Twitter Storm:实时大数据流处理技术解析
需积分: 13 123 浏览量
更新于2024-07-15
收藏 3.88MB PDF 举报
"Storm @Twitter-Slides.pdf 是一篇关于大数据流处理的重要论文的PPT,由Karthik Ramanasamy等人在Twitter上提出。这篇论文深入介绍了Storm平台,一个用于实时数据分析的流处理系统,它允许用户对数据进行即时反应。"
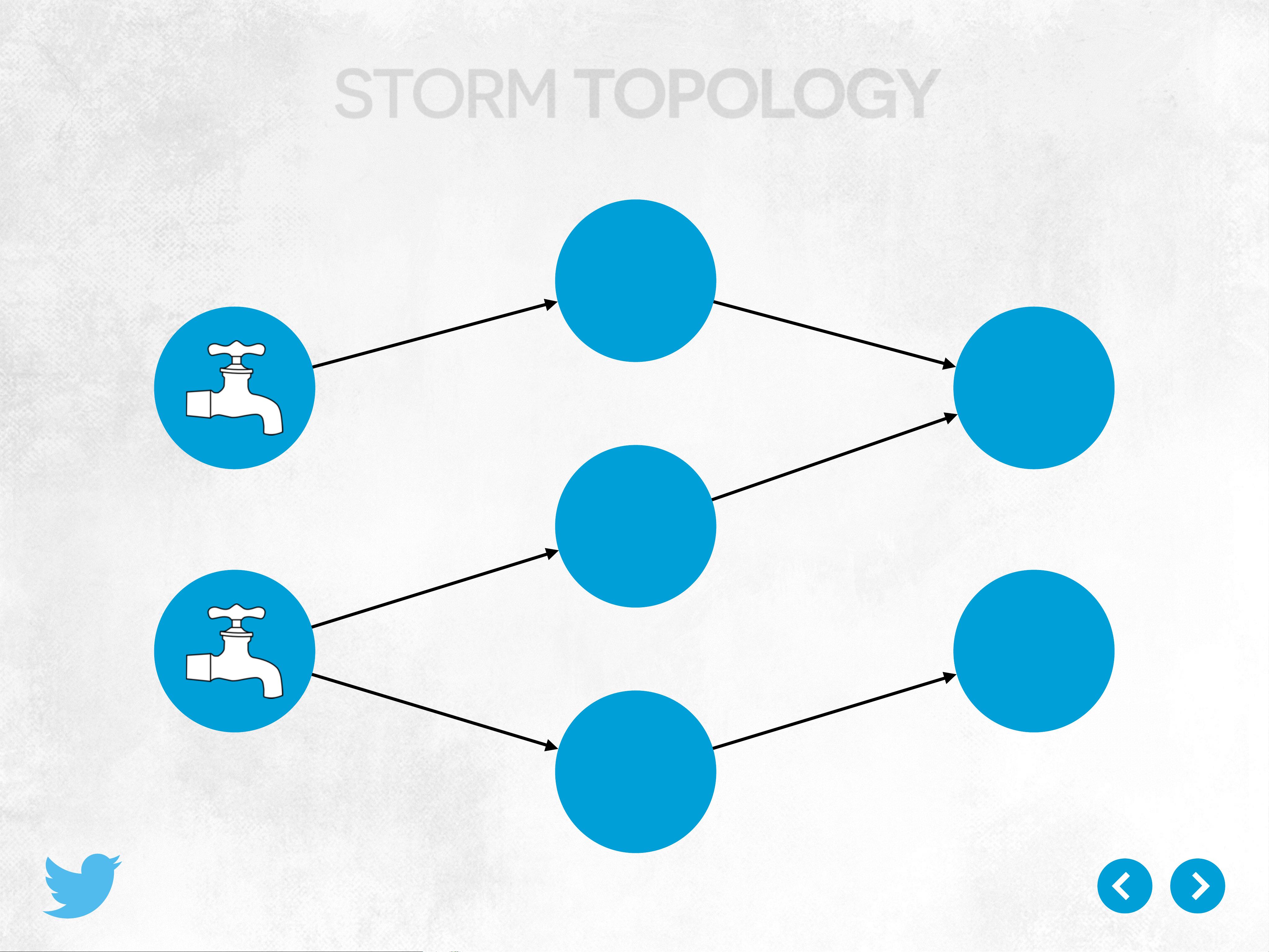
Storm是大数据处理领域中的一个关键组件,其主要特点包括保证消息处理(Guaranteed Message Processing)、水平扩展性(Horizontal Scalability)、健壮的容错机制(Robust Fault Tolerance)以及简洁的代码结构,使开发者能够专注于业务逻辑。Storm的核心概念是一个有向无环图(DAG),即拓扑结构,由计算节点(Spouts)和处理节点(Bolts)组成。
1. **Spouts**:Spouts是拓扑中的数据源,它们负责生成数据元组(tuples)。这些数据可以来源于各种来源,如Kafka、Kestrel、MySQL或Postgres等。例如,在一个Twitter相关的例子中,Spout可能是一个从Twitter API获取实时推文的组件。
2. **Bolts**:Bolts则负责处理Spout产生的数据,执行过滤、聚合、连接或其他任意函数。例如,`ParseTweetBolt`可能解析接收到的推文并提取关键词。
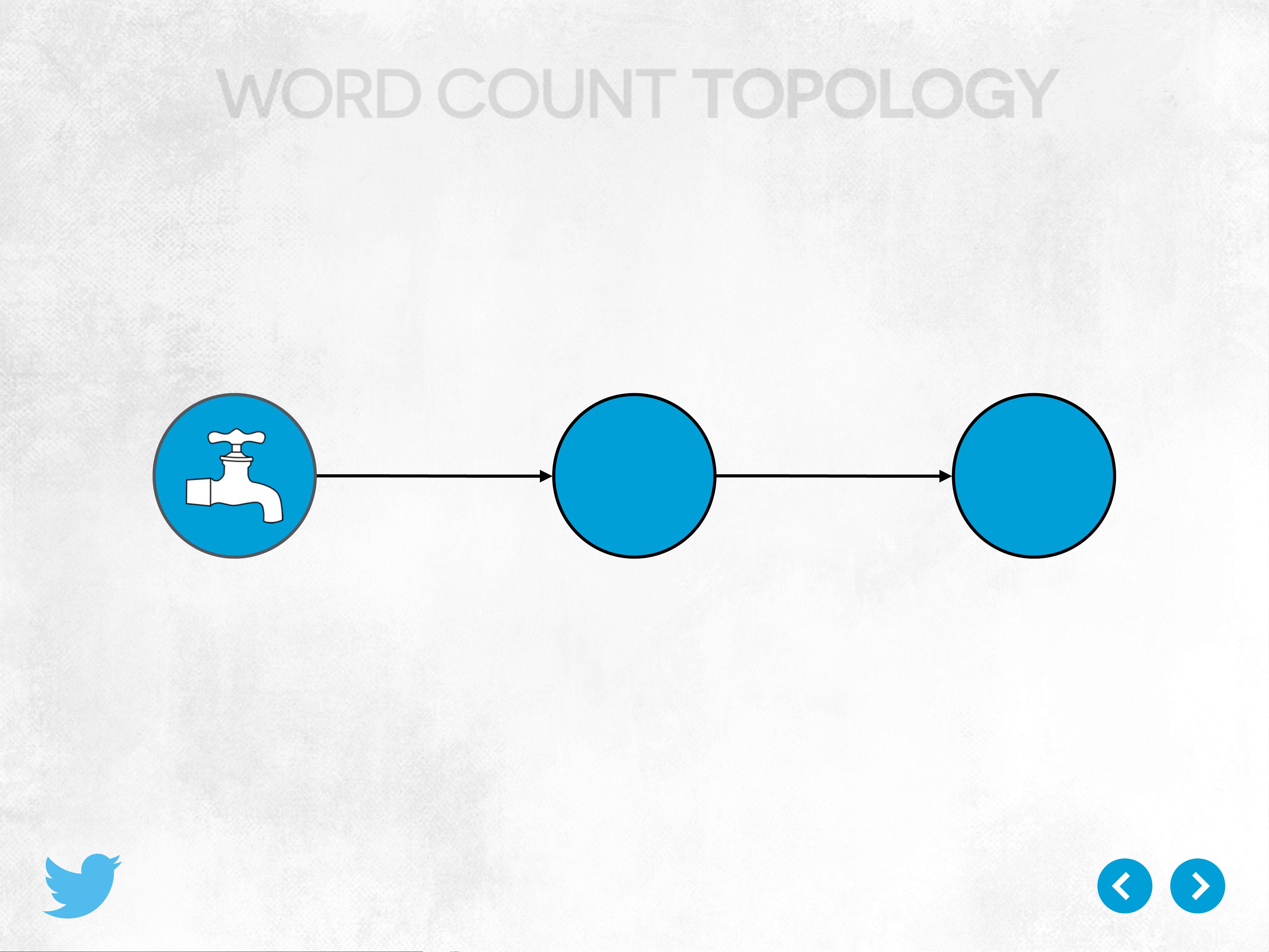
3. **拓扑(Topology)**:拓扑定义了数据流如何在Spouts和Bolts之间传输。例如,`WordCountTopology`是一个简单的例子,其中`Tweetspout`生成推文,`ParseTweetBolt`解析推文内容,然后其他Bolts统计每个单词出现的次数。
