深度神经网络的片上处理与学习技术
14 浏览量
更新于2024-06-18
收藏 3.05MB PDF 举报
"在芯片上处理和学习深度神经网络,由Ghouthi Boukli Hacene撰写,是一篇关于在硬件层面实现深度神经网络(DNN)运算的科学研究文件,属于信息与通信专业,特别是电子、计算机、信号、图像和视觉领域。该论文在2019年由国立高等矿业电信学院发表,并被HAL(多学科开放获取档案馆)收录,允许全球的研究人员访问和分享。论文的评审专家包括Hervé JEGEAN, Yoeli Bengio和Vincent GRIPON等知名学者。"
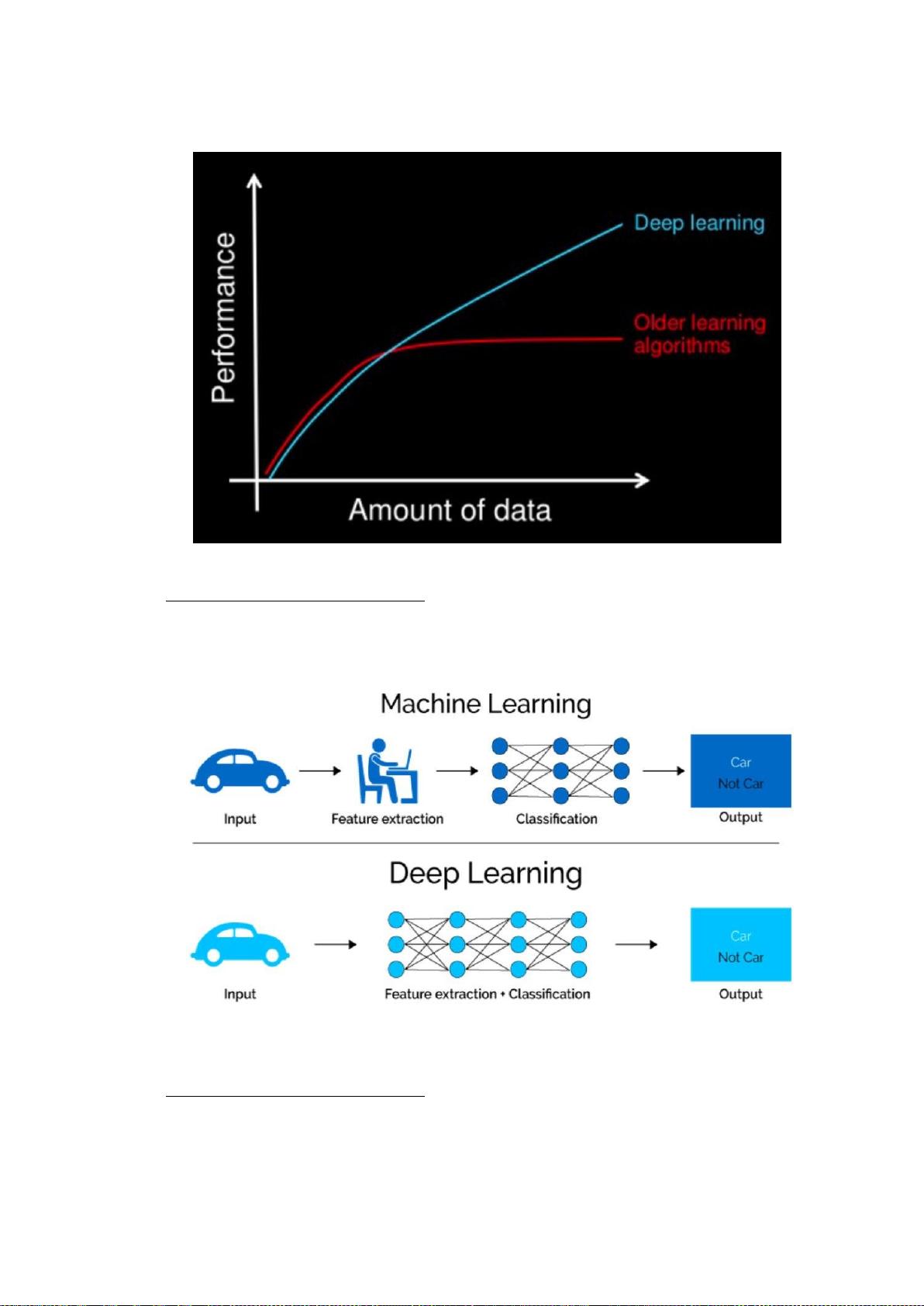
本文深入探讨了深度神经网络在芯片上的实现,这是现代计算技术的一个关键领域,因为深度学习模型通常需要大量的计算资源。深度学习是机器学习的一个分支,它模拟人脑的工作方式,通过多层神经网络对大量数据进行处理,从而实现模式识别、分类、自然语言处理等多种任务。
正文:
1. **导言**
导言部分可能介绍了深度学习的发展背景,以及在芯片上实现深度学习的重要性。随着AI技术的普及,对于高效能、低能耗的计算平台需求日益增长,这推动了在芯片上直接处理和学习深度神经网络的研究。
2. **深度学习基础**
这一部分详细阐述了深度学习的基本概念,包括数据集的使用。数据集是训练、验证和测试模型的基础,它们确保了模型的泛化能力。作者可能详细讨论了如何划分数据集,以及各个部分的作用:训练集用于训练模型,验证集用于调整模型参数,测试集用于评估模型的最终性能。
2.1.1 **训练、验证和测试集**
训练集是模型学习规律的主要来源,而验证集用于防止过拟合,通过比较在训练集和验证集上的表现来调整超参数。最后,测试集是评估模型在未见过的数据上的性能,保持其独立性,确保模型的泛化能力。
尽管提供的内容有限,但可以推测论文可能涵盖了以下主题:
