深入理解Hadoop:分布式文件系统与MapReduce解析
需积分: 3 87 浏览量
更新于2024-09-19
收藏 2.63MB DOC 举报
"本文是关于Hadoop技术的分析,涵盖了Hadoop的基本原理,特别是HDFS(Hadoop Distributed FileSystem)的工作机制,以及MapReduce编程模型。文章还提及了Hadoop的架构,包括JobTracker和TaskTracker的角色,并简述了作为Hadoop程序员需要掌握的关键点,如编写Mapper、Reducer、InputFormat和OutputFormat。此外,还详细描述了HDFS的文件写入和读取过程,以及重要参数dfs.replication的含义。"
Hadoop是基于Google MapReduce概念的开源大数据处理框架,它简化了在大规模分布式环境中的编程工作。MapReduce提供了处理海量数据的能力,通过将计算任务分解为可并行执行的map和reduce阶段,使得普通开发者无需深入理解并发处理或分布式系统的复杂性,就能构建处理大量数据的应用。
Hadoop的核心组件包括HDFS和MapReduce。HDFS是分布式文件系统,它负责在多台机器(通常称为DataNodes)上存储数据,并保证高可用性和容错性。MapReduce则是一个计算框架,由JobTracker和TaskTracker协同工作,管理数据处理任务的分配和执行。
HDFS的设计原则是数据本地化,即将数据计算任务尽可能地安排在数据所在的节点上执行,以减少网络传输,提高效率。文件在HDFS中被分割成多个Block,并复制到多个DataNode上,这样即使有节点故障,数据也能被恢复。 dfs.replication是HDFS中的一个重要参数,用于设置文件Block的副本数量,以确保数据的冗余和可靠性。
编程MapReduce应用时,程序员需要定义以下关键组件:
1. Mapper:Mapper接收输入数据,将其转换为键值对形式的中间结果。
2. Reducer:Reducer对Mapper产生的中间结果进行聚合,生成最终的输出结果,可选。
3. InputFormat:定义如何将原始输入数据拆分成键值对,供Mapper处理。
4. OutputFormat:定义最终结果的格式和写入方式。
文件写入HDFS的过程涉及Client与NameNode的交互,NameNode负责元数据管理,指导Client将文件Block写入DataNodes。文件读取时,Client向NameNode查询文件位置,然后直接从相应的DataNode读取数据。
Hadoop不仅支持Java编程,还允许使用其他语言如C++来编写MapReduce任务,极大地扩展了其适用范围。Hadoop为处理大数据提供了一个可靠、可扩展的平台,使得企业能够高效地管理和分析海量数据。