4. **操作经验与故障恢复**:Storm提供了强大的操作体验和故障恢复机制。它能够在集群中进行分布式部署,并且当某个节点失败时,可以自动重新分配任务,保证系统的持续运行。
5. **实时分析**:Storm的主要优势在于它能够处理不断流入的数据流,进行实时分析,这对于需要快速响应数据变化的应用场景至关重要,比如实时广告定向、社交媒体分析、交易监控等。
通过这份Storm @Twitter的PPT,读者可以深入了解实时流处理的工作原理,以及如何构建和操作一个高效的Storm拓扑。对于想要进入大数据实时处理领域的学习者来说,这是一个非常宝贵的资源。
STORM TOPOLOGY
%
%
%
%
%
SPOUT 1
SPOUT 2
BOLT 1
BOLT 2
BOLT 3
BOLT 4
BOLT 5
剩余30页未读,继续阅读
145 浏览量
2019-11-07 上传
2019-08-21 上传
102 浏览量
182 浏览量
104 浏览量

阿瑞斯的黄昏
- 粉丝: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- Saber仿真下的简化Buck环路分析与TDsa扫频
- Spring框架下使用FreeMarker发邮件实例解析
- Cocos2d捕鱼达人路线编辑器开发指南
- 深入解析CSS Flex布局与特性的应用
- 小学生加减法题库自动生成软件介绍
- JS颜色选择器示例:跨浏览器兼容性
- ios-fingerprinter:自动化匹配iOS配置文件与.p12证书
- 掌握移动Web前端高效开发技术要点
- 解决VS中OpenGL程序缺失GL/glut.h文件问题
- 快速掌握POI技术,轻松编辑Excel文件
- 实用ASCII码转换工具:轻松实现数制转换与查询
- Oracle ODBC补丁解决数据源配置问题
- C#集成连接器的开发与应用
- 电子书制作教程:你的文档整理助手
- OpenStack计费监控:使用collectd插件收集统计信息
- 深入理解SQL Server 2008 Reporting Services
