Brew平台HelloKitty实现教程:从零到胜利的完整步骤
下载需积分: 9 | DOC格式 | 1.4MB |
更新于2024-07-31
| 61 浏览量 | 举报
本文档详细介绍了在BREW平台上实现Hello Kitty应用的步骤,针对初学者面临的挑战和困惑,作者分享了自己从零开始的实践经验。首先,作者强调了在初期阶段寻找资料的困难,大部分教程缺乏完整且易于跟随的步骤,导致新手在尝试过程中多次遭遇挫折。为了克服这个问题,作者将多篇教程整合,并结合个人摸索,逐步完成了Hello Kitty的实现。
以下是实现过程的关键步骤:
1. 环境准备:
- 安装必要的软件:包括Visual Studio(如VC6.0),BREW SDK 3.1.5,Arm Compiler 1.2(注意安装路径不能包含空格或中文),BREW Addins(不确定具体版本,通常通过网页文件安装),BREWSDKTOOLS和BREWTOOLSUITE,以及模拟器配置工具。
- 安装顺序至关重要,推荐按照vc编译器、SDK和其他工具的顺序安装。
2. 创建工程:
- 使用VC6.0创建新工程,选择"工程—>BREWApplication Wizard",工程命名为HelloKitty,放置在SDK的examples文件夹内。
3. 项目设置:
- 配置项目属性,确保与BREW平台兼容,可能需要调整编译选项和链接器设置。
4. 编写代码:
- 由于文章提到Hello Kitty是因为Hello World示例已预装在SDK中,所以主要任务可能是了解并修改预设的Hello World程序,加入Hello Kitty的图形元素。
5. 调试与问题解决:
- 在编码过程中,可能会遇到各种问题,如编译错误、连接错误等。这时需要细心阅读错误信息,查找解决方案,或者参考网络上的相关论坛和社区,寻求帮助。
6. 模拟器测试:
- 完成编码后,在模拟器上运行应用,验证Hello Kitty是否正常显示,根据反馈调整代码。
7. 总结与分享:
- 成功实现Hello Kitty后,作者鼓励其他新手不要轻易放弃,分享自己的经验,以帮助后来者避免重复踩坑。
