分布式文件系统详解:GFS、HDFS、TFS、Haystack
需积分: 10 15 浏览量
更新于2024-07-19
收藏 3.6MB PPTX 举报
"该资源为一个关于代表性分布式文件系统架构的PPT,涵盖了GFS、HDFS、TFS和Haystack等系统,旨在探讨分布式文件系统的基本原理和设计思路。"
分布式文件系统是一种跨越多个计算节点的存储解决方案,旨在处理大规模数据集,尤其适用于大数据分析和云计算环境。在这样的系统中,文件的存储和访问不是局限于单个设备,而是通过网络连接的多台计算机协同完成,提供高可用性和容错性。
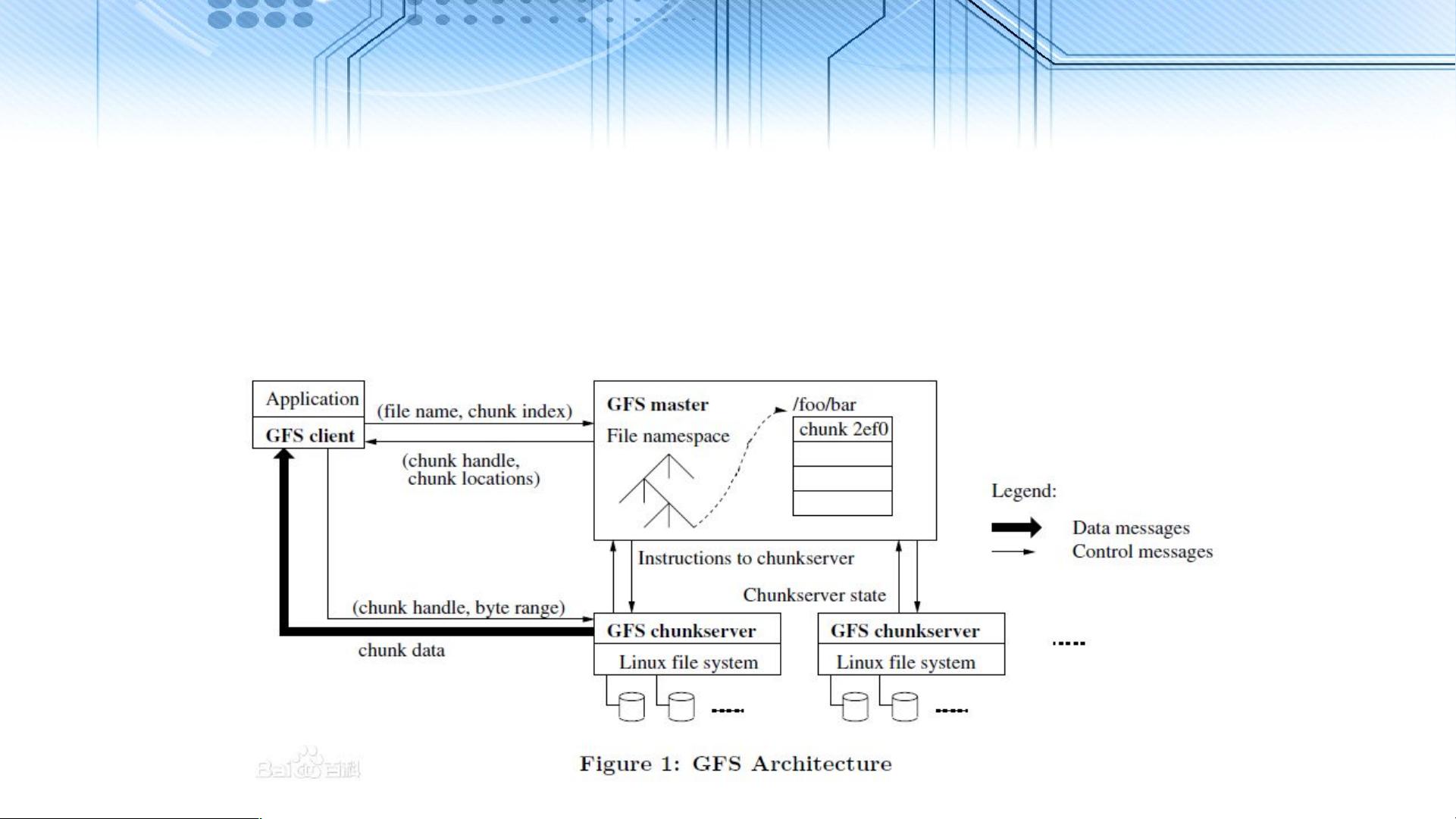
GFS(Google File System),由Google开发,是一个专为处理海量数据而设计的高可用分布式文件系统。GFS的独特之处在于它针对大规模分布式环境的特定需求进行了优化:
1. **容错性**:GFS设计时假设硬件故障是常态而非异常,因此它内置了错误检测、自动恢复和冗余机制,确保系统的持续运行。
2. **大文件处理**:GFS中的文件通常非常大,有时可达GB级别,文件系统设计着重于处理这些大型文件,而非小文件。大文件被分割成固定大小的块,便于并行处理和存储。
3. **追加式写入**:GFS鼓励文件的追加写入,而非随机修改。这种模式常见于日志记录、数据流处理和批量数据分析场景,优化了性能并简化了数据一致性管理。
4. **读取密集型**:工作负载主要由读取操作构成,可能是顺序读取或全文件扫描,这与传统的文件系统设计中强调的随机读写不同。
除了GFS,还有其他分布式文件系统值得一提,如:
- **HDFS(Hadoop Distributed File System)**:是Apache Hadoop项目的一部分,设计目标与GFS类似,但更加开源和通用,广泛应用于大数据处理和分析,特别是在MapReduce框架下。
- **TFS(Tencent File System)**:腾讯开发的分布式文件系统,适用于大规模互联网服务,提供了高吞吐量和低延迟的数据访问。
- **Haystack**:Facebook开发的一个分布式存储系统,主要用于存储和检索半结构化数据,如日志和元数据,特别适合大规模数据分析和检索。
这些分布式文件系统在设计时都考虑到了扩展性、容错性和高性能,它们是现代云计算基础设施的重要组成部分,支撑着各种大数据应用和服务。理解这些系统的工作原理和特性对于构建和优化大规模数据处理系统至关重要。

