"MixMatch:半监督学习的综合方法"
需积分: 2 182 浏览量
更新于2024-02-01
收藏 3.11MB PPTX 举报
MixMatch是一篇被广泛引用的经典论文,其提出了一种新颖的半监督学习方法,通过引入一个单一的损失项将伪标签和一致性正则化方法统一于其中。该方法为未标记的数据引入了一个统一的损失项,能够无缝地降低数据的熵,并保持一致性,并且与传统的正则化技术保持兼容。
半监督学习是一种让学习器在不依赖外界交互的情况下,自动利用未标记样本来提升学习性能的方法。在少量样本标签的引导下,半监督学习能够充分利用大量无标签样本提高学习性能,避免了数据资源的浪费,并解决了有标签样本较少时监督学习方法泛化能力不强和缺少样本标签引导时无监督学习方法不准确的问题。
MixMatch是在半监督学习领域进行的研究,主要应用于图像分类任务。该论文提出了一个全面的方法来解决半监督学习中的问题。传统的半监督学习方法通常是通过使用无标签数据来扩展已有的标签数据集,并通过训练深度神经网络来学习分类模型。然而,这种方法的主要问题是无法保持数据的一致性,导致模型的泛化能力不强。
MixMatch通过引入一个单一的损失项,将伪标签和一致性正则化方法统一于其中,解决了传统方法中的不一致性问题。具体而言,MixMatch首先使用已有的标签数据进行监督训练,得到一个初始的分类模型。然后,使用该模型对未标记数据产生伪标签。接下来,MixMatch通过对已有标签数据和伪标签数据进行一致性正则化训练,来提高模型的泛化能力。最后,通过将标签数据和未标记数据进行混合,以及对特征进行扩展,进一步提升模型性能。
该方法的核心思想是通过引入一致性正则化来保持数据的一致性,并将伪标签与已有标签进行统一处理。通过对未标记数据进行伪标签预测,可以将未标记数据作为额外的训练样本来提高模型性能。同时,该方法还使用了扩展特征的技术,通过增加数据的维度来提高模型的泛化能力。
MixMatch的实验结果表明,该方法在多个图像分类任务上取得了优于现有方法的性能。同时,该方法还具有较强的鲁棒性,在标签噪声和干扰的情况下仍能保持较好的性能。此外,MixMatch还在数据资源有限的情况下表现出很好的泛化能力。
综上所述,MixMatch提出了一种全面的半监督学习方法,通过引入统一的损失项和一致性正则化技术,解决了半监督学习中标签不一致和泛化能力差的问题。该方法在图像分类任务中表现出了很好的性能,并具有一定的鲁棒性和泛化能力。
