




白翔分享:ICDAR2017 OCR深度讲座——场景文本检测与识别
7 浏览量
更新于2024-07-17
1
收藏 25MB PDF 举报
白翔在ICDAR2017会议上分享了深度学习在场景文本识别(SceneText Recognition)中的应用,特别是针对OCR(Optical Character Recognition,光学字符识别)领域的最新进展。讲座的主题围绕“Deep Neural Networks for SceneText Reading”,重点探讨了场景文本检测(SceneText Detection)和端到端(End-to-end)识别技术。
在讲座中,白翔首先介绍了问题定义,即在自然场景中检测和识别文本的重要性,这通常涉及到预测文本的存在并定位每个实例,比如单词或行级别的识别。场景文本的特点包括散乱、稀疏、多方向以及多语言,这些特性使得传统的文档图像OCR处理面临挑战。白翔引用了一些关键研究作为背景,如:
1. Jaderberg等人在2014年的ECCV会议上提出的深度特征用于文本定位(Deep features for text spotting);
2. 同年,Jaderberg等人在IJCV上发表了关于野外环境下使用卷积神经网络进行文本阅读的研究;
3. Huangetal在ECCV 2014年提出了一种基于卷积神经网络诱导的MSER树的鲁棒场景文本检测方法;
4. Zhangetal在CVPR上展示了基于对称性的自然场景中文本行检测技术。
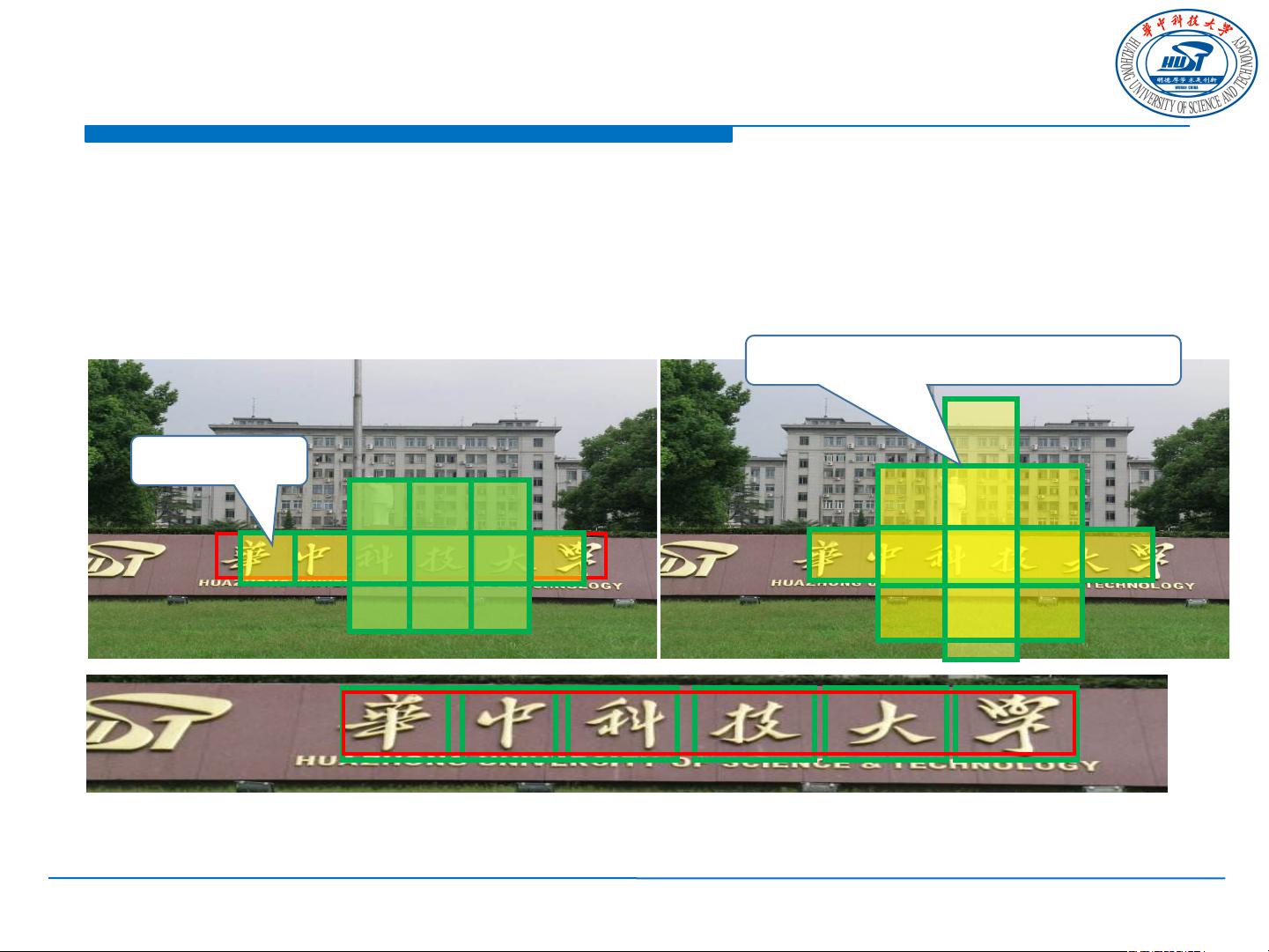
讲座进一步深入探讨了场景文本检测的方法,可能包括传统的基于模板匹配、区域提议和连接组件分析,以及现代的深度学习方法,如卷积神经网络(CNN)和循环神经网络(RNN)结合的模型,它们能够捕捉文本的复杂结构和上下文信息。在场景文本识别方面,白翔提到了从图像中直接将文本区域转换成计算机可读和编辑的符号的过程,这涉及字符级或词级的识别,并可能涉及到注意力机制来提高识别准确性和鲁棒性。
此外,讲座还讨论了应用场景,涵盖了自动驾驶、图像搜索、广告识别等多个领域,以及未来趋势,如更精确的场景文本定位、多模态信息融合、以及对低分辨率和复杂光照条件下的适应性增强。
白翔的ICDAR2017讲座提供了一个全面的视角,展示了深度学习如何推动场景文本识别技术的发展,以及如何解决现实世界中这一领域面临的诸多挑战。对于任何关注OCR和场景文本处理的从业者来说,这场讲座是不容错过的宝贵资源。

