智能交通系统中的交通流量预测技术综述
"这篇论文是关于交通流量预测的综合调查,涵盖了近年来的研究进展,方法分类,应用领域及其最新状态,并提供了公开数据集的收集与评估。"
交通流量预测是智能交通系统中的关键环节,它对路线规划、车辆调度以及缓解交通拥堵具有重要作用。由于道路上不同区域间复杂且动态的空间时间依赖性,交通流量预测问题显得尤为挑战性。近年来,众多研究致力于解决这一问题,显著提升了预测能力。
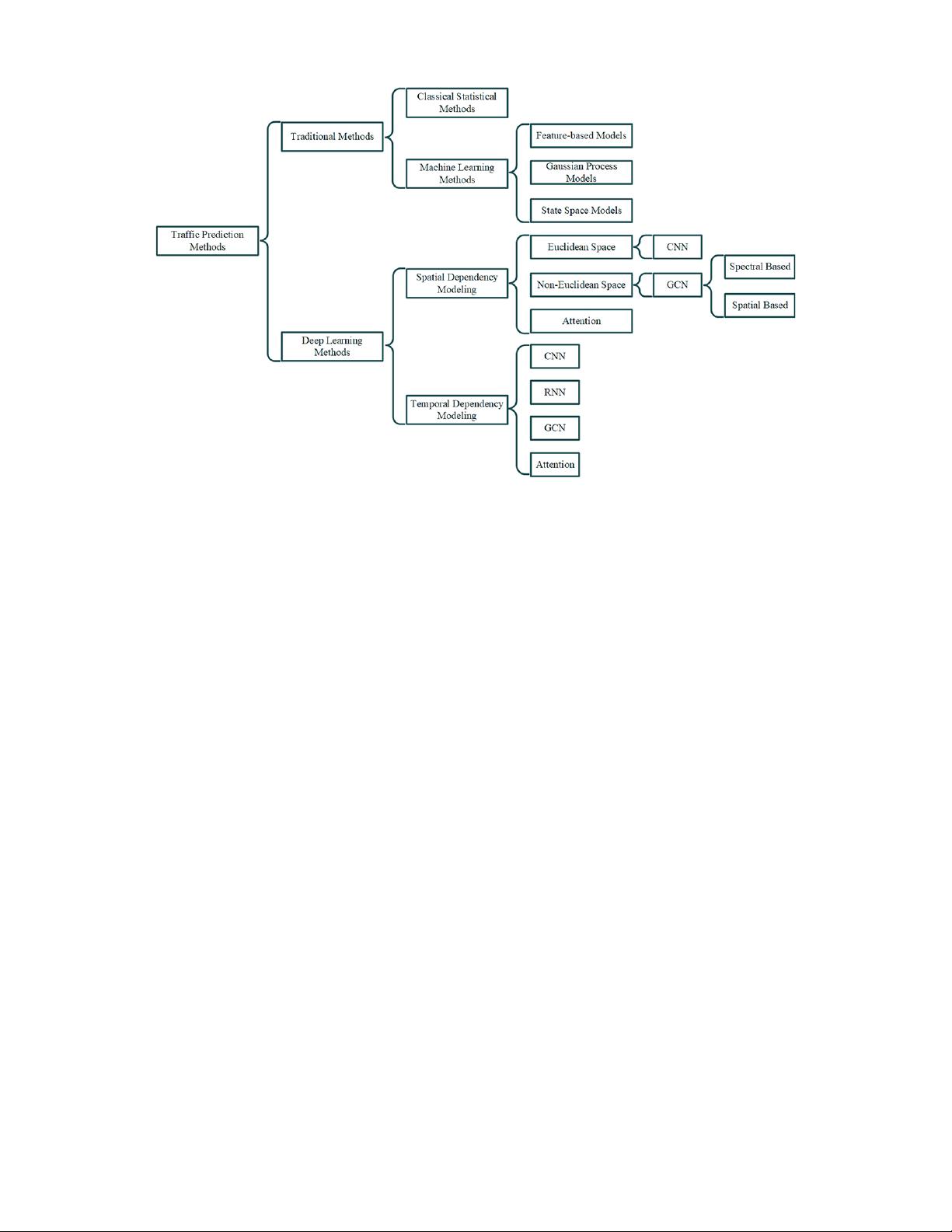
首先,论文总结了现有的交通流量预测方法。这些方法可能包括传统的统计模型(如时间序列分析、线性回归等),基于机器学习的方法(如支持向量机、随机森林、神经网络等),以及近年来随着大数据和人工智能技术的发展而兴起的深度学习方法(如卷积神经网络、循环神经网络、时空卷积网络等)。这些模型试图捕捉交通流量的时空模式,以提高预测的准确性和鲁棒性。
其次,论文列举了交通预测在多个领域的应用,如交通管理、城市规划、紧急服务响应、公共交通调度等。每个领域的最新进展也被详尽阐述,展示出在实时交通信息、交通拥堵预警、出行建议等方面的创新应用。
此外,论文还收集并组织了一系列公开的交通数据集,这些数据集通常包含交通流量、速度、占用率等多种信息,为研究者提供了实验平台,以便比较和验证不同的预测模型性能。例如,论文可能会比较基于交通需求预测和基于速度预测的不同方法在两个数据集上的表现。
最后,通过广泛的实验,论文对相关方法进行了性能评估。这些实验不仅检验了模型的预测精度,还可能考虑了模型的计算效率、泛化能力和对异常情况的处理能力。这些实证研究为未来的研究提供了指导,有助于进一步推动交通流量预测技术的进步。
这篇论文为交通流量预测领域的研究者和实践者提供了一个全面的参考框架,梳理了当前的研究热点和挑战,并为后续研究指明了方向。通过深入理解这些方法和应用,可以更好地应对实际交通系统中的复杂问题,提升交通系统的智能化水平。
3
Fig. 2. Categories of traffic prediction methods.
