深挖OpenStack:代码之旅与挑战
151 浏览量
更新于2024-08-28
收藏 604KB PDF 举报
"这篇文章探讨了作者在理解和学习OpenStack过程中遇到的挑战,强调了OpenStack的复杂性以及需要广泛的知识背景。作者通过阅读代码来理解OpenStack,特别是追踪虚拟机创建的流程,并引用了一篇关于OpenStack实例供应请求流程的文章。文章提到了OpenStack社区的活跃,以及由此产生的众多模块和插件,例如Telemetry、Orchestration、DatabaseService等,但作者决定专注于IaaS层面,只使用开源的KVM和LVM。"
在OpenStack的世界里,想要深入理解并掌握它并非易事。OpenStack是一个庞大的开源云操作系统平台,用于构建私有云和公有云服务,其核心在于提供基础设施即服务(IaaS)。系统由多个相互协作的组件组成,包括Keystone(身份管理)、Nova(计算)、Glance(镜像服务)、Neutron(网络)、Cinder(块存储)等。这些组件共同工作,以实现云计算的各种功能。
作者指出,试图通过阅读源代码来理解OpenStack的运行机制是一个明智但艰巨的任务,因为OpenStack的代码库庞大且复杂,涉及多种编程语言,如Python。此外,OpenStack的灵活性和开放性导致了大量第三方模块和插件的出现,这些额外的工具和服务虽然丰富了OpenStack的功能,但也增加了学习曲线的陡峭度。
在跟踪虚拟机创建的过程中,作者可能会涉及Nova的调度器、计算节点、网络配置等多个环节,这要求对虚拟化技术(如KVM)、存储系统(如LVM)以及网络服务有深入的理解。此外,OpenStack的API交互、事件驱动的架构以及服务间的通信机制(如AMQP消息队列)也是学习的重点。
OpenStack社区的活跃意味着不断有新的项目和改进,如Telemetry(Ceilometer)用于计量和计费,Orchestration(Heat)用于模板化云资源部署,DatabaseService(Trove)用于数据库即服务,以及DataProcessing(Sahara)用于大数据处理。每个模块都有其特定的用例和实现细节,学习者需要筛选和专注于与自己需求相关的部分。
对于初学者,建议首先从OpenStack的基本概念和核心组件入手,理解每个组件的功能和它们之间的交互方式。然后,可以通过参与社区、阅读文档、实践操作和调试代码来逐步深化理解。同时,选择一个或几个关键领域进行深入研究,如虚拟化技术、分布式存储或网络配置,以逐步熟悉OpenStack的全貌。在这个过程中,保持对新技术的关注,以便及时了解OpenStack的最新发展和创新。
