Apache Beam实战:KafkaIO与Flink深度解析
52 浏览量
更新于2024-08-28
收藏 581KB PDF 举报
ApacheBeam实战指南是一系列深入讲解如何在现代大数据环境中有效利用Apache Beam和其与其他技术,如KafkaIO与Flink的集成的文章。随着大数据领域的发展,从批处理的Hadoop到实时处理的Spark Streaming和Flink,技术栈不断演变以适应日益增长的数据处理需求。Apache Beam作为一个重要的数据处理框架,由Google DataFlow发展而来,于2017年由Apache开源,旨在提供一个统一的编程模型,支持实时和批处理任务,同时兼容多种数据源和目的地。
在大数据架构的发展历程中,Hadoop的MapReduce主要用于离线批处理,而Storm则引入了实时流处理,能够处理实时事件。Spark则在此基础上提供了批处理和微批处理的能力,既满足批量计算又支持迭代操作。Flink作为流批处理的代表,结合了实时流处理和批处理的特性,能够在低延迟和高吞吐量之间找到平衡。
ApacheBeam的作用在于,它提供了一个通用的数据处理管道模型,开发者可以使用相同的编程接口编写任务,无论数据是实时流还是批处理。这极大地简化了开发者的任务选择和工具使用,使得他们能在Kafka这样的消息队列系统和Flink这样的实时处理引擎之间无缝切换。通过与KafkaIO的结合,开发者可以从Kafka中高效读取数据,而与Flink的集成则可能带来更高效的实时数据处理性能。
本文将深入探讨ApacheBeam在实际项目中的应用,如何设计和实现数据处理管道,以及如何通过结合KafkaIO和Flink优化工作流,提升开发效率和系统的灵活性。此外,还将讨论如何理解和利用ApacheBeam的执行模型(如无服务器处理和异步执行),以及如何在实际项目中进行性能调优和故障恢复策略。对于国内开发者来说,这个系列文章将有助于填补ApacheBeam技术在中国的空白,推动其在大数据领域的普及和发展。
ApacheBeam实战指南实战指南|玩转玩转KafkaIO与与Flink
关于Apache Beam实战指南系列文章
随着大数据 2.0 时代悄然到来,大数据从简单的批处理扩展到了实时处理、流处理、交互式查询和机器学习应用。近年来涌现
出诸多大数据应用组件,如 HBase、Hive、Kafka、Spark、Flink 等。开发者经常要用到不同的技术、框架、API、开发语言
和 SDK 来应对复杂应用的开发,这大大增加了选择合适工具和框架的难度,开发者想要将所有的大数据组件熟练运用几乎是
一项不可能完成的任务。
面对这种情况,Google 在 2016 年 2 月宣布将大数据流水线产品(Google DataFlow)贡献给 Apache 基金会孵化,2017 年
1 月 Apache 对外宣布开源 Apache Beam,2017 年 5 月迎来了它的第一个稳定版本 2.0.0。在国内,大部分开发者对于
Beam 还缺乏了解,社区中文资料也比较少。InfoQ 期望通过 **Apache Beam 实战指南系列文章** 推动 Apache Beam 在国内
的普及。
一.概述
大数据发展趋势从普通的大数据,发展成AI大数据,再到下一代号称万亿市场的lOT大数据。技术也随着时代的变化而变化,
从Hadoop的批处理,到Spark Streaming,以及流批处理的Flink的出现,整个大数据架构也在逐渐演化。
Apache Beam作为新生技术,在这个时代会扮演什么样的角色,跟Flink之间的关系是怎样的?Apache Beam和Flink的结合会
给大数据开发者或架构师们带来哪些意想不到的惊喜呢?
