SQL Server表锁定机制详解:确保数据一致性的关键
142 浏览量
更新于2024-08-27
收藏 675KB PDF 举报
SQLServer数据库表锁定原理是关系数据库管理中关键的概念,特别是在高并发的C/S(客户/服务器)和B/S(浏览器/服务器)架构中,确保数据的一致性和完整性至关重要。以下是对这一主题的深入解析:
1. **多用户环境下的数据一致性挑战**
在C/S和B/S结构中,大量的并发用户同时访问数据库,可能导致数据不一致性和读取脏数据。为了防止这种问题,SQLServer引入了事务的ACID原则(原子性、一致性、隔离性和持久性),通过锁定机制确保并发操作的正确执行。
2. **SQLServer中的锁定机制**
- **锁定资源**:SQLServer支持对各种资源进行锁定,包括表、索引、页和行。这些锁定对象的选择取决于事务的操作需求。
- **锁的粒度**:粒度包括表锁(全表锁定)、页锁(部分数据锁定)和行锁(最小粒度锁定,减少锁冲突)。
- **锁的升级与自动控制**:在某些情况下,系统会自动升级锁的粒度,以避免死锁,用户无需手动干预。
- **锁的类型**:
- 共享锁(S):允许读取数据,但禁止写入。
- 修改锁(M):在修改操作中使用,避免共享锁导致的死锁。
- 独占锁(X):完全锁定,禁止其他事务读取或修改。
- 架构锁(Sch-M和Sch-S):用于特定的数据库对象操作。
- 意向锁:表明事务可能需要获取某种类型的锁。
- 批量修改锁:用于大规模数据复制。
3. **SQLServer特定的锁类型**:
- HOLDLOCK:保持共享锁直至事务结束,增强一致性。
- NOLOCK:不保证数据一致性,适合读取大量数据或性能优先的场景。
- PAGLOCK:选择性地锁定页面而非整表。
- 隔离级别锁:如READCOMMITTED、READPAST、READUNCOMMITTED、REPEATABLEREAD和ROWLOCK,提供不同级别的并发控制。
总结来说,SQLServer的表锁定原理是通过一系列策略和机制来管理并发访问,确保数据的一致性和避免数据冲突。理解这些原理对于开发人员优化数据库性能、设计高效并发应用和处理潜在的并发问题至关重要。
