翻译
- 国家标准软件开发规范---软件配置管理计划规范.pdf
- Wrox - Beginning SQL(2005).pdf
- div+css+js 实现透明屏蔽当前页面,并弹出新层进行操作。推荐哦
- 基于J2EE的Ajax宝典
- 国家标准软件开发规范---模块开发卷宗规范.pdf
- Weblogic管理员手册
- 国家标准软件开发规范---概要设计说明书规范.pdf
- 国家标准软件开发规范---测试计划规范.pdf
- 构建嵌入式Linux系统(英文第三版)
- 国家标准软件开发规范模板---操作手册规范.pdf
- TIPTOP GP 如何进行数据的导入、导出
- ibatis 开发指南.pdf
