All SMILES VAE:分子优化的变分自编码器
需积分: 0 75 浏览量
更新于2024-06-30
收藏 738KB PDF 举报
"本文介绍了一种名为All SMILES Variational Autoencoder (AllSMILESVAE) 的深度学习模型,该模型旨在改进分子属性优化,从而对医药和材料行业产生重大影响。模型通过处理SMILES字符串和图基表示来定义变分自编码器,解决了SMILES字符串非唯一性和图卷积计算成本高的问题。通过使用堆叠的循环神经网络编码多个SMILES字符串,以及采用注意力池化构建固定长度的潜在表示,AllSMILESVAE能够有效地传递分子图中的消息,并学习到近似双射的分子与潜在空间之间的映射。"
变分自编码器(VAEs)是深度学习领域的一种重要模型,通常用于数据的生成和降维。在化学和药物研发领域,它们可以用来学习分子的潜在表示,以优化特定的化学属性。传统的VAE在处理SMILES(简化分子输入线路语言)字符串时面临挑战,因为一个分子可能有多种不同的SMILES表示,这可能影响模型的性能。
AllSMILESVAE由Zaccary Alperstein、Artem Cherkasov和Jason Tyler Rolfe等人提出,他们来自D-Wave公司的Quadrant组。这个模型的独特之处在于其处理SMILES字符串的创新方式。它不是仅使用单个SMILES表示,而是利用一组堆叠的循环神经网络(如GRU,门控循环单元)来编码分子的多个SMILES表示。通过这种方式,模型能够捕捉到分子结构的多样性,同时避免了SMILES字符串非唯一性带来的问题。
在编码过程中,每个SMILES字符串的隐藏状态被聚合,形成一个综合的表示。这里采用了注意力机制进行池化,这使得模型能够根据需要关注不同的SMILES表示部分,以生成一个固定长度的潜在向量。这种潜在向量可以代表分子的关键特性,而且由于解码阶段会生成分子的不同SMILES表示,因此AllSMILESVAE学会了在高概率子空间内近乎双射的映射,提高了生成新分子的效率和准确性。
通过AllSMILESVAE,研究人员可以更有效地探索分子设计空间,寻找具有理想化学属性的新型分子结构。这种方法在药物发现和材料科学中有着巨大的潜力,可以加速新化合物的筛选过程,减少实验次数,降低成本,并最终推动医药和材料行业的创新。
AllSMILESVAE通过结合多种SMILES表示并利用注意力机制,提供了一种强大且灵活的框架,以处理分子结构的复杂性。这一方法克服了传统SMILES-based VAE的局限,为分子优化和生成开辟了新的道路。
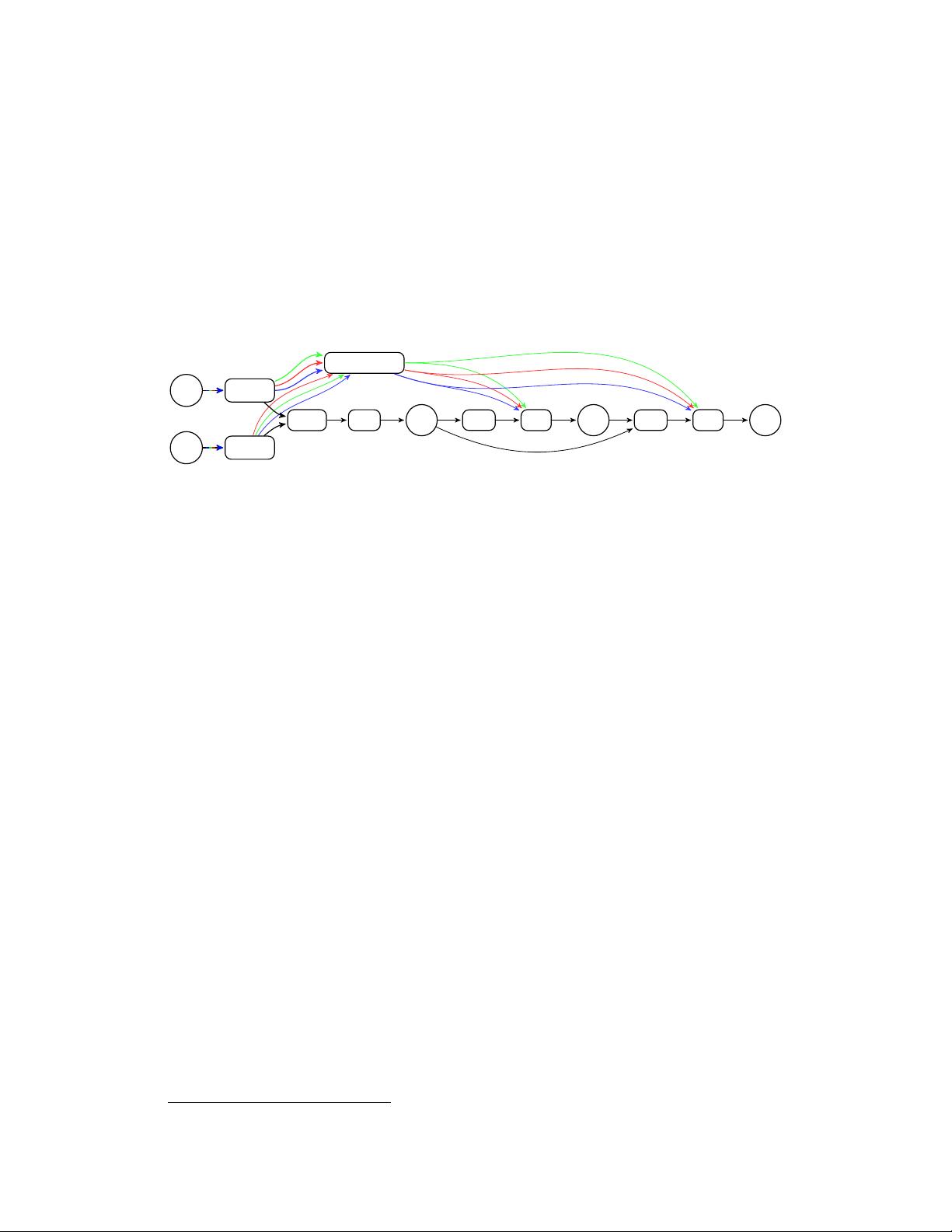
network of rectified linear units (ReLUs) given the concatenation of the previous latent layers as
input. This is analogous to the order-invariant encoding of set2set, but an output is produced at each
step, and processing is not gated [
65
]. The attentional mechanism is also effectively available to
property regressors that take the fixed-length latent representation as input, allowing them to aggregate
contributions from across the molecule. The output of the attentional mechanism is subject to batch
renormalization and a linear transformation to compute the conditional mean and log-variance of
the layer. The prior has a similar autoregressive structure, but uses neural networks of ReLUs in
place of Bahdanau-style attention, since it does not have access to the atom vectors. For molecular
optimization tasks, we usually scale up the term
KL [q(z|x)||p(z)]
in the ELBO by the number of
SMILES strings in the decoder, analogous to multiple single-SMILES VAEs in parallel; we leave this
KL term unscaled for property prediction.
