网络爬虫与图论遍历:防止环路策略解析
需积分: 0 35 浏览量
更新于2024-08-04
收藏 242KB DOCX 举报
"本文主要介绍了爬虫搜索策略中的防止环路问题,以及互联网的图论表示和爬虫工作原理。内容涉及如何通过遍历算法抓取网页,避免重复下载,并探讨了大型网络爬虫系统的设计挑战。此外,还提到了网站的树结构,以知乎的URL层次为例进行说明。"
在爬虫技术中,防止环路的出现至关重要,因为网站的URL链接通常存在环路,即上一级页面可能链接回下一级页面。这可能导致爬虫陷入无尽的循环,浪费资源且无法高效地抓取数据。为解决这个问题,爬虫会利用各种搜索策略,如深度优先搜索(DFS)和广度优先搜索(BFS),同时配合数据结构,如哈希表来记录已访问的网页,确保不会重复下载。
深度优先搜索从一个网页出发,沿着链接一直深入到分支的末端,然后再回溯,而广度优先搜索则是先遍历当前层级的所有网页,再进入下一层。哈希表因其高效的查找和插入性能,成为记录已访问网页的理想工具。当爬虫遇到新URL时,会首先检查哈希表,如果URL已经在表中,就跳过;若不在,则添加到表中并进行下载。
互联网可以视为一张由网页作为节点、超链接作为边的巨大图。网络爬虫通过模拟点击超链接,实现图的遍历,从而遍历整个网络。早期的网络爬虫如“互联网漫游者”相对简单,但现代的网络爬虫如Google的爬虫,需要处理的数据量极其庞大,需要成千上万台服务器协同工作,这涉及到分布式系统的设计和优化,包括任务调度、网络通信效率、存储管理和负载均衡等问题。
以网站的树结构为例,如知乎的URL层次,通常表现为多个主分类(如发现、话题、Live等)下有多个子分类或具体页面。这种结构有利于爬虫按照一定的逻辑顺序进行抓取,减少环路出现的可能性。然而,实际的网站结构可能更为复杂,可能包含隐藏链接、动态加载内容等,这要求爬虫具备处理各种网页结构的能力。
爬虫在抓取网站时,既要保证全面性,又要避免重复和环路,这需要巧妙地结合图论算法和数据结构,以及对大规模分布式系统的深入理解。同时,对于网站结构的理解和利用,也是提高爬虫效率的关键。
爬虫搜索策略-防止环路的出现:
现在看看图论的遍历算法和搜索引擎的关系。互联网虽然很复杂,但是说穿
了其实就是一张大图而已一可以把每一个网页当作一个节点,把那些超链接
(Hyperlinks )当作连接网页的弧。网页中那些蓝色、带有下划线的文字背后其
实藏着对应的网址,当你点击的时候,浏览器通过这些隐含的网址跳转到相应的
网页。这些隐含在文字背后的网址称为”超链接”。有了超链接,我们可以从任
何一个网页出发,用图的遍历算法,自动地访问到每一个网页并把它们存起来。
完成这个功能的程序叫做网络爬虫( Web Crawlers ).或者在一些文献中称为“机
器人”( Robot)。世界上第一个网络爬虫是由麻省理工学院的学生马休·格雷
( Matthew Gray)在 1993 年写成的。他给自己的程序起了个名字叫“互联网漫游
者,(WWW Wanderer)。以后的网络爬虫越写越复杂。但原理是一样的。
我们来看看网络爬虫如何下载整个互联网。假定从一家门户网站的首页出发。
先下载这个网页,然后通过分析这个网页,可以找到页面里的所有超链接。也就
等于知道了这家门户网站首页所直接链接的全部网页,诸如雅虎邮件、雅虎财经、
雅虎新闻等。接下来访向、下载并分析这家门户网站的邮件等网页,又能找到其
