NoSQL数据库入门:思想、技术与软件探索
需积分: 32 21 浏览量
更新于2024-07-29
收藏 3.88MB PDF 举报
"NOSQL 技术文档,探讨NOSQL思想、框架及软件应用,适合初学者入门"
NOSQL(Not Only SQL)数据库是一种非关系型的数据库技术,它针对大规模数据分布式存储和处理的需求,提供了不同于传统SQL数据库的解决方案。NOSQL的核心思想在于放弃对ACID(原子性、一致性、隔离性和持久性)事务的严格支持,转而追求更高的可扩展性、高可用性和容错性。
1. 思想篇
- CAP理论:在分布式系统中,无法同时满足一致性(Consistency)、可用性(Availability)和分区容忍性(Partition Tolerance)。NOSQL通常选择AP或CP,牺牲强一致性以换取系统性能和稳定性。
- 最终一致性:系统中的所有副本经过一段时间后,最终会达到一致状态,允许短暂的数据不一致。
- BASE理论:基本可用(Basically Available)、软状态(Soft State)、最终一致性(Eventual Consistency),是对CAP理论的一种实践策略。
- I/O的五分钟法则:强调快速响应用户请求,即使数据不完全是最新的。
- Amdahl定律和Gustafson定律:讨论并行计算性能提升的限制和可能性。
2. 手段篇
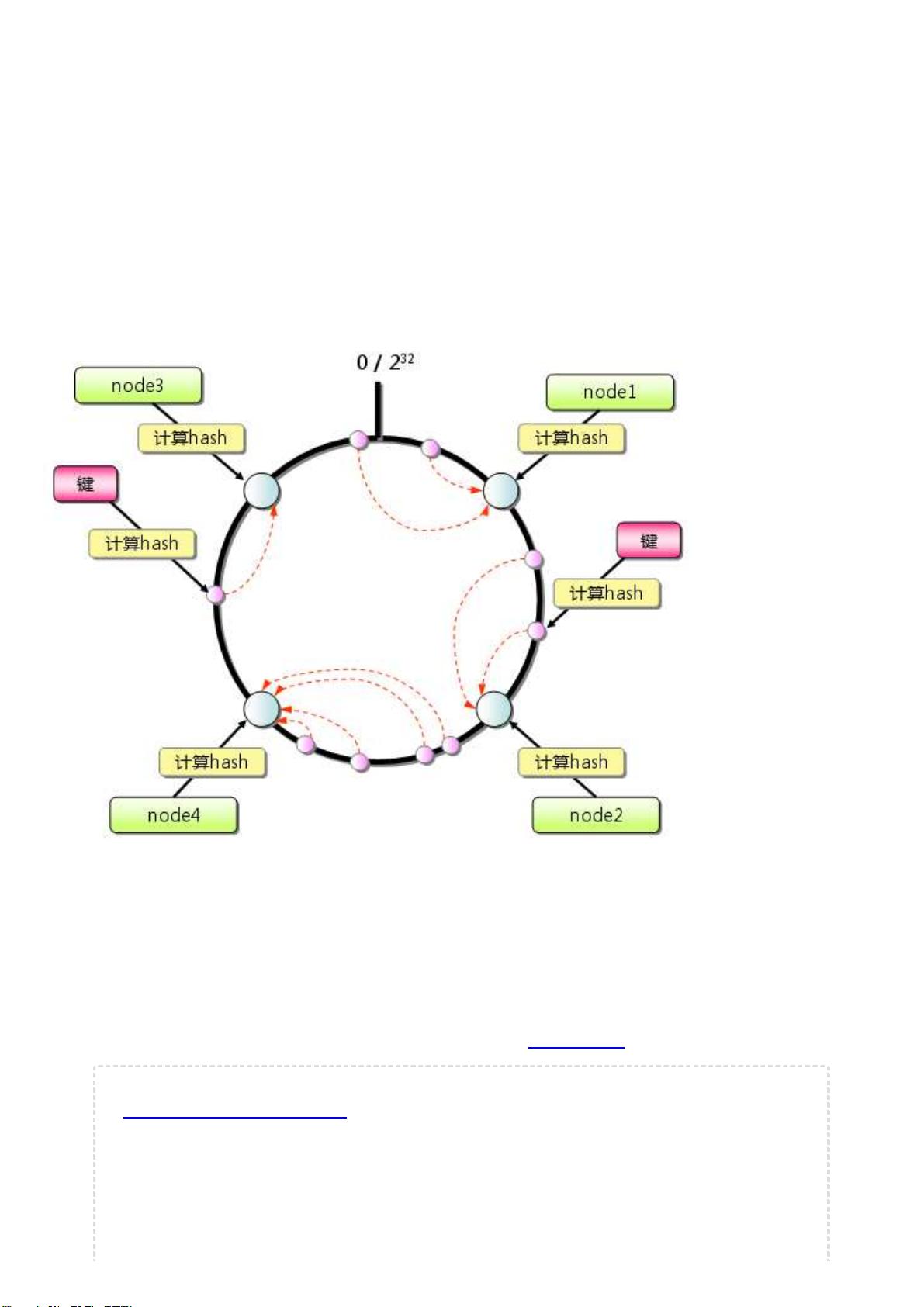
- 一致性哈希:解决分布式系统中负载均衡和数据分布问题。
- 亚马逊现状:亚马逊的Dynamo论文提出了一种基于一致性哈希和虚拟节点的分布式数据库设计。
- QuorumNRW:读写策略,确保数据的一致性和可用性。
- Vectorclock:用于分布式系统中处理时序和冲突检测的工具。
- Gossip协议:通过节点间的信息传播来维护数据一致性,分为StateTransferModel和OperationTransferModel两种模型。
- Merkletree:用于证明数据完整性和减少数据验证的复杂性,常见于区块链中。
- Paxos算法:解决分布式系统中的共识问题。
3. 软件篇
- 亚数据库:如Memcached,提供高速缓存功能,提升系统性能。
- Hadoop之Hbase:基于Hadoop的分布式列式存储系统,适合实时查询大数据。
- Facebook之Cassandra:分布式NoSQL数据库,适用于大规模数据分布式存储,提供高吞吐量和低延迟。
- Google之BigTable:大型分布式多维数据表,用于存储海量数据。
- Yahoo之PNUTS:云数据库系统,提供高性能的数据存储和访问。
NOSQL数据库根据数据模型的不同,可以分为多种类型:
- 列存数据库:如Hbase,适合分析大量结构化数据。
- 文档存储:如MongoDB,以JSON文档形式存储数据。
- 键值对存储:如Amazon SimpleDB,适合简单的键值操作。
- 图形数据库:如Neo4j,用于存储和查询复杂的关系网络。
