动手实现:Java网络爬虫实战与HTTP状态码处理
下载需积分: 15 | PDF格式 | 2.49MB |
更新于2024-07-26
| 54 浏览量 | 举报
网络爬虫是获取和处理互联网数据的重要工具,这一章节主要围绕如何编写自己的网络爬虫展开讲解。首先,理解网络爬虫的基础操作——抓取网页。抓取网页的本质是客户端向服务器发送请求,获取网页内容。要实现这一过程,你需要掌握以下几个关键步骤:
1. **URL的理解与使用**:
URL(统一资源定位符)是互联网上每个资源的唯一标识,它由三部分组成:访问机制、主机名和资源路径。例如,`http://www.lietu.com` 就是一个URL,通过浏览器输入这样的地址,客户端就能找到对应的服务器资源。
2. **发送HTTP请求**:
使用编程语言(如Java),你可以创建一个HTTP请求,指定目标URL,然后通过网络发送。这涉及到编程库或API的使用,如Java中的HttpURLConnection或者更现代的HttpClient或OkHttp。
3. **接收和解析响应**:
服务器接收到请求后会返回一个HTTP响应,包含状态码和内容。状态码如200表示成功,404表示未找到,500表示服务器错误。了解如何解读这些状态码对于爬虫来说至关重要,因为它能帮助判断请求是否成功。
4. **处理网页内容**:
获取到网页后,需要解析其HTML源代码,提取所需的数据。这可能需要用到正则表达式、HTML解析库(如Jsoup for Java)或其他DOM解析技术。
5. **处理动态内容**:
如果目标网页包含JavaScript动态加载的内容,可能需要模拟用户行为(如点击、滚动)来获取完整数据,这时可能需要用到Selenium等工具。
6. **处理异常和反爬策略**:
网站可能会有反爬虫机制,如验证码、频率限制等,需要设计合适的爬虫策略来避免被封禁,如设置合理的请求间隔、使用代理IP等。
7. **数据存储与分析**:
抓取到的数据需要保存和处理,这可能涉及数据库操作,数据分析,甚至数据挖掘。在企业应用中,这些数据可能用于数据仓库管理、业务决策支持或个性化推荐等。
网络爬虫不仅仅是简单的页面抓取,它涉及到网络通信、数据解析、编程技巧以及对网站结构的理解。通过学习和实践,你可以开发出能满足特定需求的高效爬虫系统,从而从海量互联网数据中提取有价值的信息。
12
1
的遍历的方式对互联网这个超级大 “ 图 ” 进行访问。图的遍历通常可分为宽度优先遍历和
深度优先遍历两种方式。但是深度优先遍历可能会在深度上过 “ 深 ” 地遍历或者陷入 “ 黑
