深度学习:3DCNN与卷积LSTM结合的手势识别
18 浏览量
更新于2024-08-28
7
收藏 690KB PDF 举报
"本文主要探讨了使用3DCNN(3D卷积神经网络)和卷积LSTM(Long-Short Term Memory)网络在手势识别中的应用,以学习和理解时空特征。作者通过构建深度架构,首先利用3DCNN捕获2D空间时间特征映射,再结合双向卷积LSTM来编码全局时间信息和局部空间信息。接着,通过2DCNN进一步学习这些2D特征映射中的高层时空特征,以实现最终的手势识别。这种深度架构保持了时空关联信息的完整性,从而提高了识别效率和准确性。"
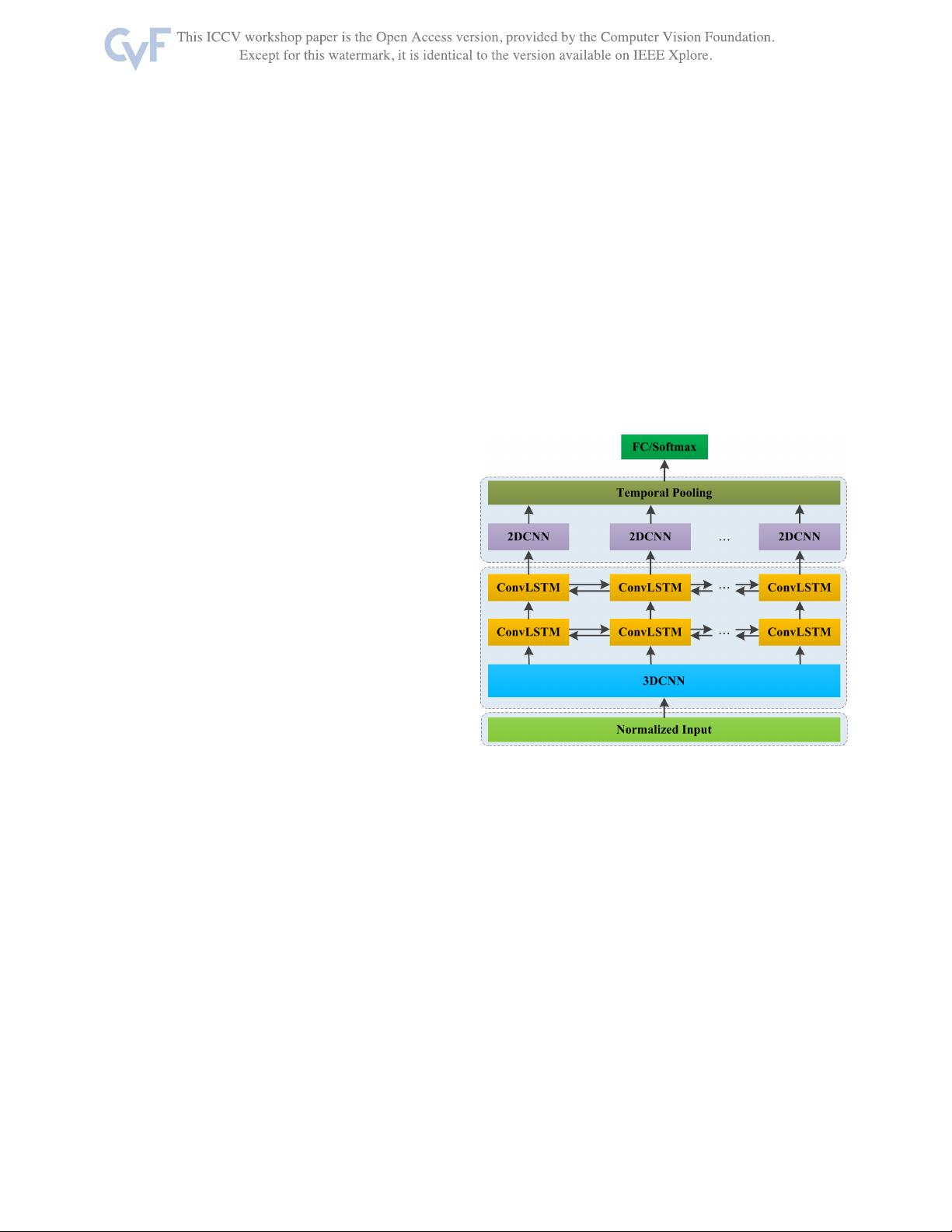
在手势识别领域,理解和解析人类正在进行的手势是一项关键任务。传统的机器学习方法往往难以捕捉到手势的动态变化和连续性,而深度学习尤其是3DCNN和LSTM网络的结合,为这一问题提供了新的解决方案。3DCNN是一种扩展了2D卷积神经网络的模型,其可以处理多维度的数据,如视频序列,有效地提取空间和时间上的特征。在本研究中,3DCNN被用来学习2D空间时间特征映射,这有助于捕捉手势的动态特性。
卷积LSTM则是在LSTM结构基础上加入了卷积操作,使其能够处理图像序列数据。双向卷积LSTM(Bidirectional ConvLSTM)进一步增强了这种能力,它可以从前后两个方向学习时间序列的信息,从而更好地捕捉手势的前后关联。这种双向性使得网络能够同时理解过去和未来的上下文,对于手势识别这类时序依赖的任务尤其有利。
2DCNN随后被用于从之前学习到的2D特征映射中提取更高级别的时空特征。这些高层特征通常包含了更多的抽象信息,有助于区分不同的手势模式。通过这样的多层次学习,网络能够逐步理解并建模手势的复杂时空结构,从而提高识别的准确性和鲁棒性。
在整个特征学习过程中,时空关联信息得以保留,这是该深度架构的核心优势。这种设计使得模型能够更好地理解和追踪手势的演变过程,减少误识别的可能性。因此,结合3DCNN和卷积LSTM的手势识别系统在实际应用中具有广阔前景,尤其适用于需要实时交互和高精度识别的场景,例如虚拟现实、智能机器人、人机交互等领域。
Learning Spatiotemporal Features using 3DCNN and Convolutional LSTM for
Gesture Recognition
Liang Zhang, Guangming Zhu, Peiyi Shen, Juan Song
School of Software, Xidian University
{liangzhang, gmzhu, pyshen, songjuan}@xidian.edu.cn
Syed Afaq Shah, Mohammed Bennamoun
University of Western Australia
{afaq.shah, mohammed.bennamoun}@uwa.edu.au
Abstract
Gesture recognition aims at understanding the ongoing
human gestures. In this paper, we present a deep archi-
tecture to learn spatiotemporal features for gesture recog-
nition. The deep architecture first learns 2D spatiotempo-
ral feature maps using 3D convolutional neural networks
(3DCNN) and bidirectional convolutional long-short-term-
memory networks (ConvLSTM). The learnt 2D feature maps
can encode the global temporal information and local spa-
tial information simultaneously. Then, 2DCNN is utilized
further to learn the higher-level spatiotemporal features
from the 2D feature maps for the final gesture recogni-
tion. The spatiotemporal correlation information is kept
through the whole process of feature learning. This makes
the deep architecture an effective spatiotemporal feature
learner. Experiments on the ChaLearn LAP large-scale iso-
lated gesture dataset (IsoGD) and the Sheffield Kinect Ges-
ture (SKIG) dataset demonstrate the superiority of the pro-
posed deep architecture.
1. Introduction
Gestures, as a nonverbal body language, play a very