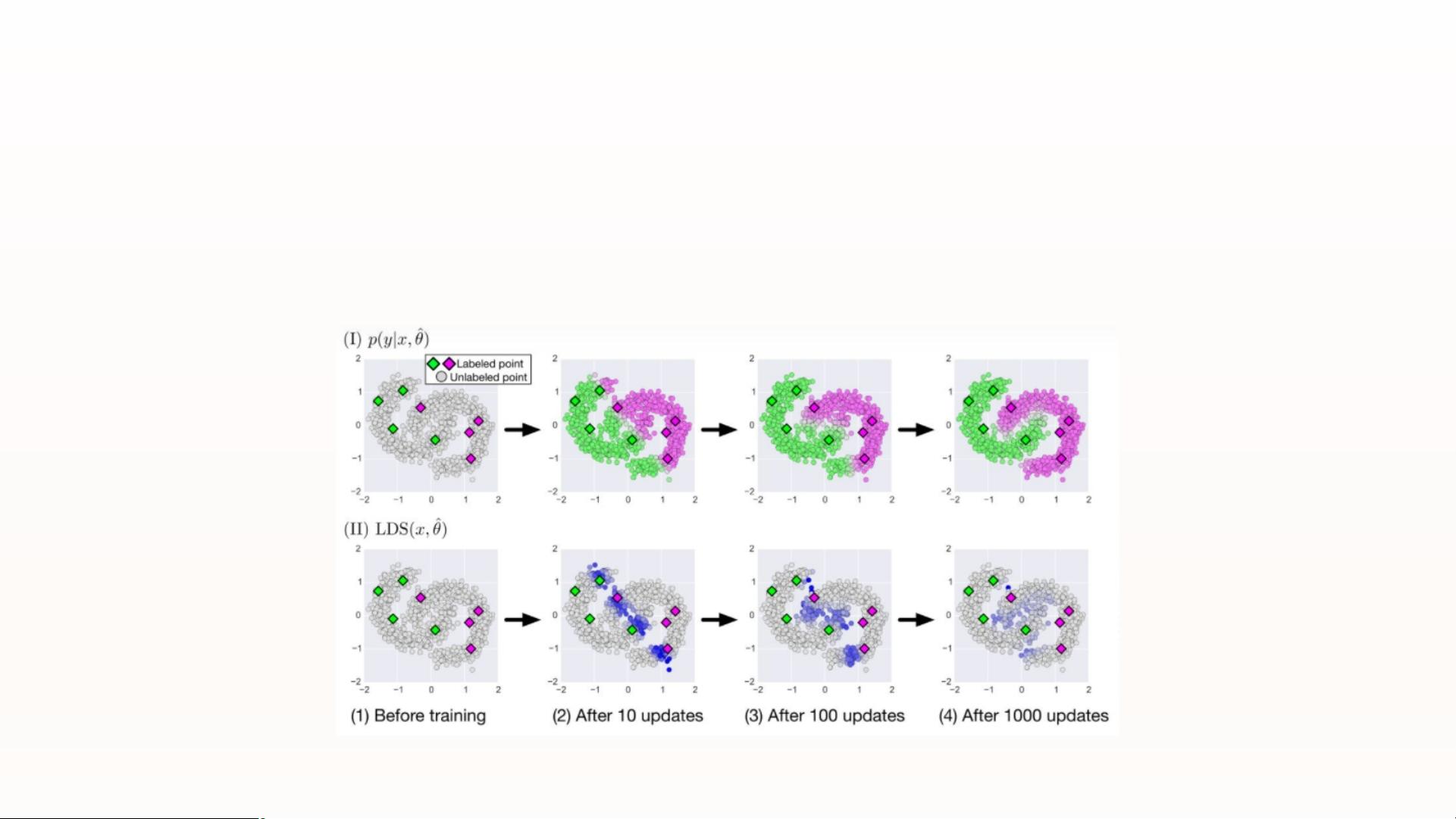
最小化熵(Entropy Minimization). 它鼓励模型对未标记的数据输出可信的预测.
在许多半监督学习方法中, 一个常见的基本假设是分类器的决策边界应该位于低密度区域, 因此, 要求分类
器对未标记的数据输出低熵预测. 熵最小化鼓励对未标记数据进行更有信心的预测, 即预测应该具有低熵,
而与ground truth无关(因为ground truth对于未标记数据是未知的). 伪标签(pseudo-labels)便是基于这种假设
的方法, 其对于未标记数据, 选择预测概率最大(或置信度最大)的标记作为样本的伪标记. 通过最小化未标
记数据的熵, 促进类之间的低密度分离. 另一个代表算法便是 VAT(Virtual Adversarial Training, 虚拟对抗
训练).
VirtualAdversarialTraining(VAT)
剩余16页未读,继续阅读
2021-04-29 上传
2019-12-20 上传
2021-05-24 上传
2021-04-16 上传
2023-10-18 上传
2021-03-22 上传
2022-06-26 上传
2019-01-24 上传

码侯烧酒
- 粉丝: 140
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- 前端协作项目:发布猜图游戏功能与待修复事项
- Spring框架REST服务开发实践指南
- ALU课设实现基础与高级运算功能
- 深入了解STK:C++音频信号处理综合工具套件
- 华中科技大学电信学院软件无线电实验资料汇总
- CGSN数据解析与集成验证工具集:Python和Shell脚本
- Java实现的远程视频会议系统开发教程
- Change-OEM: 用Java修改Windows OEM信息与Logo
- cmnd:文本到远程API的桥接平台开发
- 解决BIOS刷写错误28:PRR.exe的应用与效果
- 深度学习对抗攻击库:adversarial_robustness_toolbox 1.10.0
- Win7系统CP2102驱动下载与安装指南
- 深入理解Java中的函数式编程技巧
- GY-906 MLX90614ESF传感器模块温度采集应用资料
- Adversarial Robustness Toolbox 1.15.1 工具包安装教程
- GNU Radio的供应商中立SDR开发包:gr-sdr介绍
