ALBERT:轻量级BERT模型优化自然语言理解
版权申诉
142 浏览量
更新于2024-07-04
收藏 409KB PDF 举报
"NLP:自然语言理解ALBERT.pdf"
ALBERT(A Lite BERT)是BERT(Bidirectional Encoder Representations from Transformers)的一个轻量级版本,设计用于自我监督学习语言表示。该模型针对预训练自然语言表示模型在增大规模时遇到的内存限制和训练时间过长的问题提出了解决方案。
在论文《ALBERT: A Lite BERT for Self-Supervised Learning of Language Representations》中,作者Zhenzhong Lan等人展示了如何通过两种参数裁剪技术减少BERT的内存消耗,并提高训练效率。这两种技术分别是:
1. 分解Embedding参数:传统的BERT模型中,每个单词都对应一个固定的向量表示,即Embedding。ALBERT则引入了因子分解,将较大的向量分解为两个较小的向量,降低了参数量,同时保持了信息的完整性。
2. 跨层参数共享:在ALBERT中,不同层之间的部分参数被共享,这意味着同一层的不同位置可以使用相同的参数,减少了模型的总体参数数量,但不会显著影响模型的表现。
除了参数减少的技术,ALBERT还引入了一种自我监督损失,专注于建模句子间的连贯性。这种损失函数有助于处理包含多句子输入的任务,增强了模型对上下文关系的理解,从而在下游任务中表现出更好的性能。
通过这些创新,ALBERT模型能够在不牺牲太多性能的情况下,实现更高效、更节省资源的训练。实验证明,与原始的BERT相比,ALBERT的扩展性显著提高,其最佳模型在多项下游任务上创下了新的状态-of-the-art结果。这一成果是在ICLR 2020会议上发表的,表明ALBERT在自然语言处理领域提供了一个有效且高效的解决方案,对于处理大规模文本数据和提高模型的泛化能力具有重要意义。
Published as a conference paper at ICLR 2020
V × E. This can easily result in a model with billions of parameters, most of which are only updated
sparsely during training.
Therefore, for ALBERT we use a factorization of the embedding parameters, decomposing them
into two smaller matrices. Instead of projecting the one-hot vectors directly into the hidden space of
size H, we first project them into a lower dimensional embedding space of size E, and then project
it to the hidden space. By using this decomposition, we reduce the embedding parameters from
O(V × H) to O(V × E + E × H). This parameter reduction is significant when H E. We
choose to use the same E for all word pieces because they are much more evenly distributed across
documents compared to whole-word embedding, where having different embedding size (Grave
et al. (2017); Baevski & Auli (2018); Dai et al. (2019) ) for different words is important.
Cross-layer parameter sharing. For ALBERT, we propose cross-layer parameter sharing as an-
other way to improve parameter efficiency. There are multiple ways to share parameters, e.g., only
sharing feed-forward network (FFN) parameters across layers, or only sharing attention parameters.
The default decision for ALBERT is to share all parameters across layers. All our experiments
use this default decision unless otherwise specified. We compare this design decision against other
strategies in our experiments in Sec. 4.5.
Similar strategies have been explored by Dehghani et al. (2018) (Universal Transformer, UT) and
Bai et al. (2019) (Deep Equilibrium Models, DQE) for Transformer networks. Different from our
observations, Dehghani et al. (2018) show that UT outperforms a vanilla Transformer. Bai et al.
(2019) show that their DQEs reach an equilibrium point for which the input and output embedding
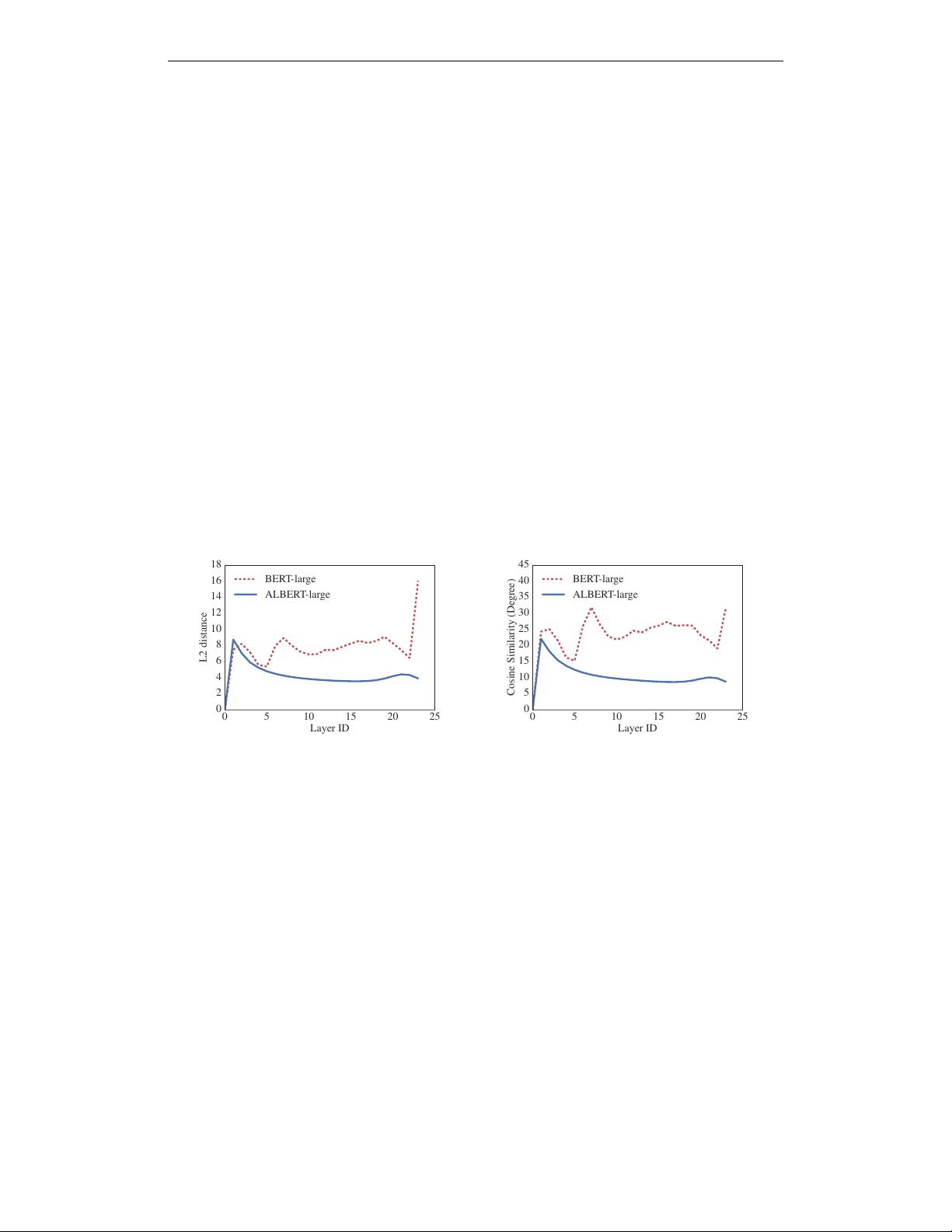
of a certain layer stay the same. Our measurement on the L2 distances and cosine similarity show
