本地MapReduce开发环境配置与Eclipse插件教程
需积分: 10 37 浏览量
更新于2024-07-16
收藏 1.52MB PPTX 举报
MapReduce编程是一个强大的分布式计算框架,专为处理海量数据而设计,尤其适用于离线计算场景。本文档着重介绍了如何在本地搭建MapReduce开发环境,以便于在本地进行代码编写、测试和远程Hadoop集群的交互。
首先,要确保项目中包含user library,因为这有助于正确链接和加载Hadoop相关的库。如果没有正确设置,可能会遇到运行时权限问题,如用户zc试图写入Hadoop文件系统但被拒绝。解决这个问题的方法是在计算机的环境变量中增加`HADOOP_USER_NAME`,将其值设置为`root`,这样可以赋予用户对Hadoop系统的适当权限。
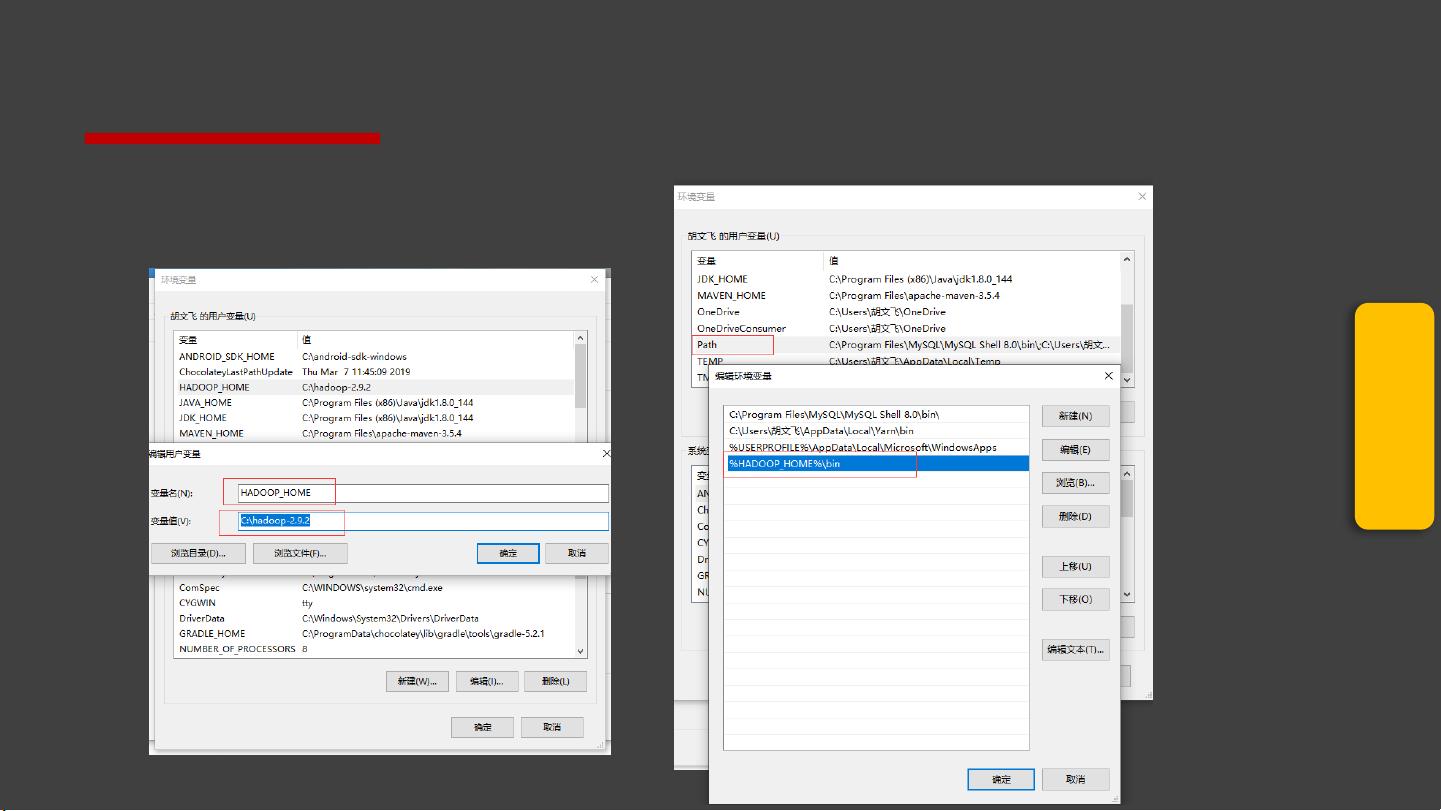
配置MapReduce环境的关键在于设置环境变量。这包括将Hadoop压缩包解压至本地(例如C盘),并将Hadoop的系统文件放入`system32`目录以及Hadoop的执行文件放到`{HADOOP_HOME}\bin`。在Windows环境下,为了使Hadoop工具能正常运行,这些系统文件和执行文件的位置尤为重要。
Eclipse作为常用的开发工具,文档推荐使用hadoop-eclipse-plugin-2.8.5进行MapReduce编程的支持。首先,需要将该插件的JAR文件添加到Eclipse的插件文件夹中,确保插件能够正确安装并运行。安装后,可以在Eclipse中配置本地Hadoop的路径,以及远程Hadoop的IP地址和端口号,以便通过MapReduce视图访问Hadoop文件系统。
在开发过程中,可能会遇到关于输入文件夹的创建和文件上传的问题。例如,如果在HDFS中找不到input目录,可以通过`hadoopfs –mkdir /input`命令手动创建。同时,将待分析的数据(如README.txt)上传到input目录,如`hadoopfs –put README.txt /input`。
MapReduce编程涉及的主要步骤包括创建Java工程,导入必要的jar包(如Hadoop核心API和其他依赖),并在本地或远程Hadoop上执行MR任务。通过这种方式,开发者可以在本地环境中高效地编写、测试和调试MapReduce程序,然后再部署到大规模的分布式集群中运行。
在学习过程中,除了理解基础的编程流程,还需要深入研究Java API,探索其丰富的功能,以便更好地利用MapReduce进行数据处理和分析。作者鼓励读者在这个基础上进行拓展和实践,提升自己的技能。
知
识
讲
解
环境变量
•
我们需要配置环境变量,如下
剩余23页未读,继续阅读
2022-11-02 上传
2022-11-02 上传
2020-04-09 上传
2019-11-07 上传
2021-10-14 上传
2022-06-21 上传
2021-10-14 上传
2022-11-03 上传

像我这样帅气的人
- 粉丝: 0
- 资源: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- Java集合ArrayList实现字符串管理及效果展示
- 实现2D3D相机拾取射线的关键技术
- LiveLy-公寓管理门户:创新体验与技术实现
- 易语言打造的快捷禁止程序运行小工具
- Microgateway核心:实现配置和插件的主端口转发
- 掌握Java基本操作:增删查改入门代码详解
- Apache Tomcat 7.0.109 Windows版下载指南
- Qt实现文件系统浏览器界面设计与功能开发
- ReactJS新手实验:搭建与运行教程
- 探索生成艺术:几个月创意Processing实验
- Django框架下Cisco IOx平台实战开发案例源码解析
- 在Linux环境下配置Java版VTK开发环境
- 29街网上城市公司网站系统v1.0:企业建站全面解决方案
- WordPress CMB2插件的Suggest字段类型使用教程
- TCP协议实现的Java桌面聊天客户端应用
- ANR-WatchDog: 检测Android应用无响应并报告异常
