全面解析:聚类分析与应用
需积分: 15 124 浏览量
更新于2024-08-02
收藏 6.86MB PDF 举报
"Clustering是关于聚类分析的首部全面性著作,涵盖了从基础到高级的各种聚类方法,包括但不限于亲和度度量、层次聚类、分区聚类、基于神经网络的聚类、基于核的聚类、序列数据聚类、大规模数据聚类、数据可视化、高维数据聚类以及聚类验证。本书适合不同水平和背景的读者,无需先前的聚类知识,通过丰富的实例和引用使得复杂的主题变得易于理解。由IEEE Press出版,并得到IEEE计算智能学会赞助。"
聚类(Clustering)是数据挖掘和机器学习领域中的核心概念,它是一种无监督学习方法,目的是将相似的数据分组到一起,形成所谓的“簇”(clusters)。这个过程可以帮助我们发现数据中的内在结构,揭示未知的模式和关系,而不依赖于预先定义的类别或标签。
标题中提到的"Clustering"是指聚类分析的整体研究,这一领域广泛应用于各种场景,如市场细分、生物信息学、社交网络分析等。描述中指出,本书从基础开始介绍聚类,逐步深入到各种方法和技术:
1. **亲和度度量**(Proximity Measures):这是衡量数据点之间相似性的关键,常见的度量有欧氏距离、曼哈顿距离、余弦相似度等。
2. **层次聚类**(Hierarchical Clustering):分为凝聚型和分裂型,通过构建一个层次树(Dendrogram)来展示数据的聚类关系。
3. **分区聚类**(Partition Clustering):如K-means算法,预先设定簇的数量,通过迭代优化分配每个数据点到最近的簇中心。
4. **基于神经网络的聚类**:利用神经网络的并行处理能力和学习能力进行聚类,例如自组织映射(SOM)。
5. **基于核的聚类**(Kernel-based Clustering):通过核函数将数据映射到高维空间,以便在原始空间中难以区分的数据在新空间中变得可分。
6. **序列数据聚类**(Sequential Data Clustering):针对时间序列或顺序数据的聚类,考虑数据点的顺序关系。
7. **大规模数据聚类**:处理大数据集的聚类算法,如分布式或近似方法,以应对内存限制和计算效率问题。
8. **数据可视化**:通过图形表示帮助理解聚类结果,如散点图、热力图等。
9. **高维数据聚类**:在高维空间中聚类面临“维度灾难”,需要采用降维技术如主成分分析(PCA)或其他特定的聚类策略。
10. **聚类验证**:评估聚类质量的过程,包括内部和外部验证指标,如轮廓系数、Calinski-Harabasz指数等。
书中还提到了这本书由IEEE Press出版,这是一家知名的技术出版社,其出版的系列书籍专注于计算智能,这表明该书具有权威性和专业性。此外,还得到了IEEE计算智能学会的赞助,该学会是全球领先的计算智能研究和应用的专业组织。
"Clustering"这本书提供了对聚类分析全面而深入的洞察,对于想要学习和理解这一领域的读者来说,是一份宝贵的资源。通过阅读此书,读者可以掌握聚类的核心概念,熟悉各种聚类方法,并有能力应用这些知识解决实际问题。
6 CLUSTER ANALYSIS
on the discussion of feature extraction in Chapter 9 in the context of data
visualization and dimensionality reduction. Feature selection is more
often used in the context of supervised classifi cation with class labels
available (Jain et al., 2000 ; Sklansky and Siedlecki, 1993 ). Jain et al.
(2000) , Liu and Yu (2005) , and Theodoridis and Koutroumbas (2006) all
provided good reviews of the feature selection techniques for supervised
learning. A method of simultaneous feature selection and clustering,
under the framework of fi nite mixture models, was proposed in Law
et al. (2004) . Kim et al. (2000) employed the genetic algorithm for feature
selection in a K - means algorithm. Mitra et al. (2002) introduced a
maximum information compression index to measure feature similarity
and examine feature redundancy. More discussions on feature selection
in clustering were given in Dy and Brodley (2000) , Roth and Lange
(2004) , and Talavera (2000) .
2. Clustering algorithm design or selection . This step usually consists of
determining an appropriate proximity measure and constructing a crite-
rion function. Intuitively, data objects are grouped into different clusters
according to whether they resemble one another or not. Almost all clus-
tering algorithms are explicitly or implicitly connected to some particular
defi nition of proximity measure. Some algorithms even work directly on
the proximity matrix, as defi ned in Chapter 2 . Once a proximity measure
is determined, clustering could be construed as an optimization problem
with a specifi c criterion function. Again, the obtained clusters are depen-
dent on the selection of the criterion function. The subjectivity of cluster
analysis is thus inescapable.
