Scale-RS:一种高效的Reed-Solomon存储集群扩展方案
需积分: 10 132 浏览量
更新于2024-09-09
收藏 1.28MB PDF 举报
"Scale-RS是针对Reed-Solomon编码存储集群的一种高效扩展方案,旨在满足存储容量和I/O性能增长的需求。"
Reed-Solomon(RS)码是一种纠错编码技术,广泛应用于数据存储系统中,因为它能够在数据丢失或损坏时恢复信息。在大型存储集群中,随着数据量的增长和性能需求的提升,对RS编码存储集群进行扩展变得至关重要。Scale-RS正是为此设计的一种创新方法,它具备三个主要特性。
首先,Scale-RS实现了数据的均匀分布。通过使用转置数据布局,Scale-RS能够将数据块平均分配到新旧数据块之间。这种策略确保了新加入的存储节点能平滑地融入现有系统,避免了数据过于集中在某些特定节点的情况,从而提高了系统的稳定性和可靠性。
其次,Scale-RS在数据重新分布和校验更新的过程中最小化了数据移动。它不仅通过仅转移旧数据块到新数据块的必要数据块达到了数据迁移流量的下限,而且还通过从单个数据块中存储的数据块生成校验差异块来减少更新流量。这样既节省了网络带宽,又降低了数据处理延迟。
第三,Scale-RS提升了扩展后存储集群的I/O性能。在读取并行性方面,由于数据分布更加均匀,多个客户端可以同时访问更多的数据块,从而加速了数据读取。而在写入吞吐量方面,优化的数据处理机制减少了写入操作中的瓶颈,使得大规模写入操作更加高效。
除了Scale-RS,该研究还实现并比较了两种替代的扩展策略。这三种方案的对比分析有助于深入理解在RS编码存储集群扩展中的最佳实践,为未来的设计提供了有价值的参考。
Scale-RS是一种高效且实用的解决方案,它通过优化数据分布、减少数据移动以及提升I/O性能,有效地解决了RS编码存储集群在扩展过程中遇到的挑战。这对于构建大规模、高性能的云存储服务具有重要的实际意义,能够帮助数据中心应对日益增长的存储需求和性能压力。
migration occurs. Although an alternative RAID-4 scaling
scheme can reduce the number of data blocks to be moved
by migrating certain blocks to newly added disks [31], the
RAID-4 scaling scheme suffers from a very expensive cost
of parity updates during new data filling. Traditional
RAID-5 scaling schemes are based on round-robin layout. If
these RAID-5 scaling schemes are deployed in RS-coded
storage clusters, then the clusters will inevitably encounter
high I/O overhead incurred by data migrations and parity
updates. The parity layout of each RAID-6 code is unique;
RAID-6 scaling techniques designed for a specific RAID-6
code are inadequate for RS-coded storage clusters. In short,
there is a wide application gap between RAID scaling
schemes and cluster scaling.
In this study, we design an efficient cluster scaling
scheme called Scale-RS, which exploits the structural prop-
erties of erasure codes to optimize both data migrations and
parity updates. Scale-RS not only makes the total number of
moved data blocks equal to the lower bound of data migra-
tion traffic, but it also minimizes the data movement
induced by parity updates.
1.4 Roadmap
The remainder of this paper is organized as follows.
Section 2 summarizes the preliminaries of this study. The
design of Scale-RS is detailed in Section 3. Section 4
describes the experimental settings and results. Section 5
surveys the related work of storage scaling schemes. Sec-
tion 6 discusses implementation issues. Finally, we con-
clude our work in Section 7.
2PRELIMINARIES
Recognizing that RS codes are widely deployed in in-pro-
duction storage systems (see Table 1), we investigate scaling
schemes for RS-coded storage clusters in this study.
2.1 Update Penalty in RS-Coded Storage Clusters
There is an update penalty issue in erasure-coded storage
systems [37], [10], [38]—modifying any data block leads to
updates of corresponding parity blocks. There exist two
updating methods, namely, reconstruction write (a.k.a.,
RCW) [39] and read-modify-write (a.k.a., RMW) [40]. In the
‘RMW’ updating method, parity block P
row;j
in parity chunk
PC
j
is updated to P
row;j
þ DP
row;j
when data block D
row;i
in
data chunk DC
i
is changed to D
0
row;i
, where parity difference
block DP
row;j
equals to a
j;i
(D
0
row;i
D
row;i
), and coefficient a
j;i
denotes an element at the jth row and the ith row of a
redundancy matrix.
In cluster scaling
<k!kþDk>
, all r parity chunks should be
updated when Dk new data chunks join a (k þr, k) RS-
coded chunk group. If Round-Robin method [26], [34] is
adopted, almost all data blocks will be migrated, and all
parity blocks must be regenerated using the encoding pro-
cedure. Therefore, we should consider the following two
issues when designing the Scale-RS scheme: (1) how to min-
imize the number of migrated data blocks, and (2) how to
reduce the data movement induced by parity updates.