SQLServer数据库表锁定原理数据库表锁定原理
1. 数据库表锁定原理
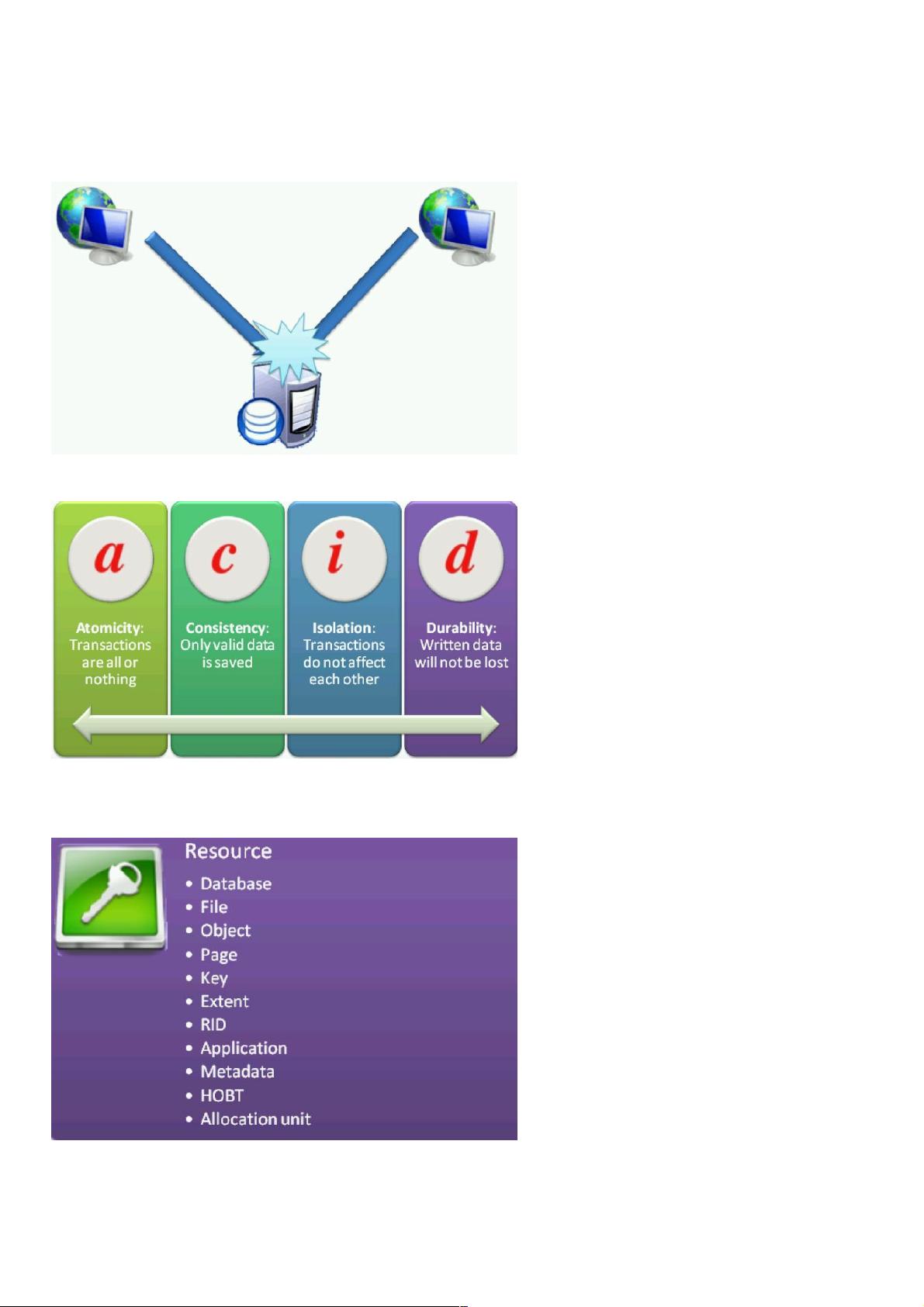
1.1 目前的C/S,B/S结构都是多用户访问数据库,每个时间点会有成千上万个user来访问DB,其中也会同时存取同一份数据,会
造成数据的不一致性或者读脏数据。
1.2 事务的ACID原则
1.3 锁是关系数据库很重要的一部分, 数据库必须有锁的机制来确保数据的完整和一致性。
1.3.1 SQL Server中可以锁定的资源:
1.3.2 锁的粒度:
下载后可阅读完整内容,剩余6页未读,立即下载
2020-12-14 上传
2022-06-03 上传
2009-04-25 上传
2014-06-06 上传
2008-12-03 上传
2020-09-14 上传
2012-05-01 上传

weixin_38677255
- 粉丝: 6
- 资源: 930
 我的内容管理
展开
我的内容管理
展开







最新资源
- CoreOS部署神器:configdrive_creator脚本详解
- 探索CCR-Studio.github.io: JavaScript的前沿实践平台
- RapidMatter:Web企业架构设计即服务应用平台
- 电影数据整合:ETL过程与数据库加载实现
- R语言文本分析工作坊资源库详细介绍
- QML小程序实现风车旋转动画教程
- Magento小部件字段验证扩展功能实现
- Flutter入门项目:my_stock应用程序开发指南
- React项目引导:快速构建、测试与部署
- 利用物联网智能技术提升设备安全
- 软件工程师校招笔试题-编程面试大学完整学习计划
- Node.js跨平台JavaScript运行时环境介绍
- 使用护照js和Google Outh的身份验证器教程
- PHP基础教程:掌握PHP编程语言
- Wheel:Vim/Neovim高效缓冲区管理与导航插件
- 在英特尔NUC5i5RYK上安装并优化Kodi运行环境
