HBase技术详解:从入门到实践
需积分: 10 27 浏览量
更新于2024-07-25
收藏 1.7MB PDF 举报
"HBase入门与使用"
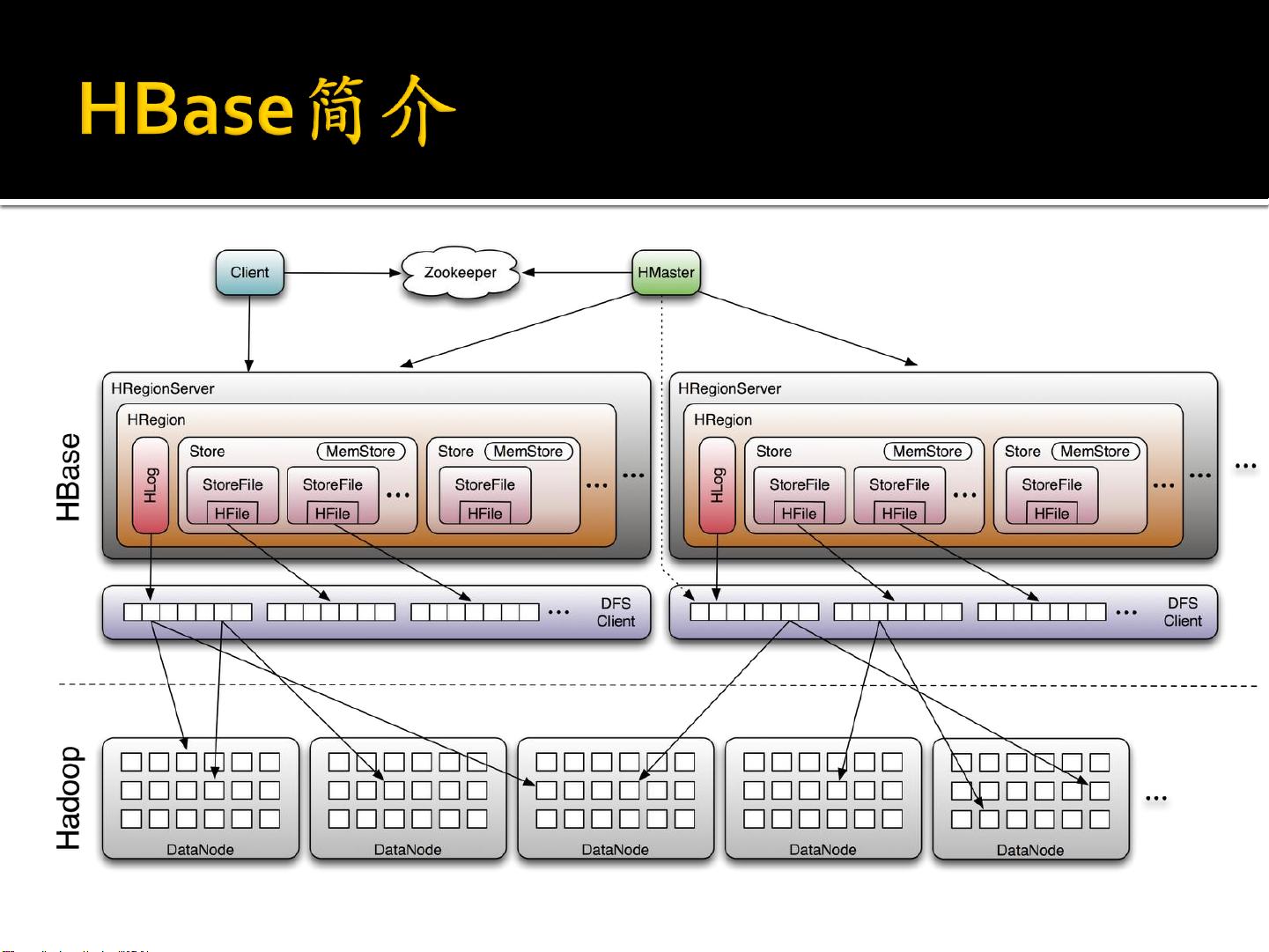
HBase是一款开源的分布式数据库,它是基于Google的Bigtable设计灵感构建的,主要用于处理大规模数据集。HBase属于NoSQL数据库中的列族(Column-Family)模型,它在Apache Hadoop生态系统中运行,利用HDFS作为底层的数据存储系统。HBase的主要贡献者包括Yahoo!, Facebook, 和Cloudera等公司。
在HBase中,数据被组织成表格形式,由 TableName 和 ColumnFamilyName 定义其结构。每个ColumnFamily可以包含多个ColumnLabel,每个ColumnLabel下又有多个ColumnQualifier,用于区分不同的列。例如,一个用户信息表可能有`name`和`contact`两个ColumnFamily,分别包含`firstname`、`lastname`、`nickname`、`email`和`phone`等列。
表格的管理是按Region进行的,每个Region有一个起始Key(startKey)和结束Key(endKey)。当某个ColumnFamily的数据量达到预设阈值时,Region会自动分裂成两个新的Region,以保持数据的均衡分布。RegionServer是实际执行读写操作的地方,它负责管理这些Region。
Master节点在HBase中扮演着重要角色,它负责Region的分配,监控RegionServer的状态,并在必要时进行Region的平衡操作。此外,Master节点还依赖Zookeeper实现高可用性,确保系统的稳定运行。
HDFS是HBase的基础存储层,所有的数据和日志都会被保存在HDFS上。HBase提供了强一致性保证,同一行数据的读写都在同一个RegionServer上完成,确保了数据的一致性。同时,HBase支持水平扩展,通过添加更多的DataNode机器来增加存储容量,通过增加RegionServer机器来提升读写性能。
HBase支持行级事务,意味着同一行内的列更新是原子性的。其数据结构采用ColumnOriented的方式,以三维有序的形式存储,即按RowKey升序、ColumnLabel升序和Timestamp降序排序,这样的设计有利于高效的数据查询和扫描操作。
扫描(Scan)是HBase提供的一种查询机制,允许用户进行范围查询,获取满足特定条件的一系列行或列。这种能力使得HBase在大数据分析场景下表现得非常高效,能够快速地处理大量数据的读取需求。
HBase是一个适合处理大规模、稀疏数据的高性能数据库,尤其适用于实时读写和大数据分析的场景。其设计理念和特性使其成为大数据领域的关键组件之一。
剩余28页未读,继续阅读
2019-01-16 上传
2021-09-04 上传
2021-01-20 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

侯上校
- 粉丝: 26
- 资源: 93
 我的内容管理
展开
我的内容管理
展开







最新资源
- C++ Qt影院票务系统源码发布,代码稳定,高分毕业设计首选
- 纯CSS3实现逼真火焰手提灯动画效果
- Java编程基础课后练习答案解析
- typescript-atomizer: Atom 插件实现 TypeScript 语言与工具支持
- 51单片机项目源码分享:课程设计与毕设实践
- Qt画图程序实战:多文档与单文档示例解析
- 全屏H5圆圈缩放矩阵动画背景特效实现
- C#实现的手机触摸板服务端应用
- 数据结构与算法学习资源压缩包介绍
- stream-notifier: 简化Node.js流错误与成功通知方案
- 网页表格选择导出Excel的jQuery实例教程
- Prj19购物车系统项目压缩包解析
- 数据结构与算法学习实践指南
- Qt5实现A*寻路算法:结合C++和GUI
- terser-brunch:现代JavaScript文件压缩工具
- 掌握Power BI导出明细数据的操作指南
