中文分词技术:正向、逆向与双向最大匹配算法解析
 已收录资源合集
已收录资源合集
需积分: 0 190 浏览量
更新于2024-06-25
收藏 2.17MB PPTX 举报
"自然语言处理:中文分词"
自然语言处理是计算机科学领域的一个关键分支,专注于让计算机理解和处理人类的自然语言。在中文自然语言处理中,中文分词是首要任务,因为中文句子没有明显的空格来区分词汇,因此需要通过特定的算法将连续的汉字序列分割成有意义的词语。本文将详细介绍两种常见的分词算法:正向最大匹配(FMM)和逆向最大匹配(RMM),以及它们的优缺点。
1. 正向最大匹配算法(FMM)
正向最大匹配算法是从句子的起始位置开始,向右逐个扫描汉字,尝试找到词典中最长的词。例如,在句子“秦皇岛今天晴空万里”中,最大匹配长度为4,所以算法可能会首先找到“秦皇岛”这个词。然而,该算法可能存在歧义问题,如“很好看”可能会被错误地分割为“很好”和“看”。为了优化效率,可以创建多个词典,分别对应不同长度的词,以减少查找时间。
2. 逆向最大匹配算法(RMM)
逆向最大匹配算法则从句子的末尾开始,向左匹配最长的词。由于中文句子中存在大量的偏正结构,从后向前匹配可以更准确地识别这些结构,从而降低错误率。例如,“你今天很好看”使用逆向最大匹配会得到“你/今天/很/好看”的结果,比正向最大匹配更为准确。逆向匹配通常使用逆序词典,先将文本倒序处理,再用正向最大匹配算法进行分词。
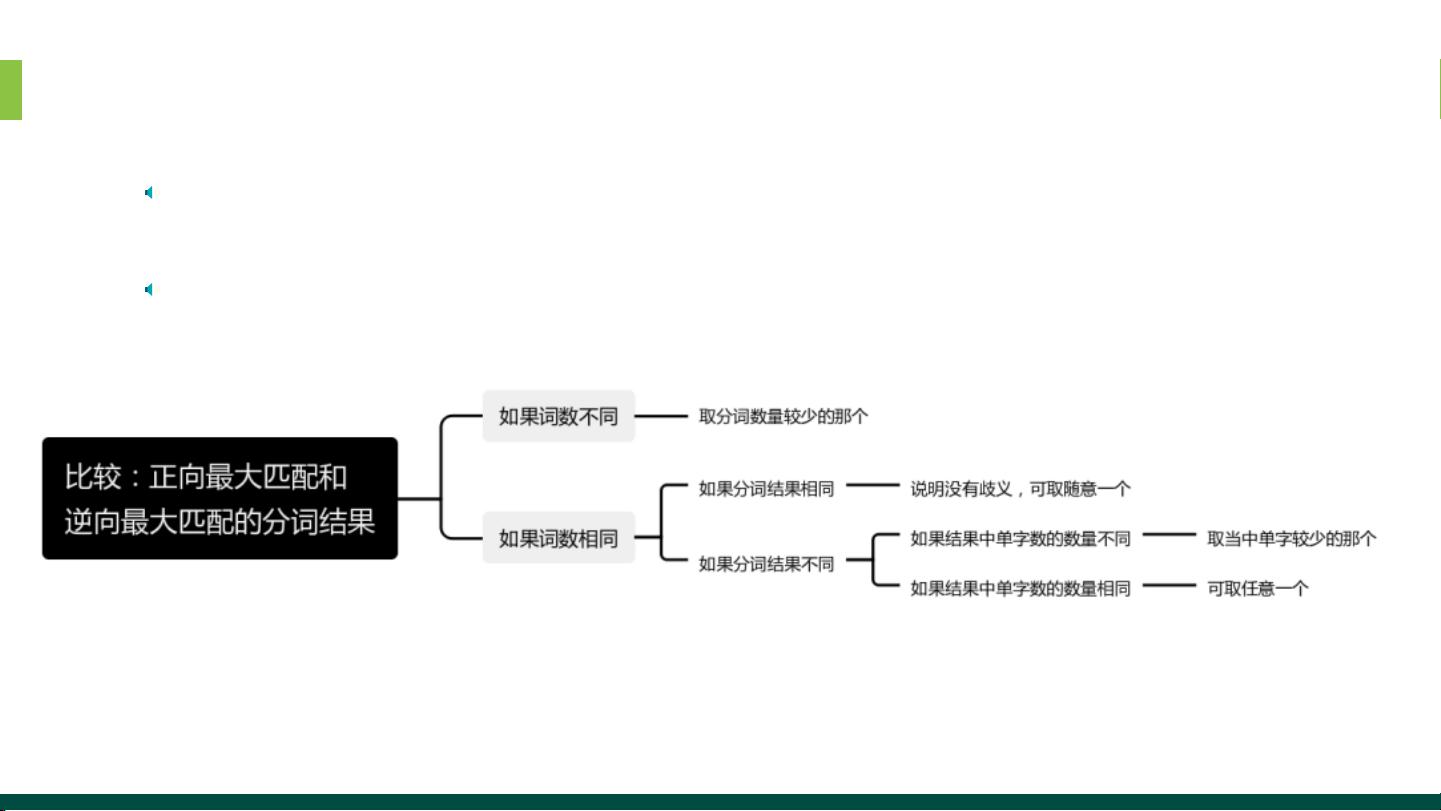
这两种算法各有优势,FMM简单快速,但可能产生歧义;RMM更精确,但计算量相对较大。为了解决两者的不足,出现了双向最大匹配(BM)算法,它结合了正向和逆向最大匹配的优点,先分别运行两者,然后比较结果,选取最优解。研究表明,大约90%的中文句子可以通过FMM和RMM的组合得到正确分词。
中文分词对于后续的自然语言处理任务至关重要,如词性标注、句法分析、情感分析等。通过有效的分词,可以提高整个系统的性能和准确性。随着深度学习和统计模型的发展,现代的中文分词工具,如jieba分词库,已经能提供更加智能和精准的分词服务,结合词频统计、上下文信息等,进一步提升了分词质量和效率。