二.大数据架构发展演进历程
2.1 大数据架构Hadoop
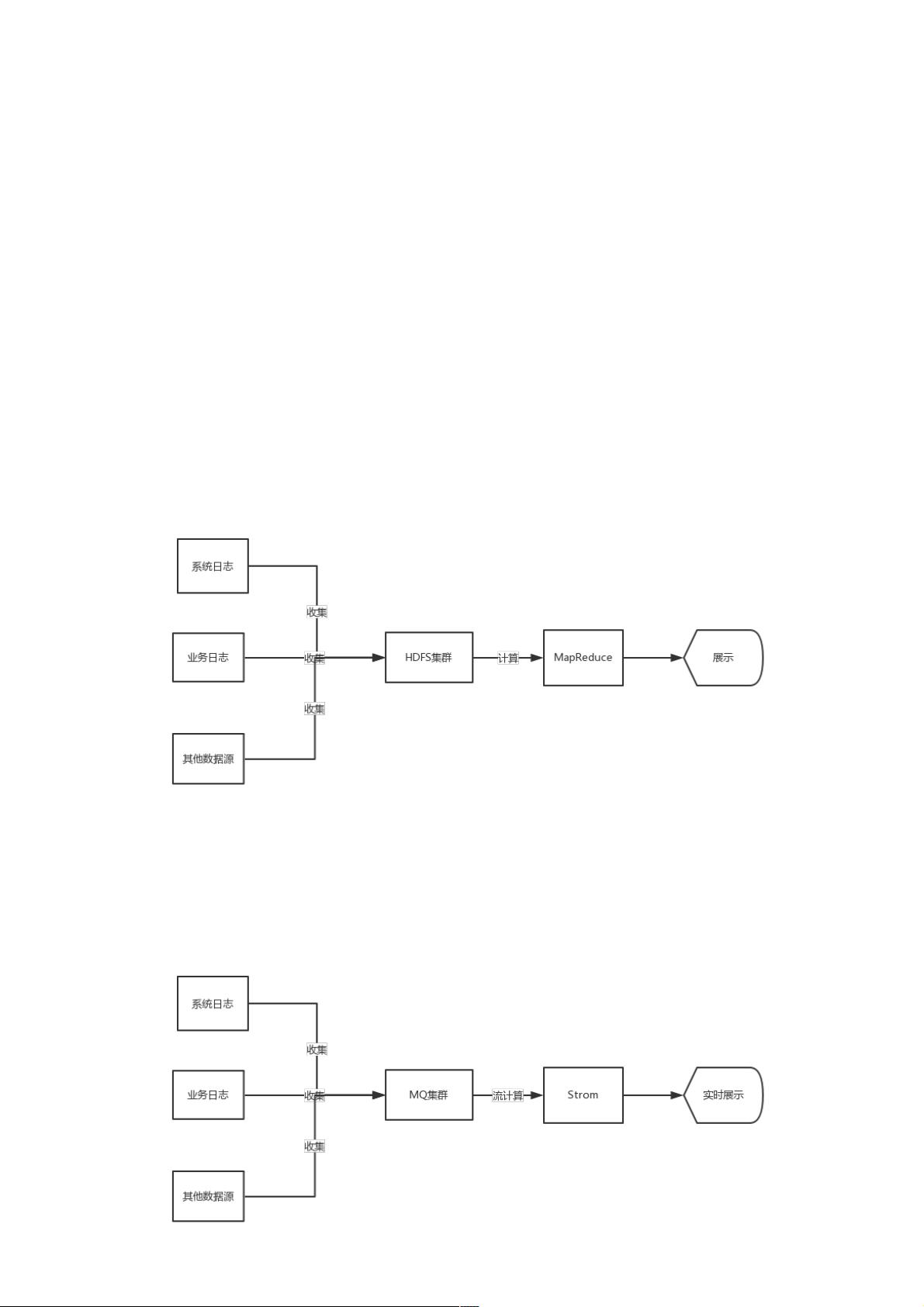
图2-1 MapReduce 流程图
最初做大数据是把一些日志或者其他信息收集后写入Hadoop 的HDFS系统中,如果运营人员需要报表,则利用Hadoop的
MapReduce进行计算并输出,对于一些非计算机专业的统计人员,后期可以用Hive进行统计输出。
2.2 流式处理Storm
下载后可阅读完整内容,剩余9页未读,立即下载
2019-10-15 上传
2021-05-30 上传
2021-03-25 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38598745
- 粉丝: 3
- 资源: 924
 我的内容管理
展开
我的内容管理
展开







最新资源
- 基于Python的豆瓣电影TOP250爬虫数据分析设计源码
- 基于LSTM神经网络的时间序列预测(Python完整源码和数据)
- eostokenranking:EOS链上的排名令牌列表
- Excel模板4-圆环饼图组合百分比图.zip
- cyTrie-开源
- 行业分类-设备装置-一种耐压瓦楞纸箱.zip
- ndovextract:弃用-替换为https
- gerrit-rabbitmq-plugin:业主的开发被冻结。 如果您想获得所有权或想继续在您的分叉公共存储库上进行开发,请与我联系
- 程序员的数学2_程序员的数学_programmer_
- AmbientIT-AdminUI
- 旅游注册.rar
- 基于SSM的电影购票系统设计源码
- OraDoc-开源
- 行业资料-建筑装置-带推动式开关的LED光源书写笔.zip
- matlab自相关代码-cupl:铜杯
- VectorCompare:节点模块以比较ES6中的向量
