HBase架构详解:主从设计与数据分布
15 浏览量
更新于2024-08-28
收藏 1.38MB PDF 举报
深入了解HBase架构,我们首先需要理解其核心组成部分和工作原理。HBase是一种开源的、基于列族的NoSQL数据库,它构建在Google的Bigtable之上,采用主从式(Master-Slave)架构,主要由以下几种服务器角色构成:
1. **HBase Master** (HMaster): 这是整个集群的管理者,负责全局的元数据管理和 Region 的分配。HMaster的主要职责包括:
- 区域分配:创建新表、删除表或调整表结构时,HMaster会决定如何将 Regions 分配给RegionServers。
- 负载均衡:根据集群资源状况动态调整 Region 分配,确保数据均匀分布,提高性能。
- 监控与管理:HMaster监控所有 RegionServer 的状态,通过 ZooKeeper 保持与它们的通信。
2. **RegionServer**: 作为数据处理的主要节点,负责实际的读写操作。客户端直接与其通信,每个 RegionServer 可能管理数百个 Regions,每个 Region 包含表中特定范围的行数据。数据的局部性是HBase的一个关键特性,通过将 RegionServer 和 HDFS DataNode 部署在同一物理位置,数据可以快速访问。
3. **HDFS DataNode**: Hadoop分布式文件系统 (HDFS) 的一部分,存储 RegionServer 所管理的实际数据。HDFS负责数据的分布式存储和冗余,提供高可用性和容错能力。
4. **ZooKeeper**: 作为分布式协调服务,ZooKeeper 在HBase架构中扮演了至关重要的角色。它维护集群中活跃节点的状态,确保一致性,并在节点失败时提供故障通知。ZooKeeper 使用多机共识机制,至少需要三到五个节点以保证系统的可靠性。
5. **Regions**: 表格在HBase中被水平分割为多个 Regions,每个 Region 由一个起始键值(startkey)和结束键值(endkey)定义,由相应的 RegionServer 管理。这使得数据访问高效,减少了网络传输量。
6. **NameNode** (在HDFS中): 名称节点维护HDFS中的元数据,包括文件的所有物理数据块信息,但不直接参与HBase的操作。
HBase的组件通过Zookeeper进行协调,如HMaster通过Zookeeper了解RegionServer的状态和变化,而RegionServer则通过Zookeeper与HMaster保持同步。整体来说,HBase通过这样的设计实现了高扩展性、高性能和容错性,是大数据处理场景中的一种有效选择。
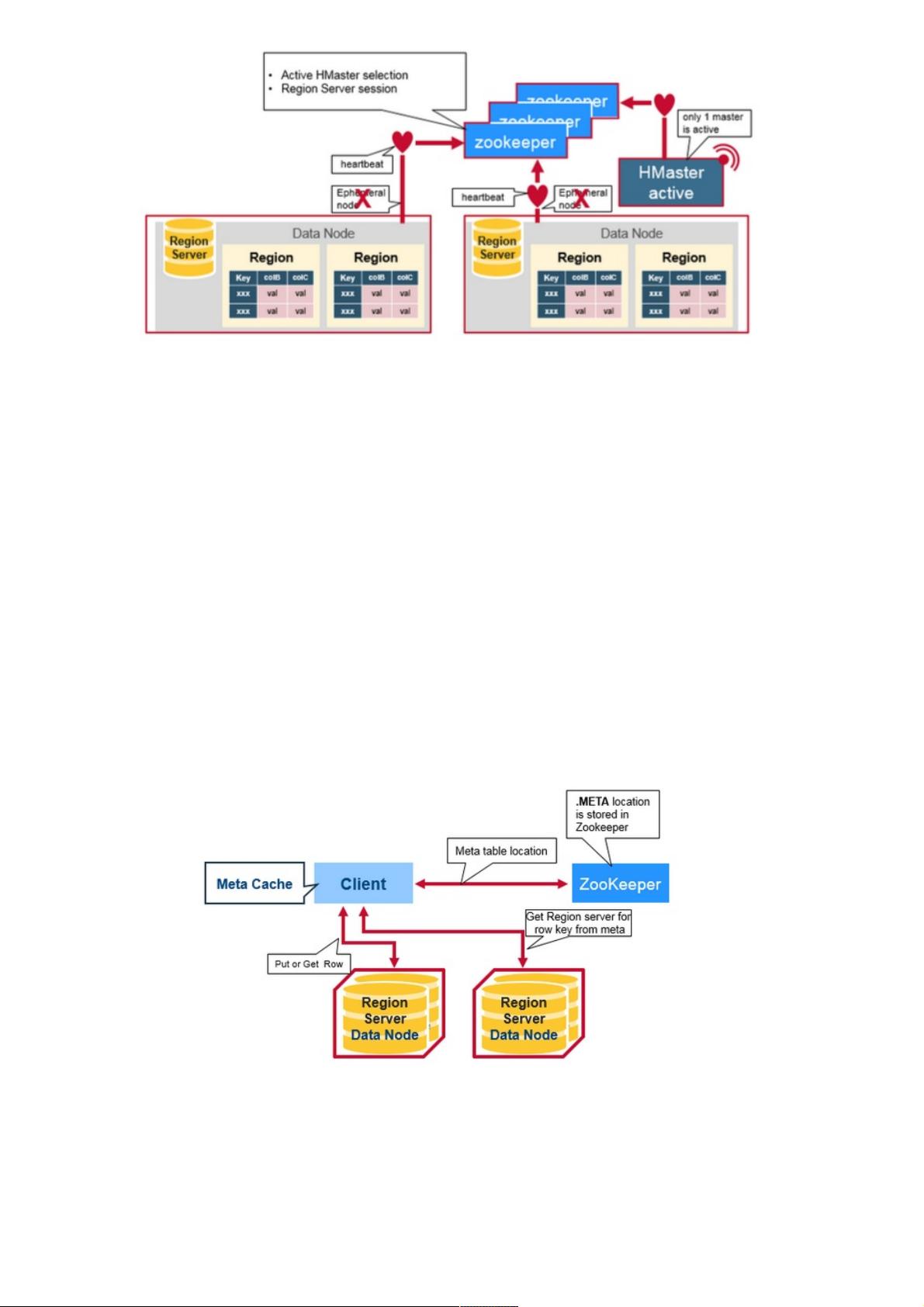
每个Region Server创建一个临时节点。HMaster监控这些节点以发现可用的region servers,并监控这些节点的服务器故障。
HMaster监控这些节点以发现可用的区域服务器,并监控这些节点的服务器故障。HMasters争夺创造一个短暂的节点。