- 芯片设计优化以适应深度学习计算,例如专用集成电路(ASIC)或现场可编程门阵列(FPGA)的设计。
- 能效比和计算效率的提升策略,如使用低功耗材料和算法优化。
- 在硬件上实现卷积神经网络(CNN)、循环神经网络(RNN)和变换器(Transformer)等深度学习架构的方法。
- 模型压缩和量化技术,以减小模型大小并提高在芯片上的运行速度。
- 实际应用案例,如在物联网设备、自动驾驶汽车或边缘计算中的应用。
通过这样的研究,作者可能提出了新的方法或改进方案,以提高在芯片上运行深度学习模型的效率和性能,为未来硬件与深度学习算法的融合奠定了基础。




2021-09-19 上传
2021-07-26 上传
2021-07-26 上传
2021-02-02 上传
2021-09-11 上传
2021-09-25 上传
2024-09-22 上传

cpongm
- 粉丝: 5
- 资源: 2万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- 前端面试必问:真实项目经验大揭秘
- 永磁同步电机二阶自抗扰神经网络控制技术与实践
- 基于HAL库的LoRa通讯与SHT30温湿度测量项目
- avaWeb-mast推荐系统开发实战指南
- 慧鱼SolidWorks零件模型库:设计与创新的强大工具
- MATLAB实现稀疏傅里叶变换(SFFT)代码及测试
- ChatGPT联网模式亮相,体验智能压缩技术.zip
- 掌握进程保护的HOOK API技术
- 基于.Net的日用品网站开发:设计、实现与分析
- MyBatis-Spring 1.3.2版本下载指南
- 开源全能媒体播放器:小戴媒体播放器2 5.1-3
- 华为eNSP参考文档:DHCP与VRP操作指南
- SpringMyBatis实现疫苗接种预约系统
- VHDL实现倒车雷达系统源码免费提供
- 掌握软件测评师考试要点:历年真题解析
- 轻松下载微信视频号内容的新工具介绍
