Flink技术解析:打造下一代大数据实时处理平台
需积分: 10 83 浏览量
更新于2024-07-18
1
收藏 8.66MB PDF 举报
"Flink-构建下一代大数据处理引擎"
在大数据处理领域,Apache Flink被广泛认为是构建下一代处理引擎的关键技术。Flink China社区线下 Meetup·上海站的分享资料中,由巴真主讲的《Flink-构建下一代大数据处理引擎》探讨了当前数据处理的挑战与趋势,并以阿里巴巴集团的实践为例,展示了Flink如何应对这些挑战。
首先,数据趋势呈现三个主要特征:Volume(大量数据)、Velocity(快速数据流)和Variety(数据多样性)。Volume指的是数据量的爆炸性增长,从Terabytes到Petabytes,甚至达到EB级别。Velocity强调实时或近实时的数据处理需求,如每秒处理472M事件,保持亚秒级延迟。Variety则涵盖了结构化、半结构化和非结构化的数据,反映了IT化、网络化、移动化和物联网带来的数据复杂性。
阿里巴巴作为大数据处理的重要场景,每天处理着来自百万商家、3亿用户的千亿级别的交易数据,数据种类繁多,包括但不限于云存储服务如阿里云OSS和AWS S3中的各类数据。面对如此庞大的数据量和速度,阿里巴巴选择了Flink作为其数据处理的核心技术。
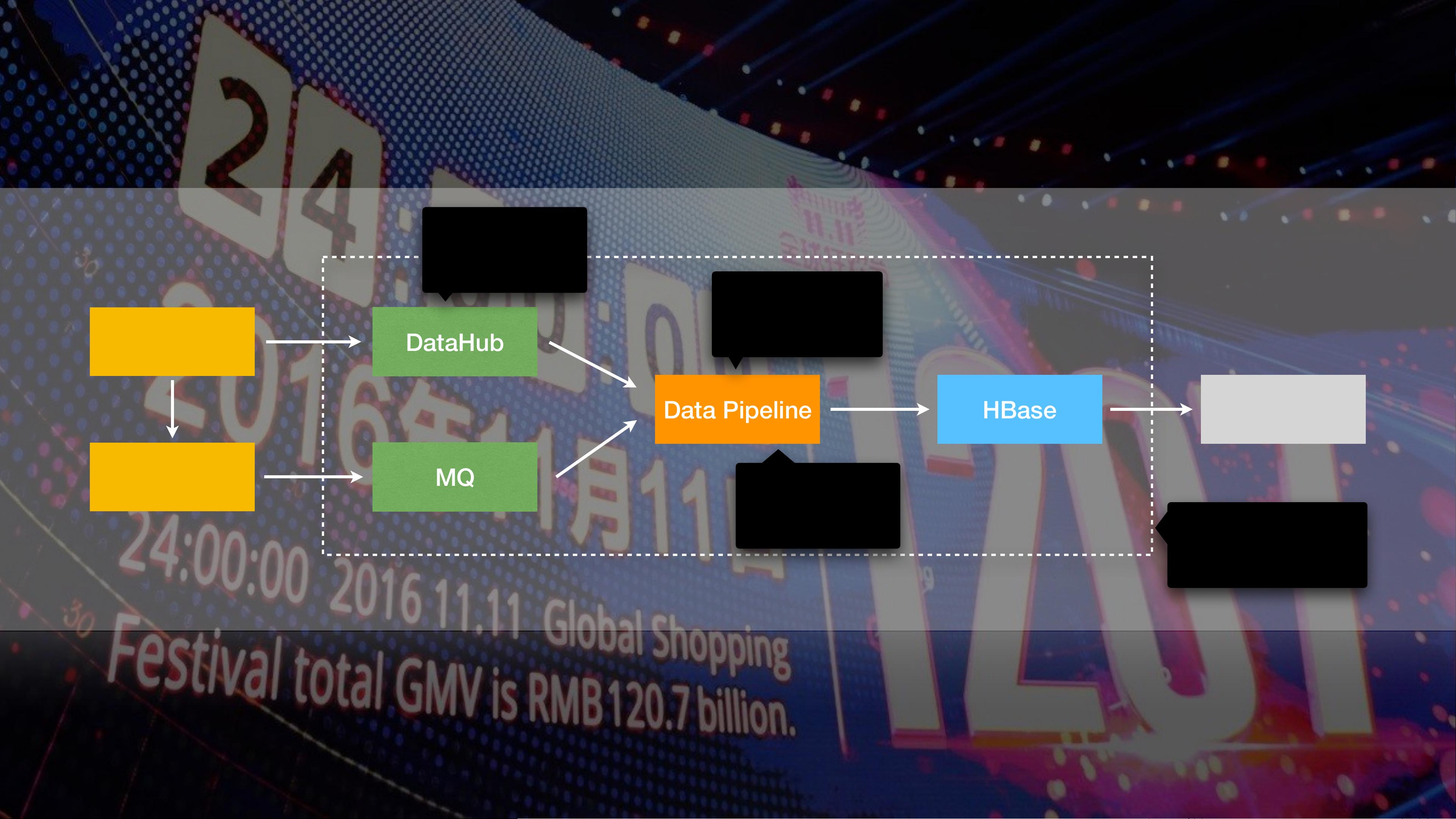
Flink提供了高吞吐量、低延迟的数据流处理能力,支持从Web层、数据库层、消息队列到DataHub、DataPipeline和HBase的数据流转,并能实现Exactly-Once的一致性保证,确保在大规模并发和故障恢复时数据的准确性。
在计算趋势方面,随着业务的复杂性和用户需求的多样化,计算任务变得碎片化,企业内部可能存在数万个数据工作者。在阿里巴巴,每个人都可能成为数据分析师,BI工程师逐渐转型为AI工程师,反映出对实时智能分析的需求增加。
阿里巴巴的业务挑战包括超大规模、超级复杂、计算多样、数据多样和用户众多。滴滴作为独角兽公司,其业务增长迅速,对计算时效性要求极高。而知乎作为一个典型的UGC(用户生成内容)平台,代表了Web2.0业务的特点。尽管这些业务的计算类型多样,但核心模型和抽象可以归纳,这为Flink提供了一体化处理的可能性。
阿里巴巴在思考如何统一处理批处理(Batch)和流处理(Stream),发现尽管业务入口多样化,但主要的计算类型只有几种。此外,尽管99%的查询可能是SQL,但也存在1%的非SQL需求。因此,阿里巴巴考虑将Flink作为统一的计算引擎,实现Batch和Stream的融合,以满足不同场景的需求。
Flink在处理大数据的Volume、Velocity和Variety方面展现出强大的优势,它不仅能够应对海量数据的实时处理,还能够处理各种类型的数据,适应不断变化的业务需求。在阿里巴巴等企业的实践中,Flink已经证明了其在构建下一代大数据处理引擎中的核心地位。

