编译原理:词法分析详解
版权申诉
91 浏览量
更新于2024-07-07
收藏 414KB PDF 举报
"软件编译原理的第三章深入探讨了词法分析这一关键步骤,它在编译器的构造中占据重要地位。词法分析是从源代码的字符序列中识别并提取有意义的单词,形成单词序列的过程,为后续的语法分析和编译工作打下基础。"
在编译器的工作流程中,词法分析位于源程序到目标代码转化的最前端,紧接其后的是语义分析、语法分析、中间代码生成和优化,最终生成目标代码。词法分析阶段,源程序被看作是一连串的字符,而词法分析的任务就是将这些字符流转化为一个个有意义的单词,这些单词是编程语言中最小的、具有独立语义的单位。例如,在一段简单的源代码中,"float sum, first;",经过词法分析后会变成单词序列,包括"float"、"sum"、","、"first"等。
词法分析器,又称为词法分析程序或扫描器,负责执行这个识别过程。有两种常见的设计方式:附属词法分析器和独立词法分析器。附属词法分析器与语法分析紧密相连,每次语法分析调用时,它都会从字符序列中提取一个单词并返回相应的TOKEN。相反,独立词法分析器会一次性扫描整个源程序,生成一个完整的TOKEN序列,然后提供给语法分析器。
在词法分析过程中,单词通常被分为不同类别,如标识符、关键字、常量、运算符、分隔符等。标识符是由用户定义的,用于区分程序中的变量、常量、数组和函数。例如,"sum"和"first"在上面的例子中属于标识符。此外,还有一些预定义的关键字,比如在许多语言中的"float",它们在编译器中有特定的含义。
词法分析程序的实现通常涉及到正则表达式和有限状态自动机(FSM)的概念。正则表达式用于定义各种类型的单词模式,而有限状态自动机则用于识别这些模式。自动生成工具如LEX或Flex可以帮助开发人员根据正则表达式创建词法分析器。
词法分析不仅识别单词,还会进行词法检查,确保源代码中的单词符合语言的规则,例如检查标识符是否合法,数值是否有效,字符串是否完整等。一旦词法分析完成,生成的TOKEN序列就可以作为输入,进入语法分析阶段,进一步解析程序的结构和意义。
词法分析是编译器工作流程中的基础步骤,对理解源代码的结构至关重要。通过高效地进行词法分析,可以为后续的编译步骤提供清晰、规范的输入,从而保证整个编译过程的正确性和效率。