important role in humans daily life. Gesture recognition
aims at understanding the ongoing human gestures and is
of great significance for human-robot/computer interaction,
sign language recognition and virtual [23].
Effective and universal gesture recognition from videos
is extremely difficult; partly due to the large gesture vocab-
ularies with cultural differences, various illumination con-
ditions, out-of-vocabulary motions, inconsistent and non-
standard behaviors among different performers, etc [12].
Moreover, gestures have various time durations and involve
different body parts. A small handful of gestures can be
Figure 1. Overview of the proposed deep architecture. 3DCNN
and bidirectional ConvLSTM are utilized to learn the short-
term and long-term spatiotemporal features successively, and then
2DCNN is used to learn higher-level spatiotemporal features based
on the learnt 2D long-term spatiotemporal feature maps for the fi-
nal gesture recognition.
represented by a single posture of hands and arms, but most
of the gestures are composed of a sequence of hand and arm
postures. Therefore, learning effective spatiotemporal fea-
tures is crucially important for robust gesture recognition.
According to [32], there are four typical properties for ef-
fective spatiotemporal features of gestures: (i) generic, (ii)
compact, (iii) efficient to compute, and (iv) simple to imple-
ment.
Inspired by the deep learning breakthroughs in image
recognition [17, 29, 31], lots of neural network based
frameworks are proposed to learn spatiotemporal features
3120
下载后可阅读完整内容,剩余8页未读,立即下载
2021-05-07 上传
2020-06-21 上传
2022-02-06 上传
2021-05-15 上传
点击了解资源详情
2021-06-13 上传
2018-08-31 上传
2024-06-01 上传

weixin_38608866
- 粉丝: 7
- 资源: 915
 我的内容管理
展开
我的内容管理
展开







最新资源
- Sentinel-1.8.1
- GU620:毕设-----在MODBUS协议下android与控制器GU620的通信
- Perthon Python-to-Perl Source Translator-开源
- dev-portfolio
- CourseaHTML
- URL缩短器:使用JavaScript,Node.js,MongoDB和Express的URL缩短器
- 【Java毕业设计】java毕业设计,ssm毕业设计,在线考试管理系统,源码带论文.zip
- dbR:数据库和R
- CaptainsBacklog:Scrum开发人员培训
- Android-Network-Service-Discovery:Android NSD 易学项目..
- quynhhgoogoo:描述
- maven-hadoop-java-wordcount-template:这是一个 Maven Hadoop Java 项目模板。 这个样板框架代码包含一个 Driver、一个 Mapper 和一个 Reducer,可以用你的代码修改(它们包含经典的 wordcount 示例)
- 【Java毕业设计】java 基于Spring Boot2.X的后台权限管理系统,适合于学习Spring Boot开.zip
- python实例-14 名言查询.zip源码python项目实例源码打包下载
- Book_Search
- dictionary-project
