使用Scrapy框架构建高效网络爬虫
版权申诉
32 浏览量
更新于2024-06-28
收藏 1.18MB PPTX 举报
"数据挖掘与数据管理-Scrapy应用.pptx"
Scrapy是一个强大的Python爬虫框架,专为处理大规模网页抓取和数据管理设计。它提供了许多高级功能,使得构建高效、可扩展的爬虫变得简单。本章重点讨论了如何利用Scrapy进行数据挖掘和管理。
在数据挖掘和数据管理的背景下,Scrapy的重要性在于它的模块化设计,它由多个组件组成,包括Spiders、Items、ItemPipelines、Middleware等,这些组件协同工作,使得数据的抓取、清洗、存储流程更加高效和灵活。
1. **Scrapy框架构成**:
- **Spiders**:是Scrapy的核心,它们定义了如何从一个或多个网站中提取数据。开发者可以自定义Spider类,指定如何跟随链接、解析响应,以及如何提取和处理数据。
- **Items**:代表要抓取的数据结构,类似于Python字典,定义了数据字段和类型,方便后续处理。
- **Requests & Responses**:Scrapy使用Requests对象来发起HTTP请求,而Responses则是收到的HTTP响应,包含服务器返回的所有信息,如HTML或JSON数据。
- **Selectors**:Scrapy内置了XPath和CSS选择器,用于从HTML或XML文档中提取数据。
- **ItemPipelines**:是一系列处理Item数据的组件,用于清洗、验证和存储数据。例如,可以去除重复项、转换数据格式或保存到数据库。
- **Middleware**:中间件是自定义的钩子,可以插入到Scrapy的请求/响应流程中,实现额外的功能,如用户代理切换、请求延迟、反反爬机制等。
- **Settings**:允许用户配置Scrapy的行为,如设置下载延迟、启用/禁用特定中间件等。
2. **创建Scrapy项目**:
创建一个新的Scrapy项目非常简单,只需使用`scrapy startproject`命令。例如,创建名为“BaiduSpider”的项目,可以在命令行输入`scrapystartproject BaiduSpider`。这将在指定路径下生成一个包含默认目录结构的项目,如`BaiduSpider`文件夹,包含`scrapy.cfg`配置文件以及`spiders`、`items.py`、`pipelines.py`等关键文件。
3. **项目目录结构**:
项目目录通常包含以下部分:
- `scrapy.cfg`:项目配置文件,定义项目全局设置。
- `spiders`:存放Spider代码的目录。
- `items.py`:定义项目的数据模型(Items)。
- `pipelines.py`:定义数据处理管道(ItemPipelines)。
- `settings.py`:项目级别的配置文件,可以覆盖全局Scrapy设置。
- 其他辅助文件如中间件、模型、测试等。
4. **使用Scrapy**:
开发者需要根据需求修改`items.py`中的数据结构,创建自定义的Spider类,并在`spiders`目录下编写爬虫代码。`settings.py`可以用来调整Scrapy的行为,如设置下载延迟以避免被目标网站封禁。`pipelines.py`则用于定义数据清洗和存储规则。
通过以上内容,我们可以了解到Scrapy为数据挖掘和管理提供了高效、灵活的工具集。无论是在学术研究、市场分析还是其他领域,掌握Scrapy框架都能够极大地提升数据采集和处理的效率。

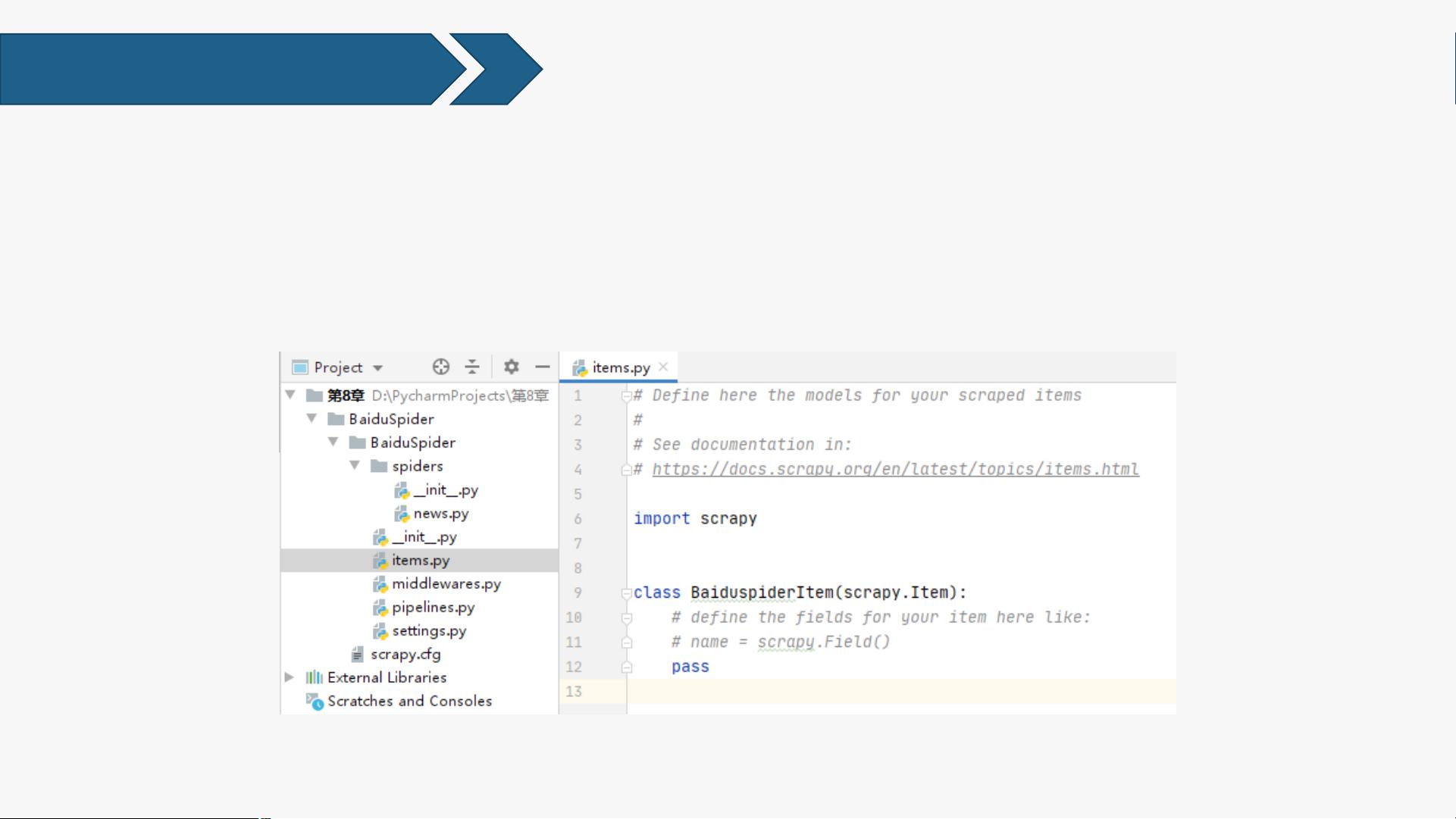
创建项目后,在“D:\PycharmProjects\第6章”下会生成一个名为“BaiduSpider”
的文件夹,其目录结构见图6-2。其中每个文件的功能如表6-1所示。
6.2 Scrapy应用
6.2.1 创建项目
表6-1 Scrapy爬虫项目的文件功能
文 件 说 明
spiders
创建Scrapy项目后自动创建的一个文件夹,用于存放用户编
写的spider脚本,每一个脚本都是一个文件
__init__.py 空文件,将其上级目录变成一个模块
items.py 定义Item中数据的结构,可以包含多个Item
middlewares.py
根据需求定义Downloader Middleware和Spider
Middleware,可以包含多个Middleware
pipelines.py 根据需求定义Pipeline,可以包含多个Pipeline
settings.py 定义项目的全局变量
scrapy.cfg
Scrapy项目的配置文件,定义项目的配置文件路径、部署相
关信息等
剩余42页未读,继续阅读
2021-11-12 上传
2019-11-12 上传
2021-11-13 上传
2022-11-14 上传
2023-11-21 上传
2022-12-24 上传

知识世界
- 粉丝: 375
- 资源: 1万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- Elasticsearch核心改进:实现Translog与索引线程分离
- 分享个人Vim与Git配置文件管理经验
- 文本动画新体验:textillate插件功能介绍
- Python图像处理库Pillow 2.5.2版本发布
- DeepClassifier:简化文本分类任务的深度学习库
- Java领域恩舒技术深度解析
- 渲染jquery-mentions的markdown-it-jquery-mention插件
- CompbuildREDUX:探索Minecraft的现实主义纹理包
- Nest框架的入门教程与部署指南
- Slack黑暗主题脚本教程:简易安装指南
- JavaScript开发进阶:探索develop-it-master项目
- SafeStbImageSharp:提升安全性与代码重构的图像处理库
- Python图像处理库Pillow 2.5.0版本发布
- mytest仓库功能测试与HTML实践
- MATLAB与Python对比分析——cw-09-jareod源代码探究
- KeyGenerator工具:自动化部署节点密钥生成