Velocity
472M events/sec Sub-second Latency
剩余41页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2019-12-03 上传
2020-10-13 上传
2021-12-08 上传
点击了解资源详情
2021-06-12 上传
2019-10-17 上传

tonnytang
- 粉丝: 0
- 资源: 8
 我的内容管理
展开
我的内容管理
展开







最新资源
- Raspberry Pi OpenCL驱动程序安装与QEMU仿真指南
- Apache RocketMQ Go客户端:全面支持与消息处理功能
- WStage平台:无线传感器网络阶段数据交互技术
- 基于Java SpringBoot和微信小程序的ssm智能仓储系统开发
- CorrectMe项目:自动更正与建议API的开发与应用
- IdeaBiz请求处理程序JAVA:自动化API调用与令牌管理
- 墨西哥面包店研讨会:介绍关键业绩指标(KPI)与评估标准
- 2014年Android音乐播放器源码学习分享
- CleverRecyclerView扩展库:滑动效果与特性增强
- 利用Python和SURF特征识别斑点猫图像
- Wurpr开源PHP MySQL包装器:安全易用且高效
- Scratch少儿编程:Kanon妹系闹钟音效素材包
- 食品分享社交应用的开发教程与功能介绍
- Cookies by lfj.io: 浏览数据智能管理与同步工具
- 掌握SSH框架与SpringMVC Hibernate集成教程
- C语言实现FFT算法及互相关性能优化指南