《自然语言处理》
中文分词
2.逆向最大匹配算法(RMM)——注意事项
(1)逆向最大匹配算法使用的分词词典是逆序词典,里面的每个词都将按逆序方式存放。在实际应用
过程中,可以将待分词文本进行倒排处理,从而生成逆序文本,然后再根据逆序词典,对逆序文本用正
向最大匹配算法进行处理。
(2)在中文中,由于偏正结构较多,所以从后向前进行匹配会提高精确度,因此,逆向最大匹配算法
比正向最大匹配算法的误差要小。统计结果表明,单纯使用正向最大匹配的错误率为1/169,单纯使用
逆向最大匹配的错误率为1/245。例如,对“你今天很好看”这一句文本进行分词,按照正向最大匹配算
法得到的分词结果是“你/今天/很好/看”,按照逆向最大匹配算法得到的分词结果是“你/今天/很/好
看”。

剩余58页未读,继续阅读
318 浏览量
1715 浏览量
2024-05-06 上传
点击了解资源详情
503 浏览量
336 浏览量


人工智能_SYBH
- 粉丝: 5w+
- 资源: 233
 我的内容管理
展开
我的内容管理
展开







最新资源
- React性的
- Distributed-Blog-System:分布式博客系统实现
- CloseMe-crx插件
- 欧式建筑立面图纸
- 北理工自控(控制理论基础)实验报告
- yolov7升级版切图识别
- 作业-1 --- IT202:这是我的第一个网站
- hit-and-run:竞争性编程的便捷工具
- Pytorch-Vanilla-GAN:适用于MNIST,FashionMNIST和USPS数据集的Vanilla-GAN的Pytorch实现
- SNKit:iOS开发常用功能封装(Swift 5.0)
- 创意条形图-手机应用下载排行榜excel模板下载
- 项目36
- 通过混沌序列置乱水印.7z
- reactive-system-design
- getwdsdata.m:从 EPANET 输入文件中获取配水系统数据-matlab开发
- 100多套html模块+包含企业模板和后台模板(适合初级学习)
