Apache NiFi 数据流处理指南
版权申诉
27 浏览量
更新于2024-07-16
收藏 3.45MB DOCX 举报
Apache NiFi是一个强大的数据处理工具,专为自动化数据流管理和分布而设计。它源自美国国家安全局(NSA)的项目,现在是Apache软件基金会的顶级项目,完全开源。NiFi的核心特性在于其高度可配置的可视化界面,允许用户定义复杂的数据路由、转换和逻辑流程,以适应多种数据源和目标。
NiFi的基础概念包括:
1. FlowFile:这是NiFi中的基本数据单位,包含了数据流的所有属性。FlowFile不仅携带数据,还记录了元数据信息。
2. Processor(处理器):处理器是NiFi的核心组件,执行实际的数据处理任务。用户可以根据需求选择和配置不同的处理器来完成数据转换、过滤、解析等操作。
3. Connection(连接线):连接线用于不同处理器之间的通信,作为数据传输的缓冲区,确保数据在处理器之间流动的顺畅性。
4. FlowController(流量控制器):管理NiFi运行时的线程分配和任务调度,保证系统的高效运行。
5. ProcessGroup(过程组):过程组是处理器和连接线的集合,可以形成一个逻辑单元,方便组织和管理复杂的流程。
NiFi的架构基于Java,采用Maven进行依赖管理。在主机的操作系统上,NiFi运行在一个JVM中,主要组件包括:
1. 网络服务器:负责托管HTTP命令和控制API,提供Web界面供用户交互。
2. 流控制器:是NiFi的中枢,管理线程调度和资源分配,确保数据流程按预定规则运行。
3. 扩展:NiFi支持多种可扩展组件,如处理器、控制器服务等,这些组件在JVM中执行,提供丰富的功能。
4. FlowFile存储库:存储当前处于流程中的FlowFile的状态信息,保证数据流动的可追溯性。
5. 内容存储库:存储FlowFile的实际内容,支持多种存储策略,如默认的简单文件系统存储。
6. 来源存储库(Provenance Repository):记录所有操作事件,提供数据来源的审计和追踪能力。
NiFi的这些特性使其成为数据集成、ETL(提取、转换、加载)和实时数据处理的理想选择,能够处理从低速传感器数据到高速流式数据的各种场景。此外,NiFi还具有健壮的容错性和可扩展性,可以轻松地处理大规模的数据流。通过配置和组合不同组件,用户可以构建出适应不同业务需求的数据处理流程,实现数据的高效管理和利用。