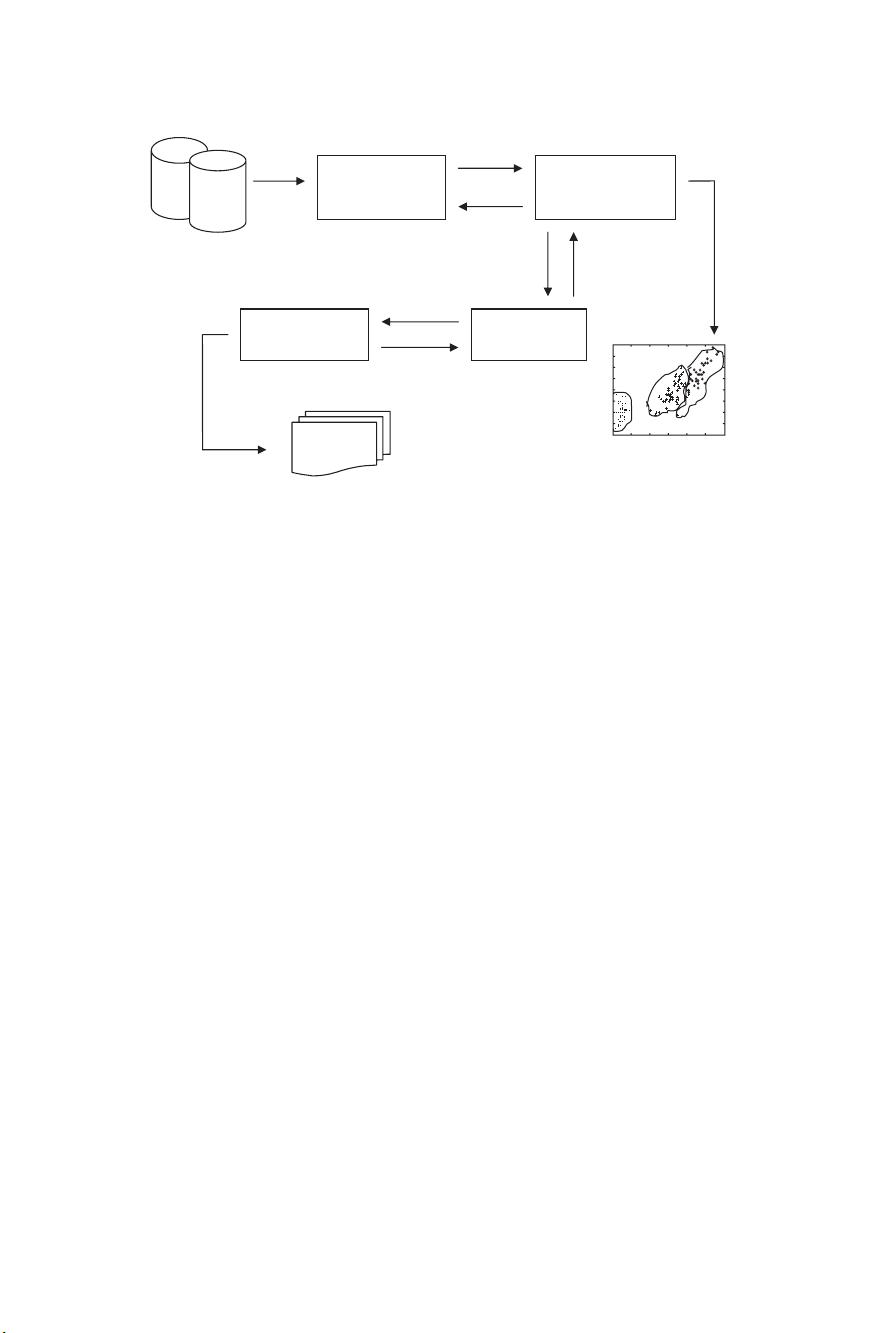
Data
Samples
Feature
Selection or
Extraction
Clustering
Algorithm Design
or Selection
Cluster
Validation
Result
Interpretation
Knowledge
Clusters
Fig. 1.2. Clustering procedure. The basic process of cluster analysis consists of four
steps with a feedback pathway. These steps are closely related to each other and deter-
mine the derived clusters.



剩余363页未读,继续阅读
333 浏览量
476 浏览量
167 浏览量
324 浏览量
2021-10-02 上传
116 浏览量
171 浏览量

xuxm2007
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- Ruby语言集成Mandrill API的gem开发
- 开源嵌入式qt软键盘SYSZUXpinyin可移植源代码
- Kinect2.0实现高清面部特征精确对齐技术
- React与GitHub Jobs API整合的就业搜索应用
- MATLAB傅里叶变换函数应用实例分析
- 探索鼠标悬停特效的实现与应用
- 工行捷德U盾64位驱动程序安装指南
- Apache与Tomcat整合集群配置教程
- 成为JavaScript英雄:掌握be-the-hero-master技巧
- 深入实践Java编程珠玑:第13章源代码解析
- Proficy Maintenance Gateway软件:实时维护策略助力业务变革
- HTML5图片上传与编辑控件的实现
- RTDS环境下电网STATCOM模型的应用与分析
- 掌握Matlab下偏微分方程的有限元方法解析
- Aop原理与示例程序解读
- projete大语言项目登陆页面设计与实现