他相连的网页。让计算机不停地做下去,就能下载整个的互联网。当然,也要记
载哪个网页下载过了,以免重复。在网络爬虫中,使用一个称为“哈希表”( Hash
Table )的列表而不是一个记事本记录网页是否下载过的信息。
现在的互联网非常庞大,不可能通过一台或几台计算机服务器就能完成下载任务。
比如 Google 在 2010。年时整个的索引大小大约有 S 000 亿个网页,即使更新最
频繁的基础索引也有 100 亿个网页,假如下载一个网页需要一秒钟,下载这 100
亿个网页则需要 317 年,如果下载 5 000 亿个网页则需要 16 000 年左右,是我
们人类有文字记载历史的三倍时间。因此,一个商业的网络爬虫需要有成千上万
台服务器,并且通过高速网络连接起来。如何建立起这样复杂的网络系统,如何
协调这些服务器的任务,就是网络设计和程序设计的艺术了。
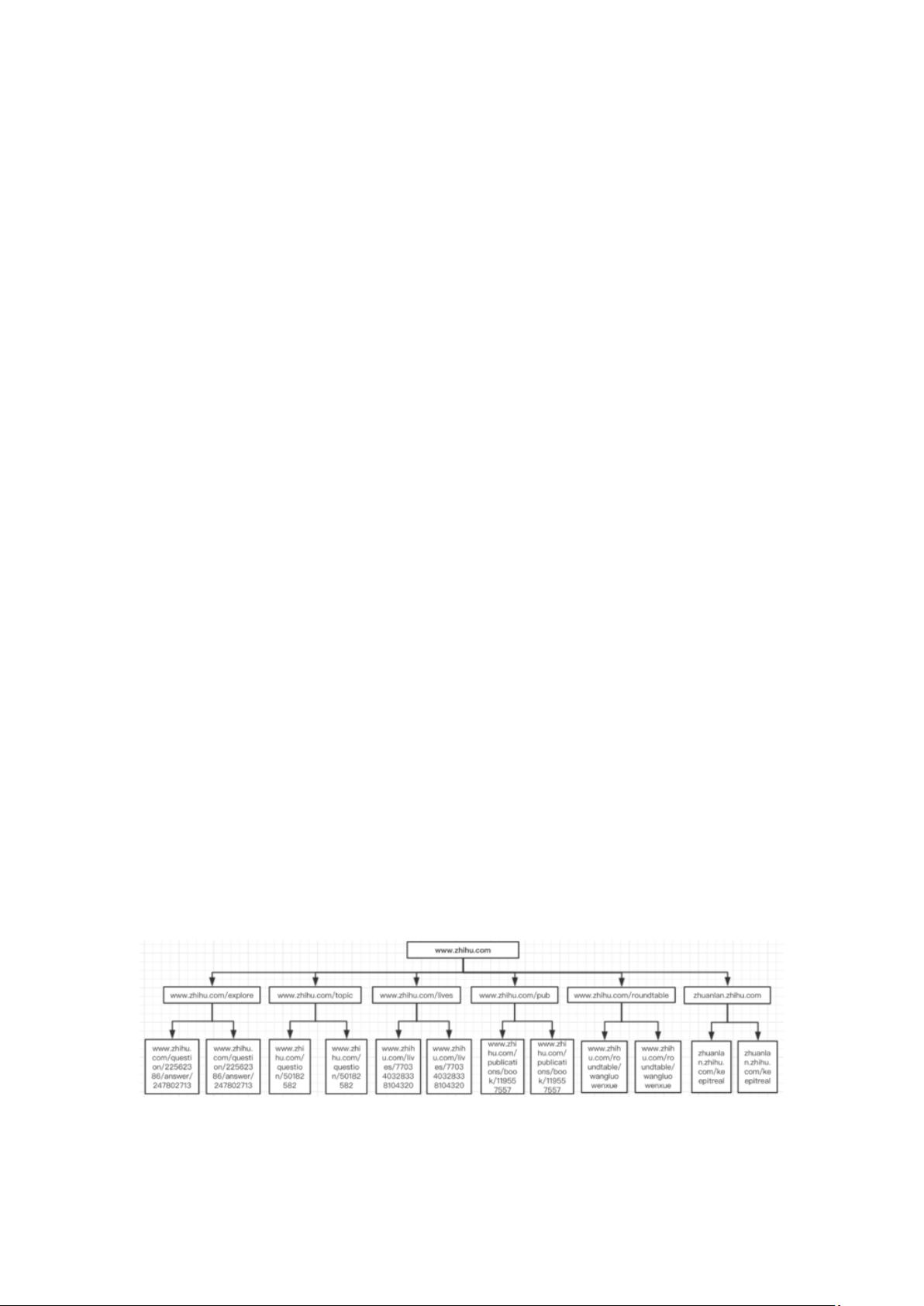
2.4.1 网站的树结构
1、一个网站的 URL 结构图
以知乎为例,知乎目前有发现、话题、Live、书店、圆桌、专栏主要的 6 个 tab
页。每个网站的 url 都是有一定的层次,如下图:发现 explore、话题 topic、Live
lives、书店 pub、圆桌 roundtable、专栏 zhuanlan 都是在主域名 zhihu 的下一
级 , 而 具 体 的 Live 在 …/67006058/answer 内 容 又 在 话 题 之 下
zhihu/question/67006058/answer/250037350,网站的所有内容都一层一层的类
似一个树形结构。
2、网站 URL 链接的结构图
当然,如果我们要做爬取整个网站的 url 时,我们必须要知道每个网站的 url 链
下载后可阅读完整内容,剩余3页未读,立即下载
2022-08-08 上传
2022-04-02 上传
2022-03-12 上传
2021-09-14 上传
2024-10-18 上传
2024-08-27 上传
2022-03-24 上传

芊暖
- 粉丝: 28
- 资源: 339
 我的内容管理
展开
我的内容管理
展开







最新资源
- Raspberry Pi OpenCL驱动程序安装与QEMU仿真指南
- Apache RocketMQ Go客户端:全面支持与消息处理功能
- WStage平台:无线传感器网络阶段数据交互技术
- 基于Java SpringBoot和微信小程序的ssm智能仓储系统开发
- CorrectMe项目:自动更正与建议API的开发与应用
- IdeaBiz请求处理程序JAVA:自动化API调用与令牌管理
- 墨西哥面包店研讨会:介绍关键业绩指标(KPI)与评估标准
- 2014年Android音乐播放器源码学习分享
- CleverRecyclerView扩展库:滑动效果与特性增强
- 利用Python和SURF特征识别斑点猫图像
- Wurpr开源PHP MySQL包装器:安全易用且高效
- Scratch少儿编程:Kanon妹系闹钟音效素材包
- 食品分享社交应用的开发教程与功能介绍
- Cookies by lfj.io: 浏览数据智能管理与同步工具
- 掌握SSH框架与SpringMVC Hibernate集成教程
- C语言实现FFT算法及互相关性能优化指南
