PGCon2014:GIN索引优化:压缩 posting 列表与高效查询
需积分: 9 102 浏览量
更新于2024-07-19
收藏 124KB PDF 举报
在PGCon2014的演讲中,Heikki Linnakangas、Alexander Korotkov和Oleg Bartunov详细介绍了PostgreSQL (PG) 9.4及更高版本中的GIN (Generalized Inverted Index) 索引的两个主要改进:压缩后缀列表(Compressed Posting Lists)和搜索键组合时的跳过匹配。这些改进对于数据库性能优化具有重要意义。
首先,压缩后缀列表是第一个亮点。在9.4之前,GIN索引占用的空间较大,尤其是在处理大量重复数据时。例如,在创建名为`numbers`的表并插入10000000个数字后,9.3版本中的GIN索引占据了58MB,而9.4则将其压缩到了11MB,压缩比例高达5倍。这是通过将B-tree索引结构优化,使得每个键值的重复项只存储一次,从而节省了存储空间。
实现这一改进的关键在于GIN内部的数据结构设计。GIN本质上是一种B-tree,但其采用了更高效的方法来存储和管理数据。在压缩后缀列表中,对于具有相同前缀的值,仅记录第一个值及其出现次数,后续相同的值则只存储计数。这种做法显著减少了索引的大小,对于查询那些频繁出现的值或“罕见且频繁”模式的查询尤其有利。
第二个重大改进是搜索键组合的优化。在处理多个搜索条件时,9.4及以后版本的GIN索引能够跳过那些仅满足其中一个键但不满足其他键的项,这大大提高了在复合查询中的效率。这意味着,如果一个查询涉及到多个搜索字段,它可以在遇到第一个匹配的键后立即停止搜索,而不是继续扫描整个列表,从而减少了不必要的I/O操作和计算时间。
举例来说,当对`numbers`表进行按`n`值分组并计数的操作时,9.4版本的GIN索引因为压缩和跳过机制,使得查询结果更加高效。通过这些改进,GIN索引在9.4中不仅在存储空间上有所节省,还显著提升了执行复杂查询的速度,使得用户在处理大规模数据时可以获取更快的响应。
总结起来,PGCon2014中的GIN索引优化展示了PostgreSQL在性能和空间效率上的进步,特别是对于需要处理大量重复数据和复杂查询的应用场景。压缩后缀列表和搜索键组合优化策略是这些改进的核心,它们使得GIN索引在现代数据库环境中变得更加实用和高效。
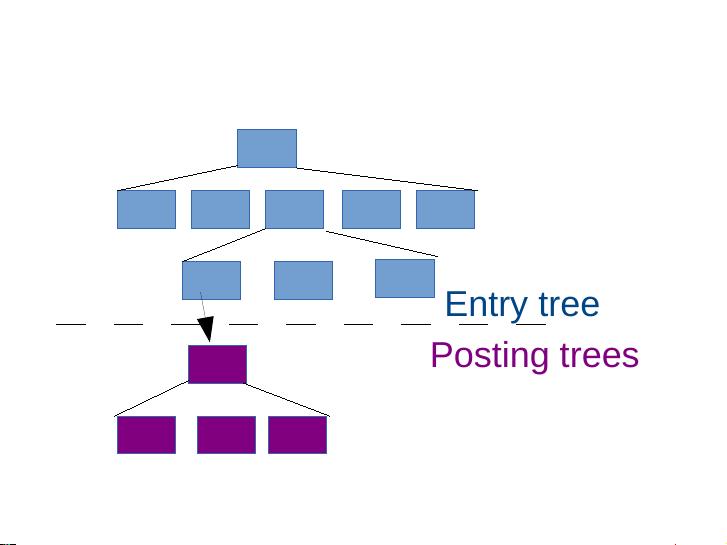
How did we achieve this?
GIN is just a B-tree, with efficient storage of duplicates.
Posting trees
Entry tree

剩余30页未读,继续阅读