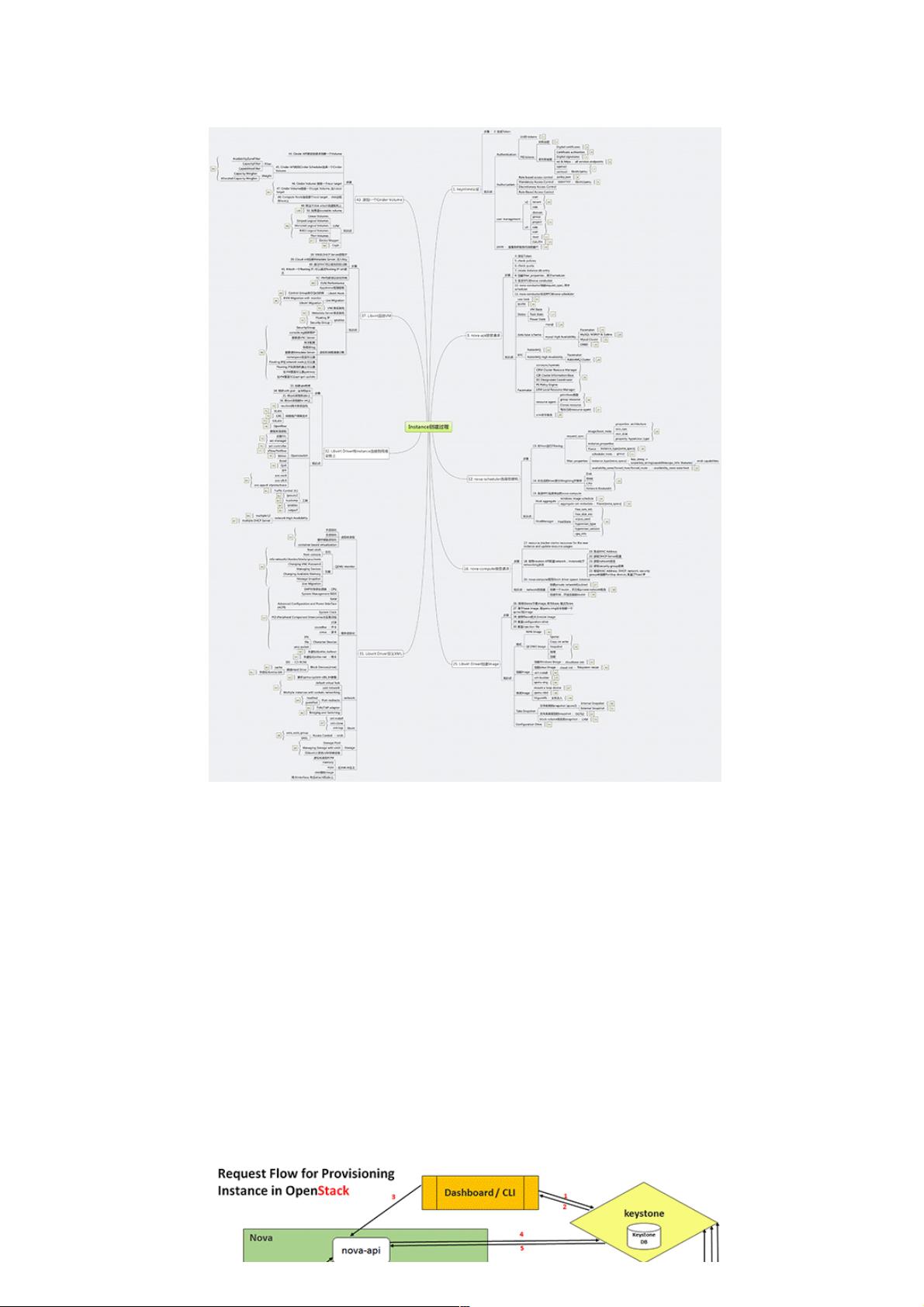
Openstack想说爱你不容易想说爱你不容易
还是先上图吧,无图无真相
别以为真懂Openstack!先别着急骂我,我也没有说我真懂Openstack
我其实很想弄懂Openstack,然而从哪里下手呢?作为程序员,第一个想法当然是代码,Code Talks,什么都可以忽悠,代码是实实在在
的,何况原来也深入读过Lucene, Hadoop的源代码,总以为从代码下手,背后的原理变了然了。
说干就干,我喜欢读取代码的方式是按照情景阅读,比如在Lucene中跟踪索引的过程,跟踪搜索的过程,比如在Hadoop中,跟踪写入文
件的过程,跟踪Map-Reduce的过程,于是在Openstack中决定跟踪虚拟机创建的整个过程
好在很多先贤已经做过这方面的事情,想来也没有那么的困难。
比较推荐一篇 Request Flow for Provisioning Instance in Openstack,如果被墙挡住了,我转到了Request Flow for Provisioning
Instance in Openstack
下载后可阅读完整内容,剩余9页未读,立即下载
2020-07-07 上传
2018-04-13 上传
2023-06-06 上传
2023-05-17 上传
2023-05-24 上传
2023-05-31 上传
2023-05-30 上传
2023-05-11 上传
2023-10-18 上传

weixin_38711110
- 粉丝: 5
- 资源: 932
 我的内容管理
展开
我的内容管理
展开







最新资源
- OptiX传输试题与SDH基础知识
- C++Builder函数详解与应用
- Linux shell (bash) 文件与字符串比较运算符详解
- Adam Gawne-Cain解读英文版WKT格式与常见投影标准
- dos命令详解:基础操作与网络测试必备
- Windows 蓝屏代码解析与处理指南
- PSoC CY8C24533在电动自行车控制器设计中的应用
- PHP整合FCKeditor网页编辑器教程
- Java Swing计算器源码示例:初学者入门教程
- Eclipse平台上的可视化开发:使用VEP与SWT
- 软件工程CASE工具实践指南
- AIX LVM详解:网络存储架构与管理
- 递归算法解析:文件系统、XML与树图
- 使用Struts2与MySQL构建Web登录验证教程
- PHP5 CLI模式:用PHP编写Shell脚本教程
- MyBatis与Spring完美整合:1.0.0-RC3详解
