HDFS1.0深度解析:系统架构与NameNode机制
需积分: 9 165 浏览量
更新于2024-07-18
收藏 896KB PDF 举报
"HDFS1.0精进"
在大数据存储领域,Hadoop Distributed File System (HDFS) 是一种被广泛采用的分布式文件系统,而HDFS1.0是其早期的重要版本。本资料主要涵盖了HDFS的基础知识、Shell API以及系统架构等核心内容。
HDFS基础部分介绍了HDFS的基本原理和工作模式。HDFS设计的目标是处理和存储大量数据,它以高容错性和可扩展性为特点,适应大规模集群环境。HDFS遵循主从结构,由三个主要组件构成:NameNode、Secondary NameNode和DataNode。
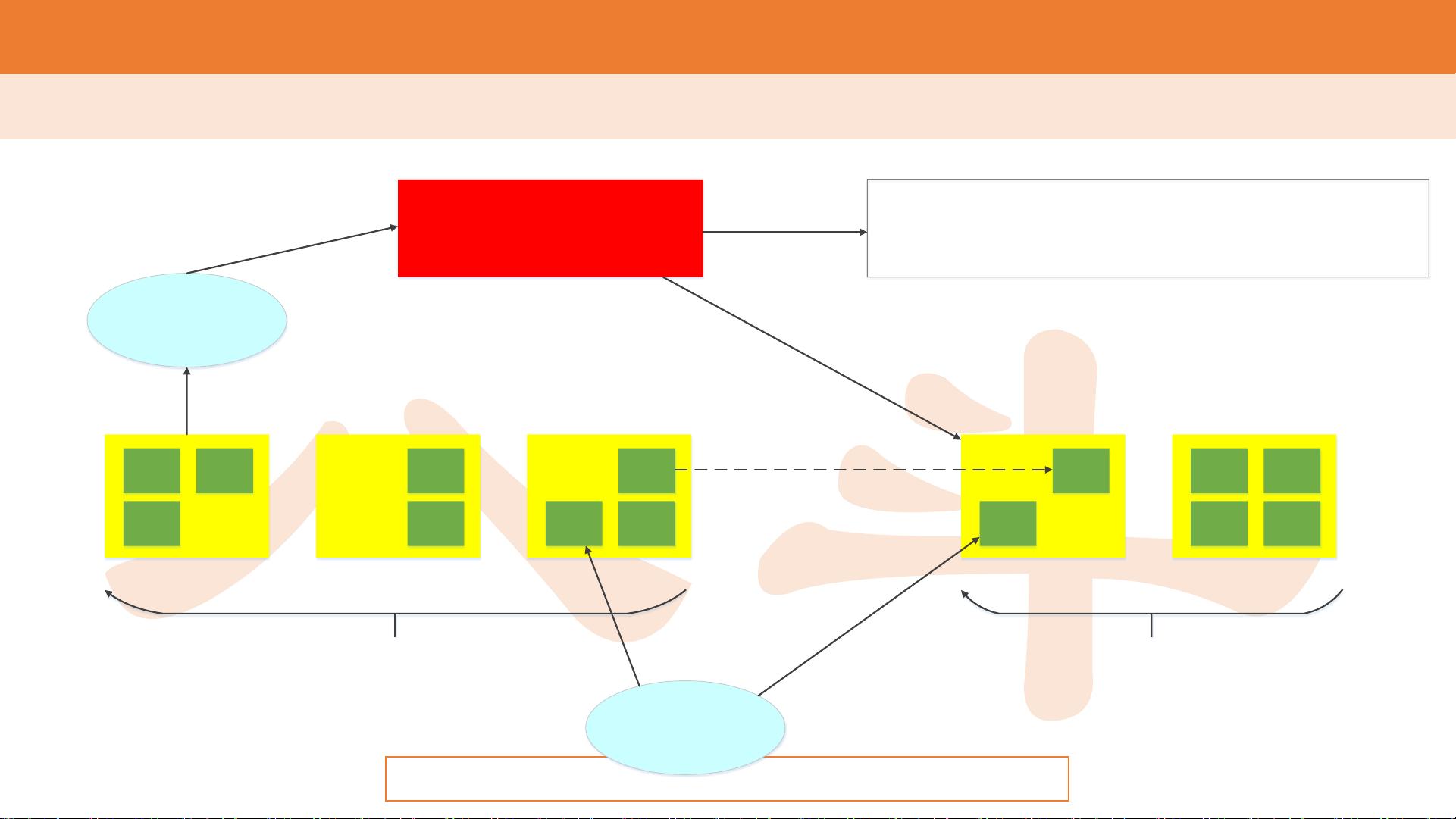
NameNode是HDFS的核心组件,它扮演着文件系统元数据的管理者角色。NameNode维护着整个文件系统的命名空间,包括文件和目录的层级结构,以及文件的属性信息(如所有者、权限)。更重要的是,NameNode存储文件到数据块的映射,但不包含具体数据块在DataNode上的位置信息。
DataNode是HDFS的数据存储节点,它们实际存储数据块,并执行客户端的读写请求。文件在HDFS中被划分为多个固定大小的块,这些块会被复制到不同的DataNode上以实现冗余和容错。当客户端读取文件时,NameNode提供文件块的位置信息,客户端随后直接与相应的DataNode通信进行数据传输。
Secondary NameNode并非NameNode的备份,而是一种辅助角色,用于定期帮助NameNode合并编辑日志(edits log)和镜像文件(fsimage),减少NameNode启动时的元数据加载时间,防止元数据过于庞大导致的性能问题。
HDFSShell API是操作HDFS的命令行工具,允许用户执行如创建、删除、移动、查看文件和目录等操作。通过Shell命令,可以便捷地与HDFS进行交互,管理存储在其中的数据。
在实际应用中,HDFS1.0的架构设计确保了高可用性和数据可靠性。例如,通过数据块的复制策略,即使部分DataNode故障,系统也能继续提供服务。默认情况下,每个数据块会有三个副本,分布在不同的机架上,以增加容错能力。