Hadoop 是 2005 Google MapReduce 的一个 Java 实现。MapReduce
是一种简化的分布式编程模式,让程序自动分布到一个由普通机器
组成的超大集群上并发执行。就如 同 java 程序员可以不考虑内存泄
露一样, MapReduce 的 run-me 系统会解决输入数据的分布细节,
跨越机器集群的程序执行调度,处理机器的失效,并且管理机器之
间的通讯请求。这样的 模式允许程序员可以不需要有什么并发处理
或者分布式系统的经验,就可以处理超大的分布式系统得资源。
不管过去,现在是 Apache 软件基金会管理的开源项目
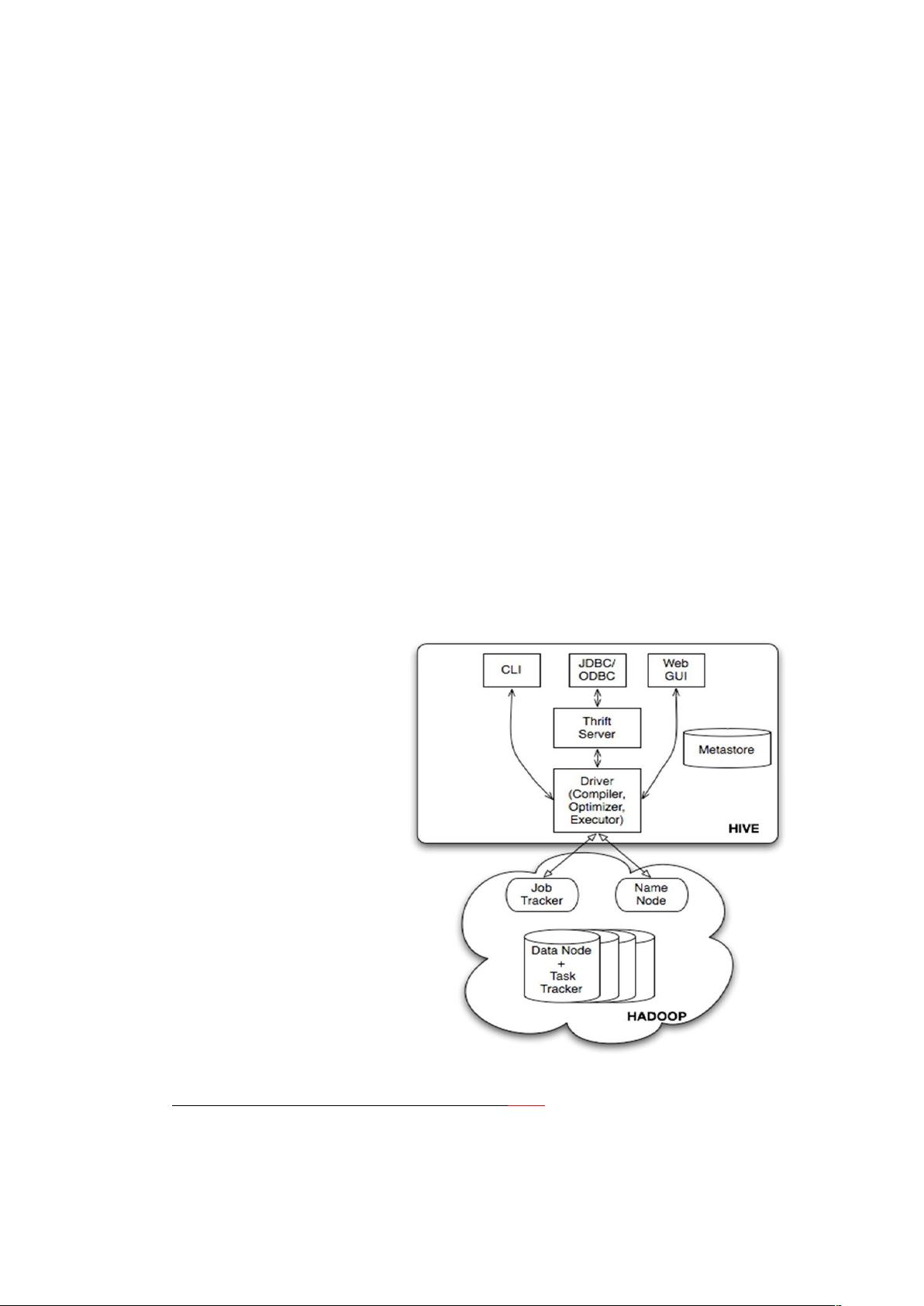
基本架构——Hadoop 是如何构成的
Hadoop 主要由 HDFS(Hadoop Distributed File System)和 MapReduce 引擎两部分组成。最底部是 HDFS,
它存储 Hadoop 集群中所有存储节点上的文件。HDFS 的上一层是 MapReduce 引擎,该引擎由 JobTrackers 和
TaskTrackers 组成。
如下图
(
HDFS
暂时未提供
分布式文件锁功能,所以是但节点,成为 瓶颈)
虽然 Hadoop 自身由 Java 语言开发,但它除了使用 Java 语言进行编程外,同样支持多种
编程语言,如 C++
下载后可阅读完整内容,剩余7页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2014-03-27 上传
2013-11-21 上传
2015-10-17 上传
2013-05-07 上传
2013-10-11 上传
2021-10-01 上传

jeckzang
- 粉丝: 0
- 资源: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- 人工智能习题(word文档版)
- 三种基本放大电路模电
- com技术原理与应用
- C语言试题分享(好东西哦!~)
- 计算机等级考试Vb常用内部函数
- Labview8.2入门
- C++ Network Programming Volume 1
- 基于NI6230和Measurement Studio的高速数据采集系统的设计与实现
- 基于vc的数据采集卡程序设计
- WaveScan高级波形搜索与分析
- Tomcat安全验证机制
- 1Z0-042 测试题 2006年12月20日.pdf
- 温湿传感器sht10的C程序.doc
- Oracle_Standby_Database.ppt
- 出租车计价器 单片机
- XXX管理系统详细设计文档
