分布式系统经典论文集:Google技术解码
需积分: 11 3 浏览量
更新于2024-07-16
收藏 18.38MB PDF 举报
《分布式系统领域经典论文翻译集》是一本极具参考价值的文献汇编,专为深入理解分布式系统的设计、实现与优化而精心编纂。该书收录了一系列里程碑式的Google论文,展示了这些公司在处理海量数据、构建大规模并行计算架构以及设计高效分布式服务方面的创新实践。
首先,论文译序概述了分布式系统的理论基础和重要性,强调了这些经典论文对于现代技术发展的影响。接着,作者关注于SQL和NoSQL时代的演变,介绍了如何根据特定场景选择合适的数据存储和查询模型。
1. "The Anatomy of a Large-Scale Hypertextual Web Search Engine"(译文:大规模超文本网络搜索引擎的解剖)详细剖析了Google搜索引擎的核心技术,揭示了其大规模数据处理和索引构建的原理。
2. "Web Search for a Planet: The Google Cluster Architecture"(译文:地球规模的网络搜索:Google集群架构)探讨了Google如何通过分布式集群技术来支撑全球范围内的搜索服务。
3. "GFS:Google 文件系统"(译文:GFS:Google文件系统)介绍了Google内部用于存储和管理大量数据的分布式文件系统,展示了其在高可用性和吞吐量方面的设计。
4. "MapReduce: Simplied Data Processing on Large Clusters"(译文:MapReduce:大型集群上的简化数据处理)阐述了这个广泛应用的编程模型,使得非专家也能编写出高效的并行处理任务。
5. "Bigtable: A Distributed Storage System for Structured Data"(译文:Bigtable:结构化数据的分布式存储系统)是关于Google如何设计一个支持复杂查询的分布式数据库,支持实时数据处理。
6. "Chubby: The Chubby Lock Service for Loosely-Coupled Distributed Systems"(译文:Chubby:为松耦合分布式系统提供的锁服务)探讨了Google如何解决分布式系统中的协调问题,确保一致性。
7. "Sawzall: Interpreting the Data -- Parallel Analysis with Sawzall"(译文:Sawzall:用Sawzall进行并行数据分析)介绍了Google开发的一种用于解析和分析数据的工作流系统,强调了数据处理效率。