GRU
1
GRU
2
h
T
1
h
T
2
Pool
Lin
z
1
Pool atoms
NN
Att
z
2
NN
Att
z
3
k
k
µ, σ
q
µ, σ
q
µ, σ
Figure 4: The approximating posterior is an autoregressive set of Gaussian distributions. The mean (
µ
)
and log-variance (
log σ
2
) of the first subset of latent variables
z
1
is a linear transformation of the
max-pooled final hidden state of GRUs fed the encoder outputs. Succeeding subsets
z
i
are produced
via Bahdanau-style attention with the pooled atom outputs of the GRUs as keys (
k
), and the query (
q
)
computed by a neural network on z
<i
.
The decoder is a single-layer LSTM, for which the initial cell state is computed from the latent repre-
sentation by a neural network, and a linear transformation of the latent representation is concatenated
onto each input. It is trained with teacher forcing to reconstruct a set of SMILES strings disjoint from
those provided to the encoder, but representing the same molecule. Grammatical constraints [
9
,
35
]
can naturally be enforced within this LSTM by parsing the unfolding character sequence with a
pushdown automaton, and constraining the final softmax of the LSTM output at each time step to
grammatically valid symbols. This is detailed in Appendix D, although we leave the exploration of
this technique to future work.
Since the SMILES inputs to the encoder are different from the targets of the decoder, the decoder
is effectively trained to assign equal probability to all SMILES strings of the encoded molecule.
The latent representation must capture the molecule as a whole, rather than any particular SMILES
input to the encoder. To accommodate this intentionally difficult reconstruction task, facilitate the
construction of a bijection between latent space and molecules, and following prior work [
28
,
67
], we
use a width-5 beam search decoder to map from the latent representation to the space of molecules at
test-time. Further architectural details are presented in Appendix B.
3.1 Latent space optimization
Unlike many models that apply a sparse Gaussian process to fixed latent representations to predict
molecular properties [
9
,
27
,
35
,
56
], the All SMILES VAE jointly trains property regressors with
the generative model [
42
].
2
We use linear regressors for the log octanol-water partition coefficient
(logP) and molecular weight (MW), which have unbounded values; and logistic regressors for the
quantitative estimate of drug-likeness (QED) [
4
] and twelve binary measures of toxicity [
22
,
45
],
which take values in
[0, 1]
. We then perform gradient-based optimization of the property of interest
with respect to the latent space, and decode the result to produce an optimized molecule.
Naively, we might either optimize the predicted property without constraints on the latent space, or
find the maximum a posteriori (MAP) latent point for a conditional likelihood over the property that
assigns greater probability to more desirable values. However, the property regressors and decoder are
only accurate within the domain in which they have been trained: the region assigned high probability
2
Gómez-Bombarelli et al. [16] jointly train a regressor, but still optimize using a Gaussian process.
5
剩余22页未读,继续阅读
2022-08-04 上传
125 浏览量
2012-08-22 上传
2022-04-19 上传
2021-07-05 上传
110 浏览量
2022-04-19 上传
2022-04-19 上传
105 浏览量

狼You
- 粉丝: 28
 我的内容管理
展开
我的内容管理
展开







最新资源
- Openaea:Unity下开源fanmad-aea游戏开发
- Eclipse中实用的Maven3插件指南
- 批量查询软件发布:轻松掌握搜索引擎下拉关键词
- 《C#技术内幕》源代码解析与学习指南
- Carmon广义切比雪夫滤波器综合与耦合矩阵分析
- C++在MFC框架下实时采集Kinect深度及彩色图像
- 代码研究员的Markdown阅读笔记解析
- 基于TCP/UDP的数据采集与端口监听系统
- 探索CDirDialog:高效的文件路径选择对话框
- PIC24单片机开发全攻略:原理与编程指南
- 实现文字焦点切换特效与滤镜滚动效果的JavaScript代码
- Flask API入门教程:快速设置与运行
- Matlab实现的说话人识别和确认系统
- 全面操作OpenFlight格式的API安装指南
- 基于C++的书店管理系统课程设计与源码解析
- Apache Tomcat 7.0.42版本压缩包发布