that our embeddings are oscillating rather than converging.
0 5 10 15 20 25
Layer ID
0
2
4
6
8
10
12
14
16
18
L2 distance
BERT-large
ALBERT-large
0 5 10 15 20 25
Layer ID
0
5
10
15
20
25
30
35
40
45
Cosine Similarity (Degree)
BERT-large
ALBERT-large
Figure 1: The L2 distances and cosine similarity (in terms of degree) of the input and output embed-
ding of each layer for BERT-large and ALBERT-large.
Figure 1 shows the L2 distances and cosine similarity of the input and output embeddings for each
layer, using BERT-large and ALBERT-large configurations (see Table 1). We observe that the tran-
sitions from layer to layer are much smoother for ALBERT than for BERT. These results show that
weight-sharing has an effect on stabilizing network parameters. Although there is a drop for both
metrics compared to BERT, they nevertheless do not converge to 0 even after 24 layers. This shows
that the solution space for ALBERT parameters is very different from the one found by DQE.
Inter-sentence coherence loss. In addition to the masked language modeling (MLM) loss (De-
vlin et al., 2019), BERT uses an additional loss called next-sentence prediction (NSP). NSP is a
binary classification loss for predicting whether two segments appear consecutively in the original
text, as follows: positive examples are created by taking consecutive segments from the training
corpus; negative examples are created by pairing segments from different documents; positive and
negative examples are sampled with equal probability. The NSP objective was designed to improve
performance on downstream tasks, such as natural language inference, that require reasoning about
the relationship between sentence pairs. However, subsequent studies (Yang et al., 2019; Liu et al.,
2019) found NSP’s impact unreliable and decided to eliminate it, a decision supported by an im-
provement in downstream task performance across several tasks.
We conjecture that the main reason behind NSP’s ineffectiveness is its lack of difficulty as a task,
as compared to MLM. As formulated, NSP conflates topic prediction and coherence prediction in a
4
剩余16页未读,继续阅读
2021-09-01 上传
2021-04-10 上传
2021-05-22 上传
2019-10-20 上传
2023-09-07 上传
2023-08-12 上传
2019-11-28 上传
2023-08-05 上传
2023-04-20 上传

方案互联
- 粉丝: 18
- 资源: 926
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言数组操作:高度检查器编程实践
- 基于Swift开发的嘉定单车LBS iOS应用项目解析
- 钗头凤声乐表演的二度创作分析报告
- 分布式数据库特训营全套教程资料
- JavaScript开发者Robert Bindar的博客平台
- MATLAB投影寻踪代码教程及文件解压缩指南
- HTML5拖放实现的RPSLS游戏教程
- HT://Dig引擎接口,Ampoliros开源模块应用
- 全面探测服务器性能与PHP环境的iprober PHP探针v0.024
- 新版提醒应用v2:基于MongoDB的数据存储
- 《我的世界》东方大陆1.12.2材质包深度体验
- Hypercore Promisifier: JavaScript中的回调转换为Promise包装器
- 探索开源项目Artifice:Slyme脚本与技巧游戏
- Matlab机器人学习代码解析与笔记分享
- 查尔默斯大学计算物理作业HP2解析
- GitHub问题管理新工具:GIRA-crx插件介绍