在整个过程中,作者表达了对提供资料的网友,特别是"野味"和"嘎子"的感激之情,同时也提醒读者尊重知识产权,不要滥用他人的成果。这篇文章不仅是一份实用的教程,也是一篇充满挫折与坚持的心得体会,对于想要学习BREW平台的开发者来说,具有很高的参考价值。
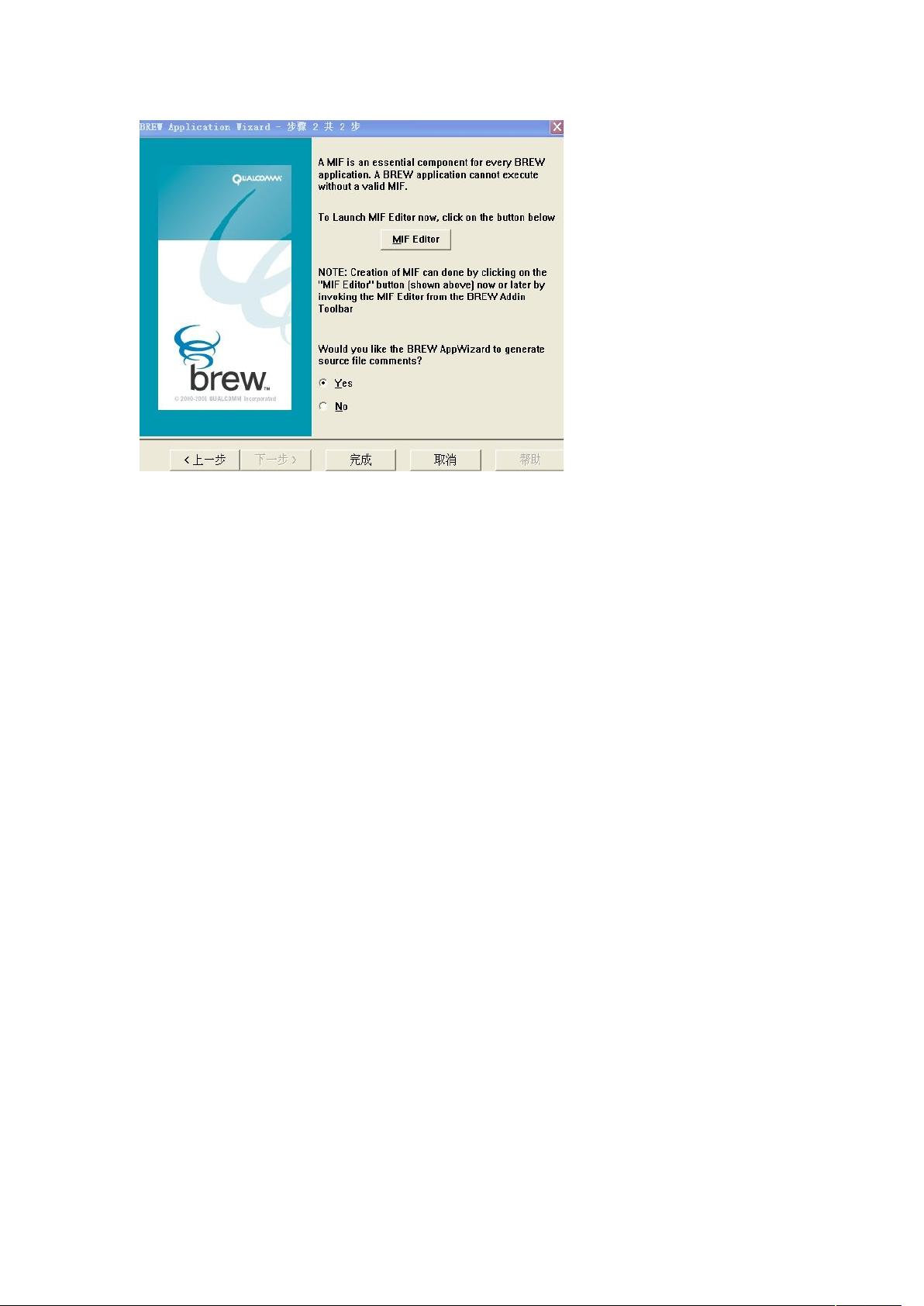
上图中的 3&4' 按钮就是打开 3&4 编辑器的了,先不管,后面再来处理也一样,点完
成。(其实,现在点击也没反应,好像我有哪里没安装好,一开始时点击是有反应的,会
跳出 3&4 编辑器的)
3、环境变量的设置
(这一步出现的两个问题,我忘了顺序了,反正这两步都是要设置的,顺序就
随便吧)
3.1 回到 vc6.0,点编译、链接
第一个问题出现了:大概是找不到 AEEAppGen.h 什么的
解决方法:在 里,工具—)选项—)目录,目录那个框框里选 &+15/,然后
再下面的路径里添加如下 条路径:
0$#''67$8$$'37%'
0$#''67$8$$&(
0$1!$$/2$+
就是 安装包里 文件夹里面的 .*!/、9+、+ 三个文件夹。注意,你的
的安装位置和我的不一定相同,要找你的 的安装位置。
剩余15页未读,继续阅读
相关推荐




zouzf1
- 粉丝: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- C#实现自定义尺寸条形码和二维码生成工具
- Bootthink多系统引导程序成功安装经验分享
- 朗读女中文朗读器,智能语音朗读体验
- Jupyter Notebook项目培训教程
- JDK8无限强度权限策略文件8下载指南
- Navicat for MySQL工具压缩包介绍
- Spring和Quartz集成教程:定时任务解决方案
- 2013百度百科史记全屏效果的fullPage实现
- MATLAB开发电磁转矩电机瞬态响应研究
- 安卓系统短信问题解决方案:使用BlurEmailEngine修复
- 不同版本Android系统的Xposed框架安装指南
- JavaScript项目实验:模拟骰子与颜色转换器
- 封装高效滑动Tab动画技术解析
- 粒子群优化算法在Matlab中的开发与应用
- 网页图书翻页效果实现与turnjs4插件应用
- JSW: 一种新型的JavaScript语法,支持Coffeescript风格