洞 ” ,大多数爬虫都不采用这种方式。另一方面,在爬取的时候,有时候也不能完全按照
宽度优先遍历的方式 , 而是给待遍历的网页赋予一定的优先级 , 根据这个优先级进行遍历
,
这种方法称为带偏好的遍历。本小节会分别介绍宽度优先遍历和带偏好的遍历。
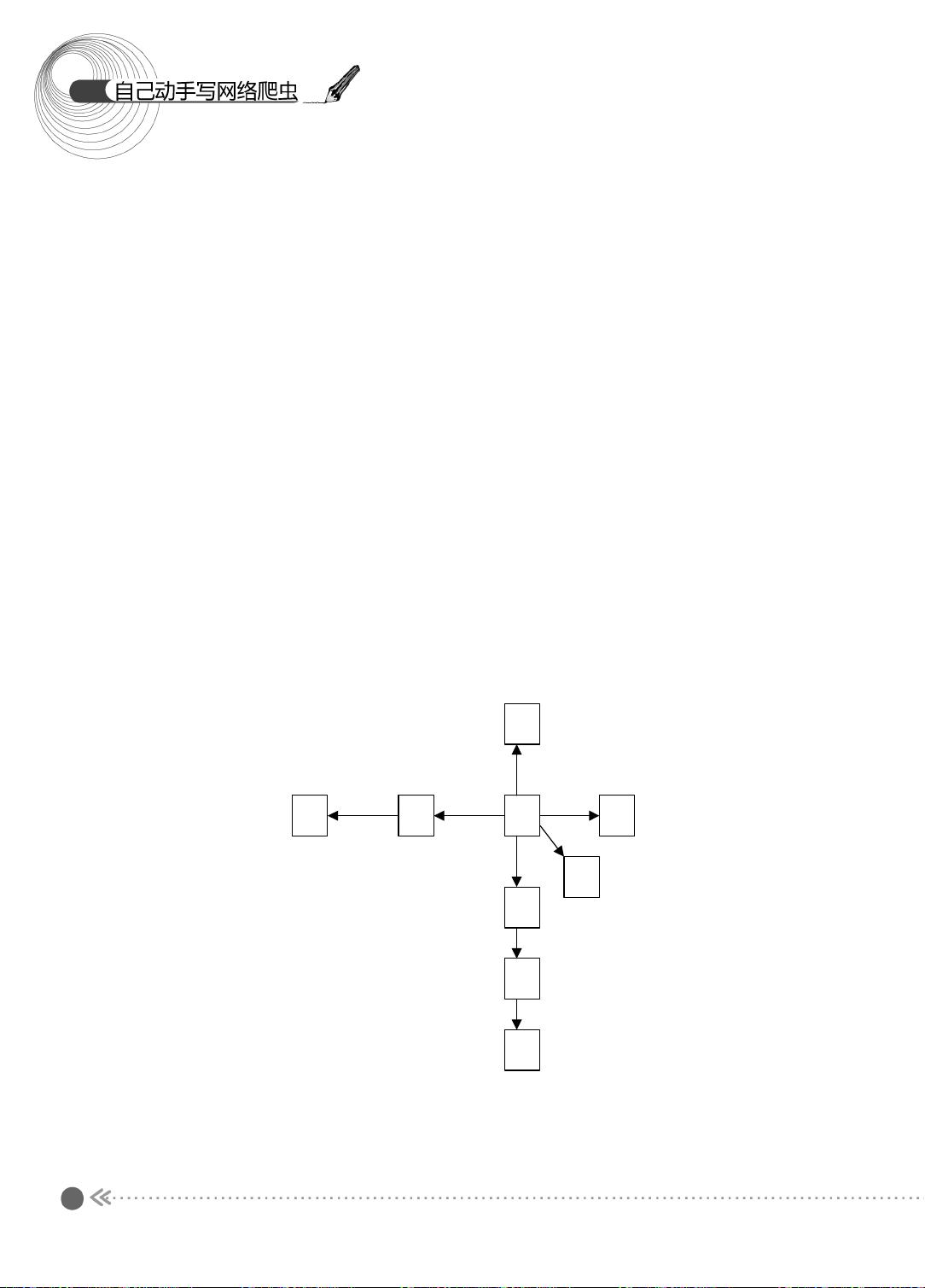
1.2.1 图的宽度优先遍历
下面先来看看图的宽度优先遍历过程 。 图的宽度优先遍历 (BFS) 算法是一个分层搜索的
过程,和树的层序遍历算法相同。在图中选中一个节点,作为起始节点,然后按照层次遍
历的方式,一层一层地进行访问。
图的宽度优先遍历需要一个队列作为保存当前节点的子节点的数据结构。具体的算法
如下所示:
(1) 顶点 V 入队列。
(2) 当队列非空时继续执行,否则算法为空。
(3) 出队列,获得队头节点 V ,访问顶点 V 并标记 V 已经被访问。
(4) 查找顶点 V 的第一个邻接顶点 col 。
(5) 若 V 的邻接顶点 col 未被访问过,则 col 进队列。
(6) 继续查找 V 的其他邻接顶点 col ,转到步骤 (5) ,若 V 的所有邻接顶点都已经被访
问过,则转到步骤 (2) 。
下面,我们以图示的方式介绍宽度优先遍历的过程,如图 1.3 所示。
G
B
A
C
D
F
E
I
H
图 1.3 宽度优先遍历过程

剩余67页未读,继续阅读
相关推荐



39 浏览量

39 浏览量

20 浏览量

stranchong
- 粉丝: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- Visual Studio (VC) 快捷键大全
- 基于FPGA的32Kbps CVSD语音编解码器实现
- 基于FPGA的32Kbit/s CVSD语音编解码器实现
- Axis2:提升Web服务开发效率
- Oracle数据库常见问题与解答
- Oracle游标深入解析与应用
- Oracle 9i闪回技术:数据删除后恢复策略
- Dojo框架实战教程:Ajax应用开发必备
- A Byte of Python:简明Python编程教程
- 赵炯深度解读:0.11版Linux内核注释详解
- ModelMaker5设计模式中文版详解:简化实例制作
- 遗传优化全结构径向基概率神经网络
- Object Pascal编程指南:集成开发环境与程序组织
- 《玩转Windows》全攻略:从DOS到XP的操作系统宝典
- IP反向追踪技术在对抗DoS攻击中的应用与分析
- Windows XP下安装与使用Cygwin/X指南