8. "Pregel: A System for Large-Scale Graph Processing"(译文:Pregel:大规模图处理系统)展示了在分布式环境中处理图数据的高效算法,对社交网络分析等领域有深远影响。
9. "Dremel: Interactive Analysis of Web-Scale Datasets"(译文:Dremel:Web规模数据集的交互式分析)重点介绍了Google开发的用于在线查询优化的查询处理引擎。
10. "Percolator: Large-scale Incremental Processing Using Distributed Transactions and Notifications"(译文:Percolator:利用分布式事务和通知进行大规模增量处理)讨论了如何通过分布式事务处理来提高系统响应速度。
11. "MegaStore: Providing Scalable, Highly Available Storage for Interactive Services"(译文:MegaStore:为交互式服务提供可扩展且高可用的存储)展现了Google如何为实时交互应用提供强大的数据存储解决方案。
此外,书中还包括对GFS进阶研究、多主节点时代的来临(如Google FileSystem II)、以及将SQL实现于MapReduce框架上的尝试(如Tenzing)等,充分体现了Google在分布式系统领域的探索和技术创新。这些论文不仅提供了实用的技术细节,还揭示了分布式系统设计的策略和最佳实践,对IT专业人士具有极高的学习价值。

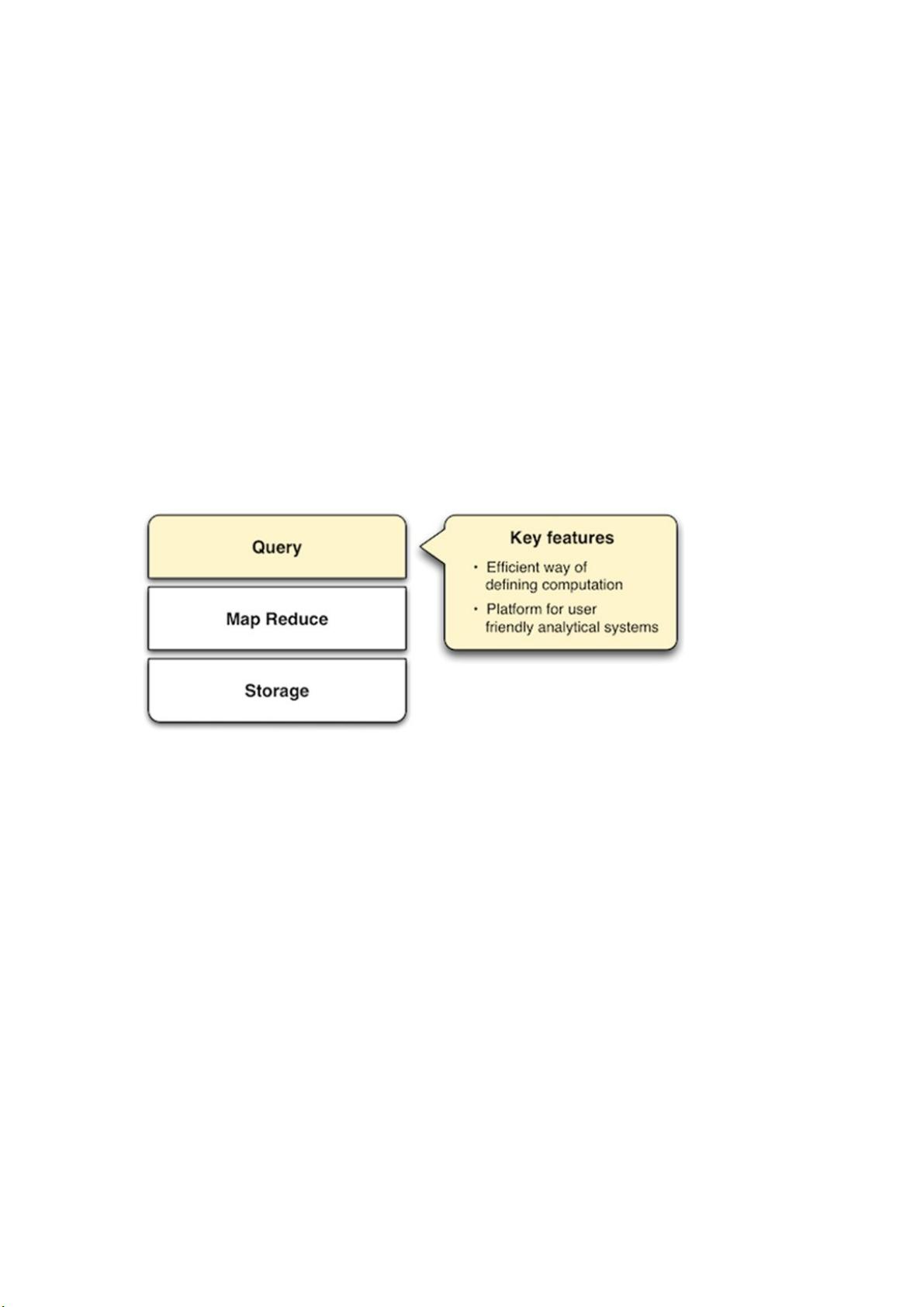
目前为止我们提到的存储解决方案都是依赖于Hadoop进行MapReduce。还有一些NoSQL数
据库为了对存储数据进行并行计算本身具有内建的Mapreduce支持。与Hadoop系统的多组件
SMAQ架构不同,它们提供一个由storage, MapReduce and query一体组成的自包含系统。!
基于Hadoop的系统通常是面向批量处理分析,NoSQL存储通常是面向实时应用。在这些数据
库里,MapReduce通常只是一个附加功能,作为其他查询机制的一个补充而存在。比如,在
Riak里,对MapReduce job通常有一个60秒的超时限制,而通常来说, Hadoop 认为一个job
可能运行数分钟或者数小时。!
