树与二叉树的非递归中序遍历算法详解
"该资源是关于树与二叉树学习的资料,主要涵盖了二叉树的中序遍历,包括递归和非递归两种方法。由井冈山大学计算机科学系的孙凌宇教授提供,包含算法实现及示意图,帮助理解数据结构中的重要概念。"
在计算机科学中,树是一种抽象数据类型,用于表示具有层次关系的数据集合。树的每个部分称为结点,而二叉树是树的一个特例,每个结点最多有两个子结点,分别称为左子结点和右子结点。二叉树常用于数据的存储、排序和搜索等操作。
中序遍历是二叉树遍历的一种基本方法,通常用于对二叉搜索树进行排序输出。中序遍历的顺序是:先遍历左子树,然后访问根结点,最后遍历右子树。这确保了在二叉搜索树中,遍历的结果是有序的。
递归中序遍历的算法如以下所示:
1. 如果根结点不为空,则先递归遍历左子树。
2. 访问根结点。
3. 递归遍历右子树。
非递归中序遍历通常采用栈来辅助完成,其基本思路如下:
1. 初始化一个栈,并将根结点压入栈中。
2. 当栈不为空或当前处理的结点不为空时,执行以下操作:
a) 如果当前结点不为空,将其压入栈中,并将当前结点设置为其左子结点。
b) 否则,弹出栈顶元素(即上一步的父结点),访问该结点,然后将当前结点设置为其右子结点。
3. 循环直至栈为空且当前处理的结点为空。
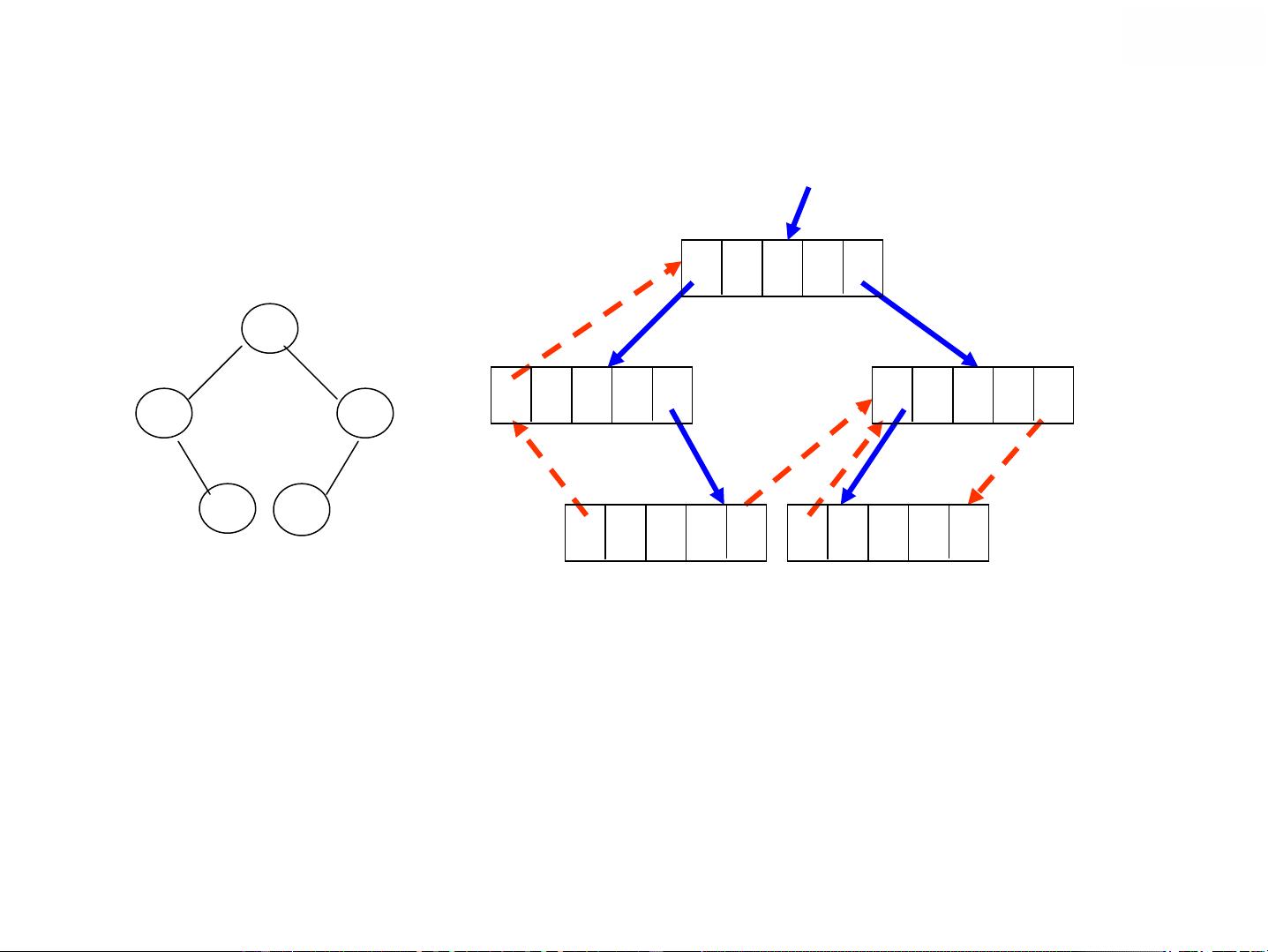
在给定的代码段中,提供了两个非递归中序遍历的算法实现。第一个算法(InorderTraverse)通过一个栈来保存待访问的结点,当遍历完左子树后,访问根结点并转向右子树。第二个算法(inorder2)同样利用栈,但使用了一个数组栈s和一个索引i来跟踪栈的状态,不断扫描左子树并将结点入栈,直到遇到空结点。当栈不为空时,出栈访问结点并转向其右子树。
这两个非递归算法的示例展示了结点的遍历过程,用图形表示了遍历的步骤,帮助理解结点如何按中序规则依次被访问。
这些内容对于理解和掌握二叉树的中序遍历至关重要,无论是递归还是非递归方法,都有助于提升对数据结构的理解和应用能力。




2010-01-06 上传
2009-11-11 上传
点击了解资源详情
2019-09-11 上传
2021-06-29 上传
2009-06-19 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情

zhangchenxin1028
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- ES管理利器:ES Head工具详解
- Layui前端UI框架压缩包:轻量级的Web界面构建利器
- WPF 字体布局问题解决方法与应用案例
- 响应式网页布局教程:CSS实现全平台适配
- Windows平台Elasticsearch 8.10.2版发布
- ICEY开源小程序:定时显示极限值提醒
- MATLAB条形图绘制指南:从入门到进阶技巧全解析
- WPF实现任务管理器进程分组逻辑教程解析
- C#编程实现显卡硬件信息的获取方法
- 前端世界核心-HTML+CSS+JS团队服务网页模板开发
- 精选SQL面试题大汇总
- Nacos Server 1.2.1在Linux系统的安装包介绍
- 易语言MySQL支持库3.0#0版全新升级与使用指南
- 快乐足球响应式网页模板:前端开发全技能秘籍
- OpenEuler4.19内核发布:国产操作系统的里程碑
- Boyue Zheng的LeetCode Python解答集