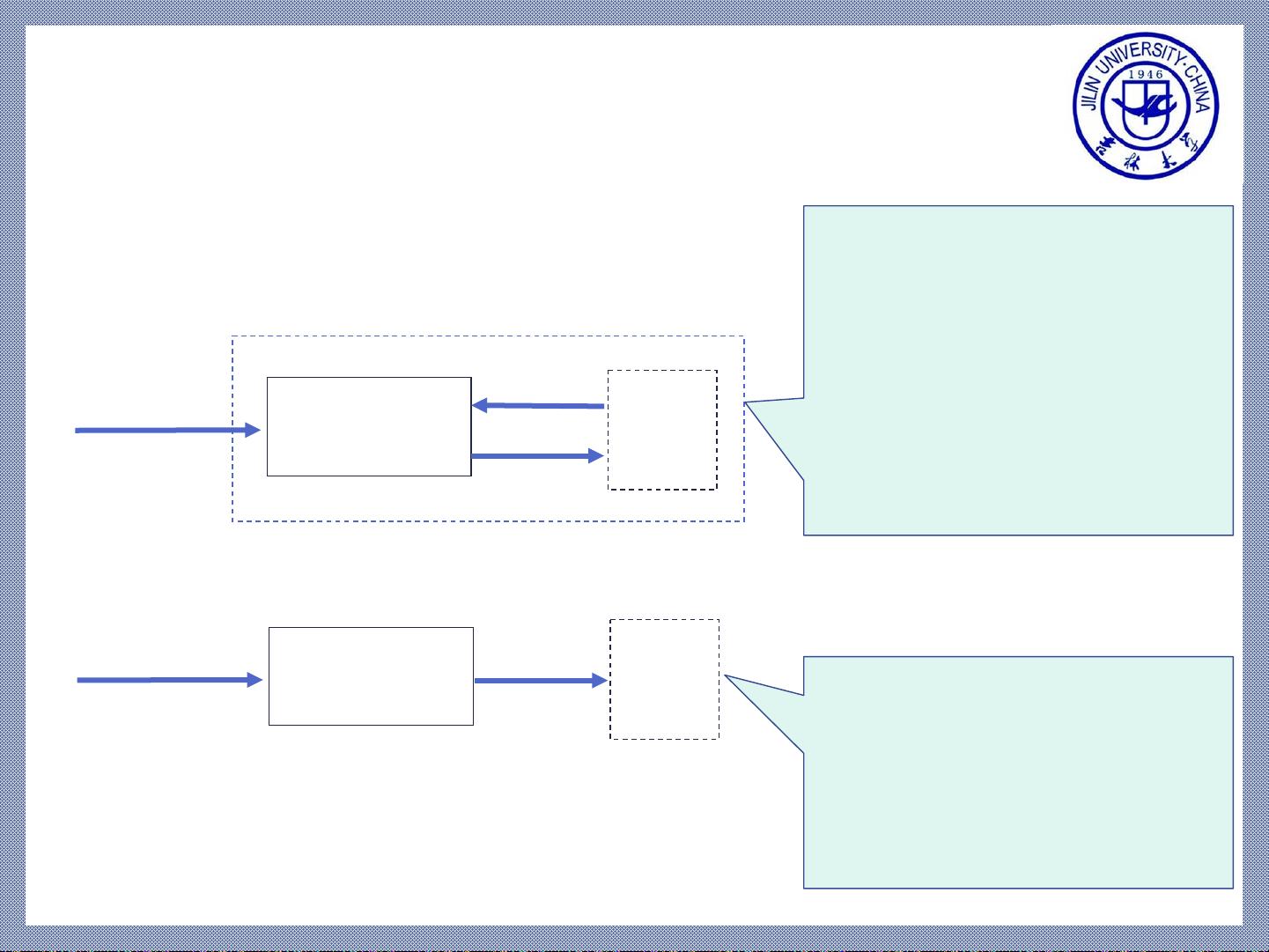
词法分析程序的接口
7
附属
词法分析器
语法
分析
call
Token
CharList
语法分析每调用一次
词法分析,就从源程序字
符序列中拼出一个单词,
将其TOKEN值返回给语法
分析程序。
优点是不需存储源程
序的内部表示。
独立
词法分析器
语法
分析
Token
List
CharList
词法分析独立一遍扫
描源程序字符序列,获得
Token序列送入语法分析
器内;因此需要保存
Token序列。

剩余38页未读,继续阅读
2021-09-20 上传
2021-04-28 上传
2021-09-01 上传
2021-09-20 上传
2024-05-06 上传
2024-05-08 上传
2022-03-10 上传
2021-09-20 上传
2021-09-20 上传

wxg520cxl
- 粉丝: 25
- 资源: 3万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- WordPress作为新闻管理面板的实现指南
- NPC_Generator:使用Ruby打造的游戏角色生成器
- MATLAB实现变邻域搜索算法源码解析
- 探索C++并行编程:使用INTEL TBB的项目实践
- 玫枫跟打器:网页版五笔打字工具,提升macOS打字效率
- 萨尔塔·阿萨尔·希塔斯:SATINDER项目解析
- 掌握变邻域搜索算法:MATLAB代码实践
- saaraansh: 简化法律文档,打破语言障碍的智能应用
- 探索牛角交友盲盒系统:PHP开源交友平台的新选择
- 探索Nullfactory-SSRSExtensions: 强化SQL Server报告服务
- Lotide:一套JavaScript实用工具库的深度解析
- 利用Aurelia 2脚手架搭建新项目的快速指南
- 变邻域搜索算法Matlab实现教程
- 实战指南:构建高效ES+Redis+MySQL架构解决方案
- GitHub Pages入门模板快速启动指南
- NeonClock遗产版:包名更迭与应用更新