Zookeeper确定第一个并使用它来确保只有一个主站处于活动状态。 活动HMaster将心跳发送到Zookeeper,非活动HMaster
将监听活动HMaster故障的通知。如果region server或者actice HMaster未能发送心跳信号,则会话过期并删除相应的临时节
点。Listeners的更新在收到节点删除的通知后。Active HMaster监听region servers,并在region servers出现故障时进行恢
复。Inactive HMaster监听active HMaster故障,并且如果active HMaster故障时,inactive HMaster编程active状态。
Base First Read or Write
HBase有一个叫做META的特殊的目录表,用于保存集群中regions的位置信息。Zookeeper存储着META表的位置。
以下是客户端第一次读取和写入HBase时发生的情况:
1.客户端从zookeeper中META Table的位置.
2.客户端查询.META。服务器获取客户端想要访问的并且是rowkey所相对应Region Server的信息。客户端会将META缓存带
本地。
3.从相应的Region Server获取行
在未来的读取操作过程中,客户端使用Meta Cache来检索META Table的位置和之前读取的Row Keys。随着时间的推移,不
再需要查询META table了,除非应为一个region转移而错过,那么它将重新查询并更新Meta Cache。
HBase Meta Table
1.META表是一个保存的了系统中所有region列表的HBase表。
2.META表就像一颗B—tree
3.METa的结构如下:
Key: region start key,region id
剩余11页未读,继续阅读
2018-11-11 上传
2019-04-18 上传
点击了解资源详情
2021-02-24 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38643127
- 粉丝: 8
- 资源: 921
 我的内容管理
展开
我的内容管理
展开







最新资源
- IEEE 14总线系统Simulink模型开发指南与案例研究
- STLinkV2.J16.S4固件更新与应用指南
- Java并发处理的实用示例分析
- Linux下简化部署与日志查看的Shell脚本工具
- Maven增量编译技术详解及应用示例
- MyEclipse 2021.5.24a最新版本发布
- Indore探索前端代码库使用指南与开发环境搭建
- 电子技术基础数字部分PPT课件第六版康华光
- MySQL 8.0.25版本可视化安装包详细介绍
- 易语言实现主流搜索引擎快速集成
- 使用asyncio-sse包装器实现服务器事件推送简易指南
- Java高级开发工程师面试要点总结
- R语言项目ClearningData-Proj1的数据处理
- VFP成本费用计算系统源码及论文全面解析
- Qt5与C++打造书籍管理系统教程
- React 应用入门:开发、测试及生产部署教程