Xiang Bai, Kyoto, November 15
Performance comparison on English / Chinese datasets
(8)89%) 48#,: 8,% ;:<=01&8*#>1%9) ?%9)0@/<%89:&%
#*2"04('%1 567 8 9:; ((<=(11 '!<'
#*2"04('%/ 567 8 9:; %'''=/'' '!3%
0*>?4('%& @A968B4*;96C:C 3'1D=D((< A=66
The performance of Chinese dataset is much lower.
ICDAR 2017 Competition on Reading Chinese Text in the Wild
Link: http://mclab.eic.hust.edu.cn/icdar2017chinese/
Background

剩余64页未读,继续阅读
550 浏览量
485 浏览量
419 浏览量
1767 浏览量

波斯猫眯着它的眼睛
- 粉丝: 8
 我的内容管理
展开
我的内容管理
展开








最新资源
- 掌握Java Web文件上传下载技术
- Linux平台Oracle客户端11.2.0.3.0版本完整包
- eWebEditor 8.0 for ASP多语言官方修改版特性介绍
- J2EE图书馆管理系统开发与实现
- SOAP头信息验证实例:Web Services与客户端
- 仿新浪投票系统SinaVote的完整开发源码
- 重构粒子爆炸特效控件实现多样化效果
- Vite网络中VITE令牌交易与智能合约子图部署解析
- 58后台登录页面设计:简洁而清晰的用户体验
- 掌握JAVA开发3D坦克游戏源代码解析
- WinSocket2完成端口与多客户端压力测试
- Swift项目教程:掌握UITableView与网络访问
- Mac用户福音:Yukon 88E8056网卡驱动安装攻略
- 新型可周转墙体对拉螺杆设计文档
- 多线程网站后台扫描工具1.3版本发布:增加关键字排除功能
- 深入理解Spring:以IOC为核心的PPT学习指南






















