




Huffman编码算法与实现
下载需积分: 3 | DOCX格式 | 96KB |
更新于2024-07-31
| 101 浏览量 | 举报
"这篇资源是关于数据结构中的哈夫曼编码(Huffman Coding)的一个实践题目,涉及到了构建哈夫曼树以及求解哈夫曼编码的算法。它提供了一个简单的C语言程序,用于输入字符集及其出现概率,并输出相应的哈夫曼编码。"
在数据压缩领域,哈夫曼编码是一种非常有效的无损数据压缩方法,由大卫·艾伦·哈夫曼于1952年提出。它的核心思想是通过构建一棵特殊的二叉树——哈夫曼树(Huffman Tree),使得出现频率较高的字符拥有较短的编码,而出现频率较低的字符则拥有较长的编码,这样可以使得整体编码效率更高。
哈夫曼编码的构建过程主要包括以下步骤:
1. 构建哈夫曼树:
- 初始化:创建一个大小为2n-1的最小堆,其中n为字符数。每个堆节点表示一个字符及其出现频率,初始时,每个字符是一个单独的叶子节点。
- 合并最小节点:每次从堆中取出两个权值(频率)最小的节点,合并成一个新的内部节点,新节点的权值为两个子节点权值之和,且指向这两个子节点。将新节点插入堆中。
- 重复以上步骤,直到堆中只剩下一个节点,即为哈夫曼树的根节点。
2. 求解哈夫曼编码:
- 遍历哈夫曼树,从根节点到每个叶子节点的路径形成该叶子节点的编码。通常,左分支代表0,右分支代表1。
- 记录每个字符的编码,可以使用一个数组或链表存储,其中包含字符及其对应的编码字符串。
在提供的程序中,`Huffman_tree`函数用于构建哈夫曼树,它首先初始化所有节点,然后根据用户输入的字符频率进行合并。`Huffman_code`函数则负责计算每个字符的哈夫曼编码。主函数`main`接收用户输入,调用这两个函数,最后打印出编码结果。
程序中定义了如下数据结构:
- `huffm`结构体表示哈夫曼树的节点,包含权重`wi`、数据`data`以及父节点、左子节点和右子节点的指针。
- `ctype`结构体用于存储字符的编码,包括编码字符串`bits`、编码起始位置`start`和字符本身`ch`。