下面的这些NoSQL数据库都具有MapReduce功能:
CouchDB,一个分布式数据库,提供了半结构化的文档存储功能。主要特点是提供很强的多副
本支持,以及可以进行分布式更新。在CouchDB里,查询是通过使用javascript定义
MapReduce的map和reduce阶段实现的。
MongoDB,本身很类似于CouchDB,但是更注重性能,对于分布式更新,副本,版本的支持
相对弱些。MapReduce也是通过javascript描述的。
Riak,与前面两个数据库也很类似。但是更关注高可用性。可以使用javascript或者Erlang描
述MapReduce。
!与关系型数据库的集成!
在很多应用中,主要的源数据存储在关系型数据库中,比如Mysql或者Oracle。MapReduce
通常通过两种方式使用这些数据:
使用关系型数据库作为源(比如社交网络中的朋友列表)
将MapReduce结果重新注入到关系型数据库(比如基于朋友的兴趣产生的产品推荐列表)
!理解MapReduce如何与关系型数据库交互是很重要的。最简单的,通过组合使用SQL导出命
令和HDFS操作,带分隔符的文本文件可以作为传统关系型数据库和Hadoop系统间的导入导出
格式。更进一步的讲,还存在一些更复杂的工具。
!Sqoop工具是设计用来将数据从关系型数据库导入到Hadoop系统。它是由Cloudera开发的,
一个专注于企业级应用的Hadoop平台经销商。Sqoop是与具体数据库无关的,因为它使用了
java的JDBC数据库API。可以将整个表导入,也可以使用查询命令限制需要导入的数据。
!Sqoop也提供将MapReduce的结果从HDFS导回关系型数据库的功能。因为HDFS是一个文件
系统,所以Sqoop需要以分隔符标识的文本为输入,需要将它们转换为相应的SQL命令才能将
数据插入到数据库。
!对于Hadoop系统来说,通过使用Cascading API中的cascading.jdbc和
cascading-dbmigrate也能实现类似的功能。
!与streaming数据源的集成
关系型数据库以及流式数据源(比如web服务器日志,传感器输出)组成了海量数据系统的最常见
的数据来源。Cloudera的Flume项目就是旨在提供流式数据源与Hadoop之间集成的方便工具。
Flume收集来自于集群机器上的数据,将它们不断的注入到HDFS中。Facebook的Scribe服务
器也提供类似的功能。!
商业性的SMAQ解决方案
一些MPP数据库具有内建的MapReduce功能支持。MPP数据库具有一个由并行运行的独立节
点组成的分布式架构。它们的主要功能是数据仓库和分析,可以使用SQL。!
Greenplum:基于 开 源 的 PostreSQL DBMS,运 行 在分 布 式 硬 件 组 成的 集 群 上 。MapReduce
作为SQL的补充,可以进行在Greenplum上的更快速更大规模的数据分析,减少了几个数量级
的查询时间。Greenplum MapReduce允许使用由数据库存储和外部数据源组成的混合数据。
MapReduce操作可以使用Perl或者Python函数进行描述。!



剩余954页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-08-10 上传
2021-08-09 上传
2021-08-09 上传
2022-06-21 上传
2021-08-10 上传
2021-08-11 上传

senhehe
- 粉丝: 0
- 资源: 16
 我的内容管理
展开
我的内容管理
展开







最新资源
- Python库 | python-gitlab-0.14.tar.gz
- bmed-4460-6460:生物图像分析课程的源代码(BMED 44606460)
- rpgit-system:rpgit系统
- ListBox.zip源码Labview个人项目资料程序资源下载
- sympathetic-synth:交感合成器系统Mk1
- launch-extension-context-data-tools:提供操作和一些工具,使您可以使用contextData变量进行跟踪
- Look4:基于MVI,附近连接API和Hilt的约会应用
- TWB:TWB 网络应用程序
- fps沙箱
- Python库 | python-ftx-0.1.0.tar.gz
- GenGen:通用的世代系统
- 感言
- lunchlady:一个基于NodeJS的愚蠢,简单的无后端CMS
- 资源fastjson-get-post.zip
- sssnap-api:已弃用 - 用于 sssnap 的 REST JSON API
- Excel模板开票申请单模板.zip