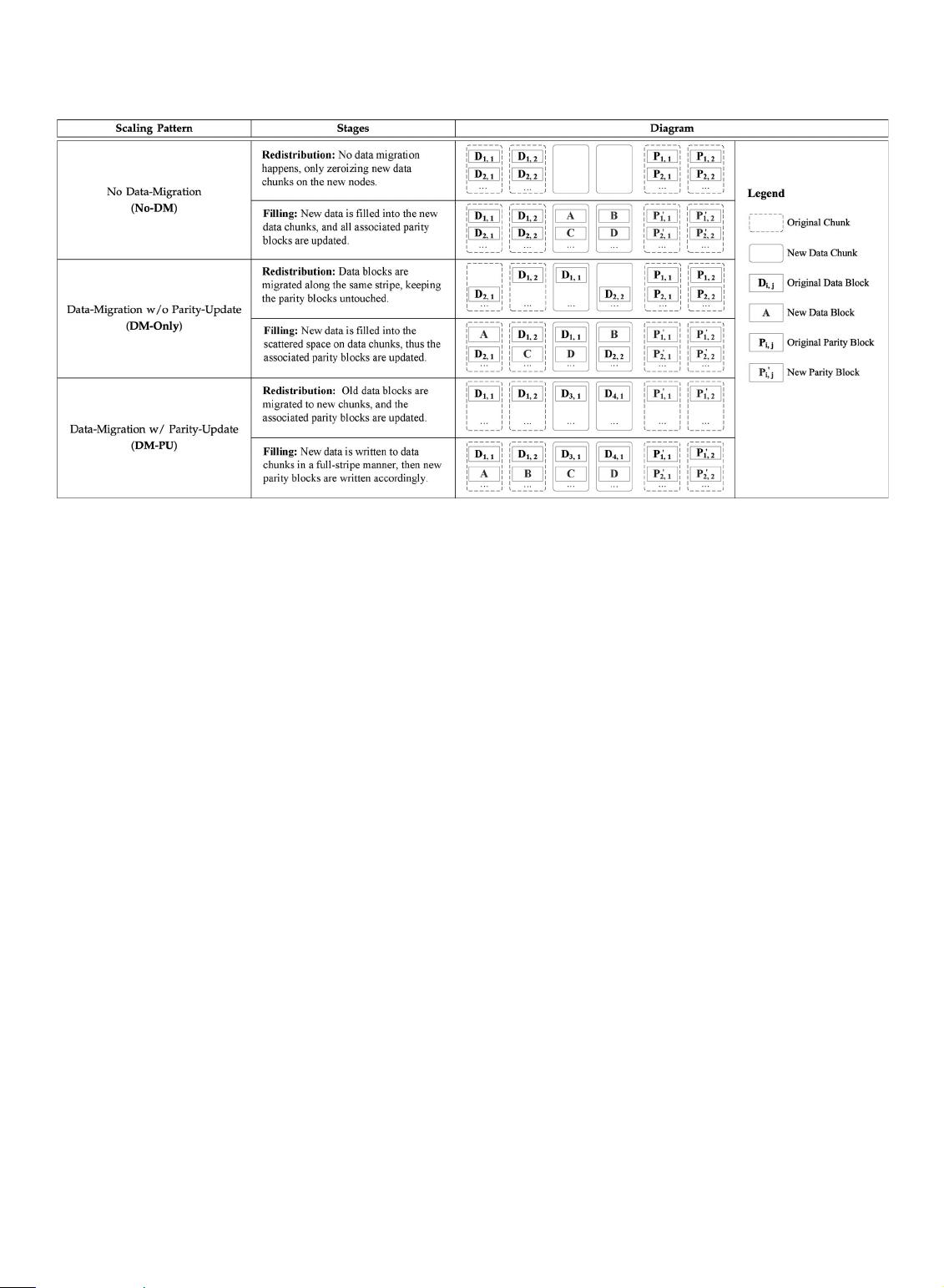
2.2 Categories of Cluster Scaling
One cluster scaling process can be logically divided into two
stages: data redistribution and data filling. Data redistribu-
tion is a composite operation—apart from migrating data
blocks, all associated parity blocks should be updated
accordingly. Therefore, there exist the following three clus-
ter-scaling patterns from a methodological point of view
(see Table 2):
(1) No Data-Migration (No-DM). No data migration is
involved in the No-DM-based scaling scheme, which only
places Dk new nodes into a storage cluster, resulting in zero
migration overhead. In the data filling stage, new data is
filled into new chunks and associated parity blocks are
updated.
TABLE 2
Scaling Categories of Erasure-Coded Chunk Groups
1706 IEEE TRANSACTIONS ON PARALLEL AND DISTRIBUTED SYSTEMS, VOL. 26, NO. 6, JUNE 2015
剩余13页未读,继续阅读
108 浏览量
2024-05-24 上传
2021-02-17 上传
2022-04-16 上传
2022-05-23 上传
2022-04-16 上传
2022-05-23 上传

Texmod
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- 普天身份证阅读器新版二次开发包发布
- C# 实现文件的数据库保存与导出操作
- CkEditor增强功能:轻松实现图片上传
- 掌握DLL注入技术:测试工具使用与探索
- 实现带节假日农历功能的jQuery日历选择器
- Spring循环依赖示例:深入理解与Git代码仓库实践
- ABB PLC液压阀门控制程序开发指南
- 揭秘4核旋风密版626象棋引擎的超牛实力
- HTML5实现的经典游戏:小霸王坦克大战源码分享
- 让Visual Studio兼容APM硬件信息的方法
- Kotlin入门:创建我的第一个应用
- Android语音识别技术研究报告与应用分析
- 掌握JavaScript基础:第8版教程源代码解析
- jQuery制作动态侧面浮动图片广告特效教程
- Android PinView仿支付宝密码输入框源码分析
- HTML5 Canvas制作的围住神经猫游戏源码分享