HDFS1.0是一个强大的分布式文件系统,特别适合处理大规模数据的存储和处理任务。理解并熟练掌握HDFS1.0的基础知识和操作方法,对于从事大数据处理和分析的人员至关重要。
包罗万象——HDFS1.0
——
八斗大数据内部资料,盗版必究
——
H D F S 系统架构
NameNode
Metadata(Name,replicas,……):
/home/foo/data, 3, ……
Client
Client
Read DataNode
Replication
Rack1
Rack2
Block
DataNode
Block OPS
Metadata OPS
剩余22页未读,继续阅读
2024-07-20 上传
2024-07-24 上传
2024-07-23 上传
2023-05-15 上传
2024-10-20 上传
2024-09-28 上传
2021-03-18 上传
2018-05-06 上传
2019-07-02 上传


ycjunhua
- 粉丝: 560
- 资源: 74
 我的内容管理
展开
我的内容管理
展开







最新资源
- Java集合ArrayList实现字符串管理及效果展示
- 实现2D3D相机拾取射线的关键技术
- LiveLy-公寓管理门户:创新体验与技术实现
- 易语言打造的快捷禁止程序运行小工具
- Microgateway核心:实现配置和插件的主端口转发
- 掌握Java基本操作:增删查改入门代码详解
- Apache Tomcat 7.0.109 Windows版下载指南
- Qt实现文件系统浏览器界面设计与功能开发
- ReactJS新手实验:搭建与运行教程
- 探索生成艺术:几个月创意Processing实验
- Django框架下Cisco IOx平台实战开发案例源码解析
- 在Linux环境下配置Java版VTK开发环境
- 29街网上城市公司网站系统v1.0:企业建站全面解决方案
- WordPress CMB2插件的Suggest字段类型使用教程
- TCP协议实现的Java桌面聊天客户端应用
- ANR-WatchDog: 检测Android应用无响应并报告异常