10
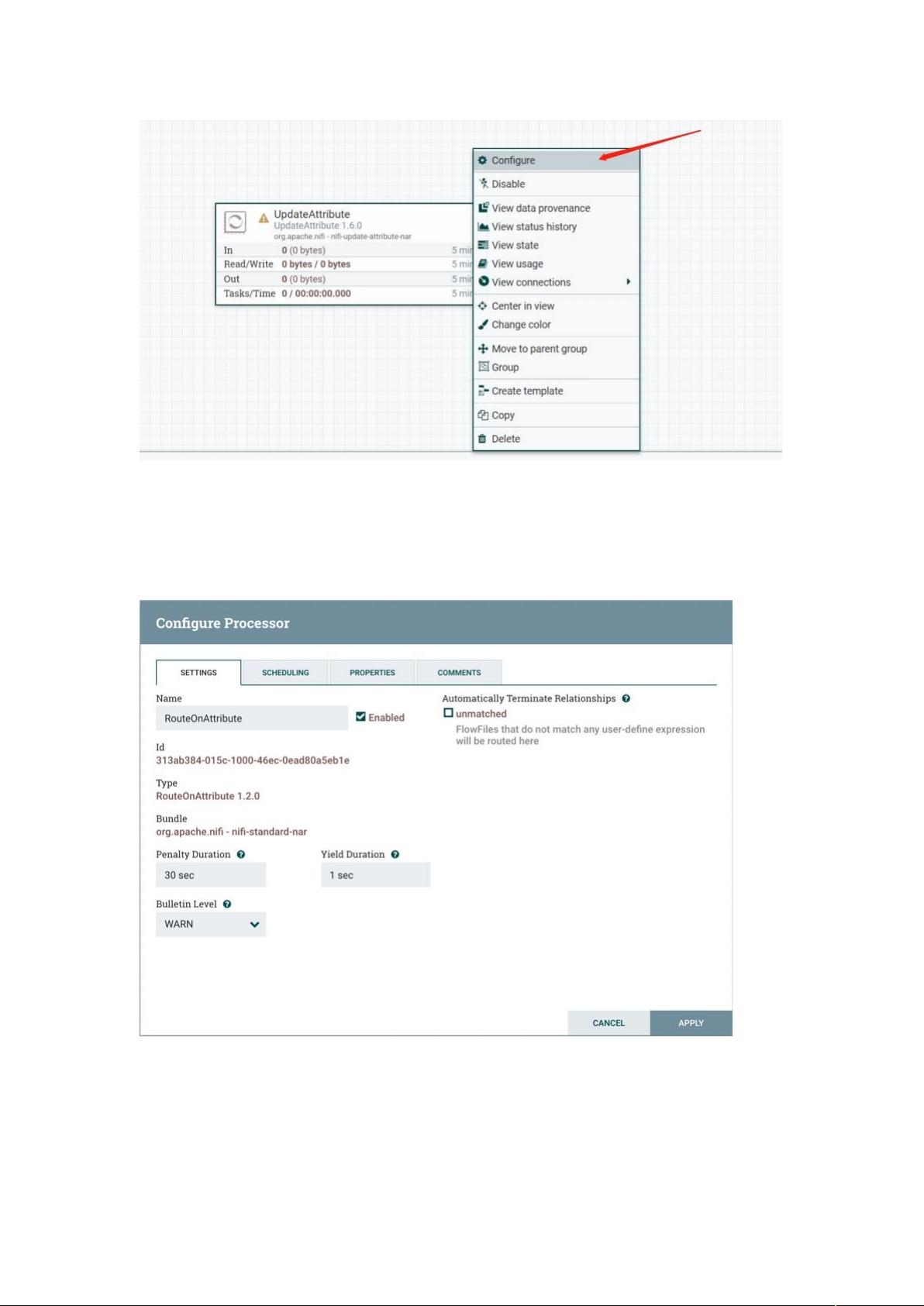
将处理器拖到画布上后,可以通过右键单击处理器并从上下文菜单中选择一个选项来与其
进行交互。根据分配给您的权限,上下文菜单中可用的选项会有所不同。
虽然上下文菜单中的选项有所不同,但是当您具有使用处理器的完全权限时,通常可以使
用以下选项:
:!-90%(配置):此选项允许用户建立或更改处理器的配置。
:"%"(启动或停止):此选项允许用户启动或停止处理器 J该选项可以是 "%" 或
",具体取决于处理器的当前状态。
:+$(启用或禁用):此选项允许用户启用或启用处理器J该选项将为“启用”或“禁用”,

剩余63页未读,继续阅读
143 浏览量
310 浏览量
412 浏览量
485 浏览量
点击了解资源详情
点击了解资源详情
126 浏览量
2025-03-13 上传
2025-03-13 上传

theuzi
- 粉丝: 52
 我的内容管理
展开
我的内容管理
展开







最新资源
- 多技术领域源码集锦:园林绿化官网企业项目
- 定制特色井字游戏Tic Tac Toe开源发布
- TechNowHorse:Python 3编写的跨平台RAT生成器
- VB.NET实现程序自动更新的模块设计与应用
- ImportREC:强大输入表修复工具的介绍
- 高效处理文件名后缀:脚本批量添加与移除教程
- 乐phone 3GW100体验版ROM深度解析与优化
- Rust打造的cursive_table_view终端UI组件
- 安装Oracle必备组件libaio-devel-0.3.105-2下载
- 探索认知语言连接AI的开源实践
- 微软SAPI5.4实现的TTSApp语音合成软件教程
- 双侧布局日历与时间显示技术解析
- Vue与Echarts结合实现H5数据可视化
- KataSuperHeroesKotlin:提升Android开发者的Kotlin UI测试技能
- 正方安卓成绩查询系统:轻松获取课程与成绩
- 微信小程序在保险行业的应用设计与开发资源包