average (ARIMA) [88] and its variants are one of the most
consolidated approaches based on classical statistics and have
been widely applied for traffic prediction problems ( [1], [48],
[58], [64], [73], [82], [88] ). However, these methods are gen-
erally designed for small datasets, and are not suitable to deal
with complex and dynamic time series data. In addition, since
usually only temporal information is considered, the spatial
dependency of traffic data is ignored or barely considered.
Machine learning methods, which can model more complex
data, are broadly divided into three categories: feature-based
models, Gaussian process models and state space models.
Feature-based methods solve traffic prediction problem ( [28],
[47] ) by training a regression model based on human-
engineered traffic features. These methods are simple to
implement and can provide predictions in some practical
situations. Despite this feasibility, feature-based models have
a crucial limitation: the performance of the model depends
heavily on the human-engineered features. Gaussian process
models the inner characteristics of traffic data through different
kernel functions, which need to contain spatial and temporal
correlations simultaneously. Although this kind of method is
proved to be effective and feasible in traffic prediction ( [18],
[56], [71] ), they have higher computational load and storage
pressure, which is not appropriate when a mass of training
samples are available. State space models assume that the
observations are generated by Markovian hidden states. The
advantage of this model is that it can naturally model the
uncertainty of the system and better capture the latent structure
of the spatio-temporal data. However, the overall non-linearity
of these models ( [14], [15], [19], [26], [34], [35], [40], [69],
[75], [79], [98] ) is limited, and most of the time they are not
optimal for modeling complex and dynamic traffic data. Table I
summarizes some recent representative traditional approaches.
III. DEEP LEARNING METHODS
Deep learning models exploit much more features and
complex architectures than the traditional methods, and can
achieve better performance. They have been widely applied
in traffic prediction. In this section, we will review different
deep learning based traffic prediction methods in recent years
according to how they model spatio-temporal correlations.
A. Modeling Spatial Dependency
CNN. A series of studies have applied CNN to capture
spatial correlations in traffic networks from two-dimensional
spatio-temporal traffic data [51]. Since the traffic network is
difficult to be described by 2D matrices, several researches try
to convert the traffic network structure at different times into
images and divide these images into standard grids, with each
grid representing a region. In this way, CNNs can be used to
learn spatial features among different regions.
As shown in Fig. 3, each region is directly connected to its
nearby regions. With a 3×3 window, the neighborhood of each
region is its surrounding eight regions. The positions of these
eight regions indicate an ordering of a region’s neighbors. A
filter is then applied to this 3× 3 patch by taking the weighted
average of the central region and its neighbors across each
channel. Due to the specific ordering of neighboring regions,
the trainable weights are able to be shared across different
locations.
In the division of traffic road network structure, there are
many definitions of positions according to different granularity
and semantic meanings. [102] divided a city into I J grid maps
based on the longitude and latitude where a grid representd a
region. Then, a CNN was applied to extract the spatial corre-
lation between different regions for traffic flow prediction.
剩余14页未读,继续阅读
2022-04-18 上传
2023-07-17 上传
2021-08-20 上传
2021-10-08 上传
2024-04-10 上传
2022-05-28 上传
2023-07-06 上传
2024-03-09 上传

syp_net
- 粉丝: 158
- 资源: 1187
 我的内容管理
展开
我的内容管理
展开







最新资源
- Java毕业设计项目:校园二手交易网站开发指南
- Blaseball Plus插件开发与构建教程
- Deno Express:模仿Node.js Express的Deno Web服务器解决方案
- coc-snippets: 强化coc.nvim代码片段体验
- Java面向对象编程语言特性解析与学生信息管理系统开发
- 掌握Java实现硬盘链接技术:LinkDisks深度解析
- 基于Springboot和Vue的Java网盘系统开发
- jMonkeyEngine3 SDK:Netbeans集成的3D应用开发利器
- Python家庭作业指南与实践技巧
- Java企业级Web项目实践指南
- Eureka注册中心与Go客户端使用指南
- TsinghuaNet客户端:跨平台校园网联网解决方案
- 掌握lazycsv:C++中高效解析CSV文件的单头库
- FSDAF遥感影像时空融合python实现教程
- Envato Markets分析工具扩展:监控销售与评论
- Kotlin实现NumPy绑定:提升数组数据处理性能