这个简单的程序虽然没有处理浮点数频率,但可以通过修改来支持。此外,为了实际应用,可能还需要增加错误检查、编码的输出优化等功能。这个程序提供了一个理解哈夫曼编码基本概念和实现的好例子。
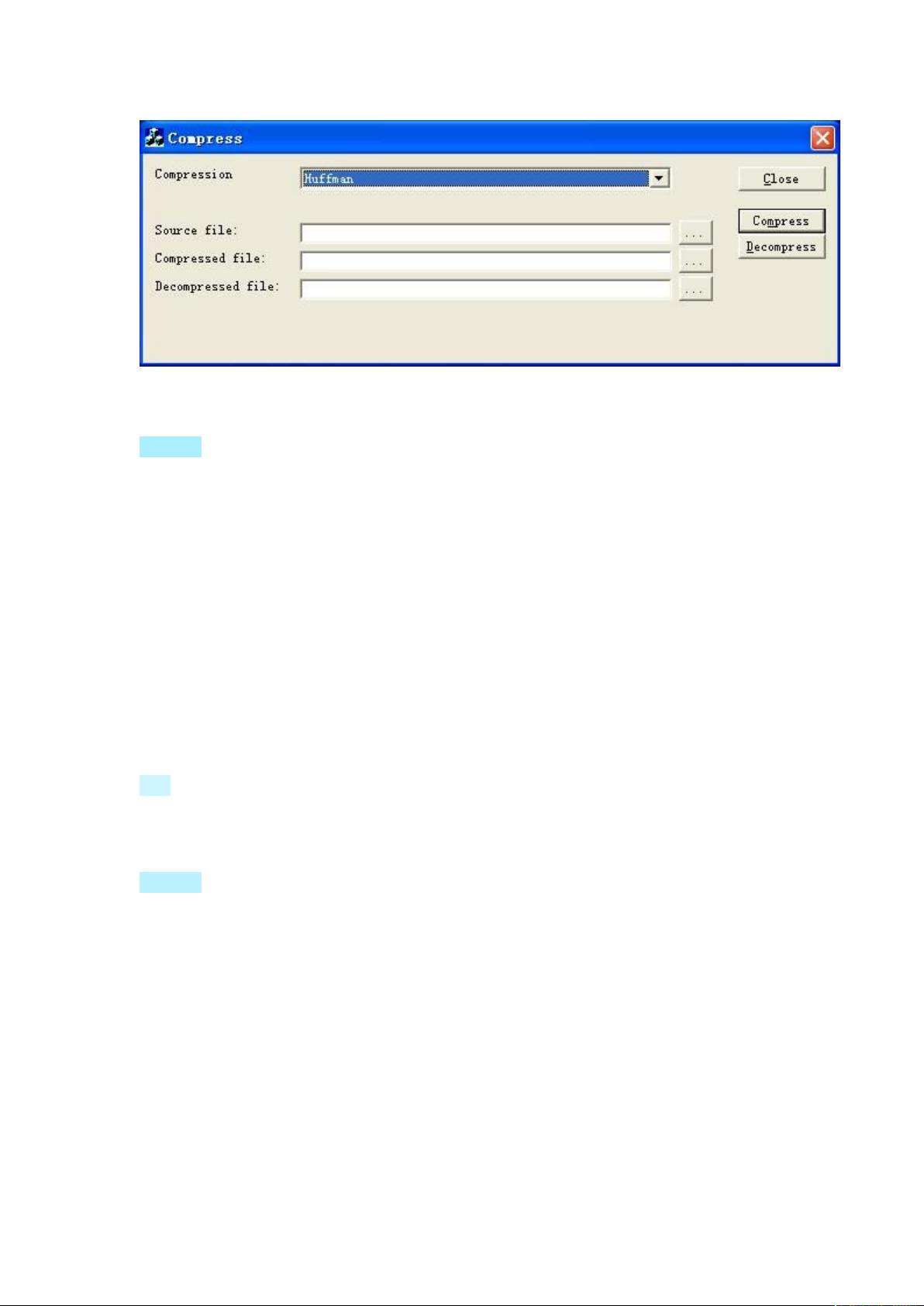
可以操作取文件
实现细节
<+;类如下
<<+;
&
DE
<+;/2
FG#)
HI,J# )
KLMNK(<)
<B')
<+;0$D*0$B%*0$N')
)
函数
压缩函数 <$+;
解压函数 K$+;
压缩算法
首先用 .<OO 码的值初始化 <+;3P""5/这里是个小技巧*除了储存 PQ 个
.<OO 码外,还有 PP 个节点用于生成树的父母节点2
%/<7)<PQ)<882
3<5# 7<)
接着计算 .<OO 码的使用频率
%/<7)<.B)<882
3<5FG#88)
然后用 进行排序
G/*PQ*R%/<+;2*%G#<$2)
再生成 +; 树
<7S+;,/2)
构造 +; 树


剩余55页未读,继续阅读
相关推荐






highuyn
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- Java实现的简易服务器教程
- 打造卓越战略实施能力的企业组织架构
- Java源码分享:实现WordSort与让Java程序优雅停止
- Access_Modify-1.0.2-py3-none-any.whl压缩包使用指南
- Go开发的汇率查询命令行工具
- Ruby框架下的数据库表设计技巧解析
- 小k娱乐网HTML5/CSS3源码模板下载
- Java实战项目:模拟蜘蛛纸牌与源码获取教程
- 网站设计仿站小工具9.8:快速下载网站模板与内容
- Ruby项目中用户和项目表格设计详解
- Go语言跨平台文本界面开发库termbox-go介绍
- AccessControl库4.0b5版本Python3.5安装包解析
- CSCI3170G7数据库课程深度解析
- PJBlog3新年快乐主题模板发布
- 市场预测总论:企业战略规划的参考指南
- Hugo主题开发教程:使用保罗霍夫曼主题构建网站





