这些不同的NOSQL数据库软件各有特点,可以根据具体应用场景选择合适的解决方案。例如,Memcached适用于需要高速缓存的场景,Hbase适合实时查询大规模数据,MongoDB则适合处理结构多变的数据。
NOSQL数据库在大数据时代提供了灵活、可扩展的存储和处理方案,适应了互联网应用对数据处理的新需求。其设计思想和软件应用已经广泛应用于社交网络、推荐系统、日志处理等场景。
这个阶段的设计存在以下问题
负载不均衡,尤其是单台发生故障后剩下一台会压力过大。
不能动态增删节点
节点发生故障时需要
client
重新登录
第三阶段
第三阶段第三阶段
第三阶段
打算去掉硬编码的hash() mod n 算法,改用一致性哈希(consistent hashing)分布
假如采用
Dynamo
中的
strategy 1
我们把每台
server
分成
v
个虚拟节点,再把所有虚拟节点
(n*v)
随机分配到一致性哈希的圆环上,这样所有的用户从自
己圆环上的位置顺时针往下取到第一个
vnode
就是自己所属节点。当此节点存在故障时,再顺时针取下一个作为替代
节点。
优点:发生单点故障时负载会均衡分散到其他所有节点,程序实现也比较优雅。
优点:发生单点故障时负载会均衡分散到其他所有节点,程序实现也比较优雅。优点:发生单点故障时负载会均衡分散到其他所有节点,程序实现也比较优雅。
优点:发生单点故障时负载会均衡分散到其他所有节点,程序实现也比较优雅。
亚马逊的现状
亚马逊的现状亚马逊的现状
亚马逊的现状
aw2.0
公司的
Alan Williamson
撰写了一篇报道,主要是关于他在
Amazon EC2
上的体验的,他抱怨说,
Amazon
是
公司唯一使用的云提供商,看起来它在开始时能够适应得很好,但是有一个临界点:
在开始的日子里
Amazon
的表现非常棒。实例在几分钟内启动,几乎没有遇到任何问题,即便是他们
的小实例(
SMALL INSTANCE
)也很健壮,足以支持适当使用的
MySQL
数据库。在
20
个月内,
Amazon
云系统一切运转良好,不需要任何的关心和抱怨。
……
然而,在最后的八个月左右,他们
“
盔甲
”
内的漏洞开始呈现出来了。第一个弱点前兆是,新加入的
Amazon SMALL
实例的性能出现了问题。根据我们的监控,在服务器场中新添加的机器,与原先的
那些相比性能有所下降。开始我们认为这是自然出现的怪现象,只是碰
巧发生在
“
吵闹的邻
居
”
(
Noisy Neighbors
)旁边。根据随机法则,一次快速的停机和重新启动经常就会让我们回到
“
安
静的邻居”旁边,那样我们可以达到目的。
2011-1-9 NoSQL数据库笔谈
yankay.com/…/NoSql Database Note/ 10/57

剩余56页未读,继续阅读
2014-07-21 上传
点击了解资源详情
点击了解资源详情
2020-09-10 上传
2024-08-28 上传
2022-06-16 上传
2024-08-28 上传

hahaxyz
- 粉丝: 0
- 资源: 6
 我的内容管理
展开
我的内容管理
展开