(一) GFS 与以往的文件系统的不同
⒌ 工作量还包含许多对大量数据进行的、连续的、向文件添加数据的写操作。
所写的数据的规模和读相似。一旦写完,文件很少改动。在随机位置对少量
数据的写操作也支持,但不必非常高效。
⒍ 系统必须高效地实现定义完好的大量客户同时向同一个文件的添加操作的
语义。
7. 高可持续带宽比低延迟更重要
剩余42页未读,继续阅读
2021-10-12 上传
2021-10-14 上传
2021-10-11 上传
2021-09-24 上传
2021-10-14 上传
2022-03-07 上传
2023-11-05 上传
2021-09-21 上传

jacsndk
- 粉丝: 0
- 资源: 5
 我的内容管理
展开
我的内容管理
展开







最新资源
- 磁性吸附笔筒设计创新,行业文档精选
- Java Swing实现的俄罗斯方块游戏代码分享
- 骨折生长的二维与三维模型比较分析
- 水彩花卉与羽毛无缝背景矢量素材
- 设计一种高效的袋料分离装置
- 探索4.20图包.zip的奥秘
- RabbitMQ 3.7.x延时消息交换插件安装与操作指南
- 解决NLTK下载停用词失败的问题
- 多系统平台的并行处理技术研究
- Jekyll项目实战:网页设计作业的入门练习
- discord.js v13按钮分页包实现教程与应用
- SpringBoot与Uniapp结合开发短视频APP实战教程
- Tensorflow学习笔记深度解析:人工智能实践指南
- 无服务器部署管理器:防止错误部署AWS帐户
- 医疗图标矢量素材合集:扁平风格16图标(PNG/EPS/PSD)
- 人工智能基础课程汇报PPT模板下载
