Storm可靠性机制详解:Acker与Tuple生命周期
72 浏览量
更新于2024-08-30
收藏 253KB PDF 举报
"storm-可靠机制"
在分布式计算领域,Apache Storm是一个实时计算系统,它确保数据流处理的正确性和可靠性。本摘要将深入探讨Storm的可靠机制,包括其定义、核心组件Acker的工作原理以及如何确保消息的完整处理。
一、可靠性机制概述
Storm的可靠性特性在于它能够确认每个消息单元在预设的超时时间(timeout)内是否得到了完全处理。"完全处理"意味着与特定MessageId相关的源Tuple及其衍生的所有子Tuple都经过了Topology中的所有预期Bolt。超时时间可通过`Config.TOPOLOGY_MESSAGE_TIMEOUT_SECS`配置项进行设定。这种机制使得开发者能够确保数据流的准确无误,避免丢失或重复处理。
二、Acker组件
每个Storm Topology内置了一个Acker组件,它的主要职责是追踪由特定Task的Spout发射出去的每个messageId所关联的Tuple树的处理状态。如果在用户设定的超时时间内,这些Tuple没有完成处理,Acker会通知Spout处理失败,调用Spout的`fail`方法;反之,如果全部处理完成,Acker会调用`ack`方法告知Spout消息处理成功。
三、Tuple树与MessageId
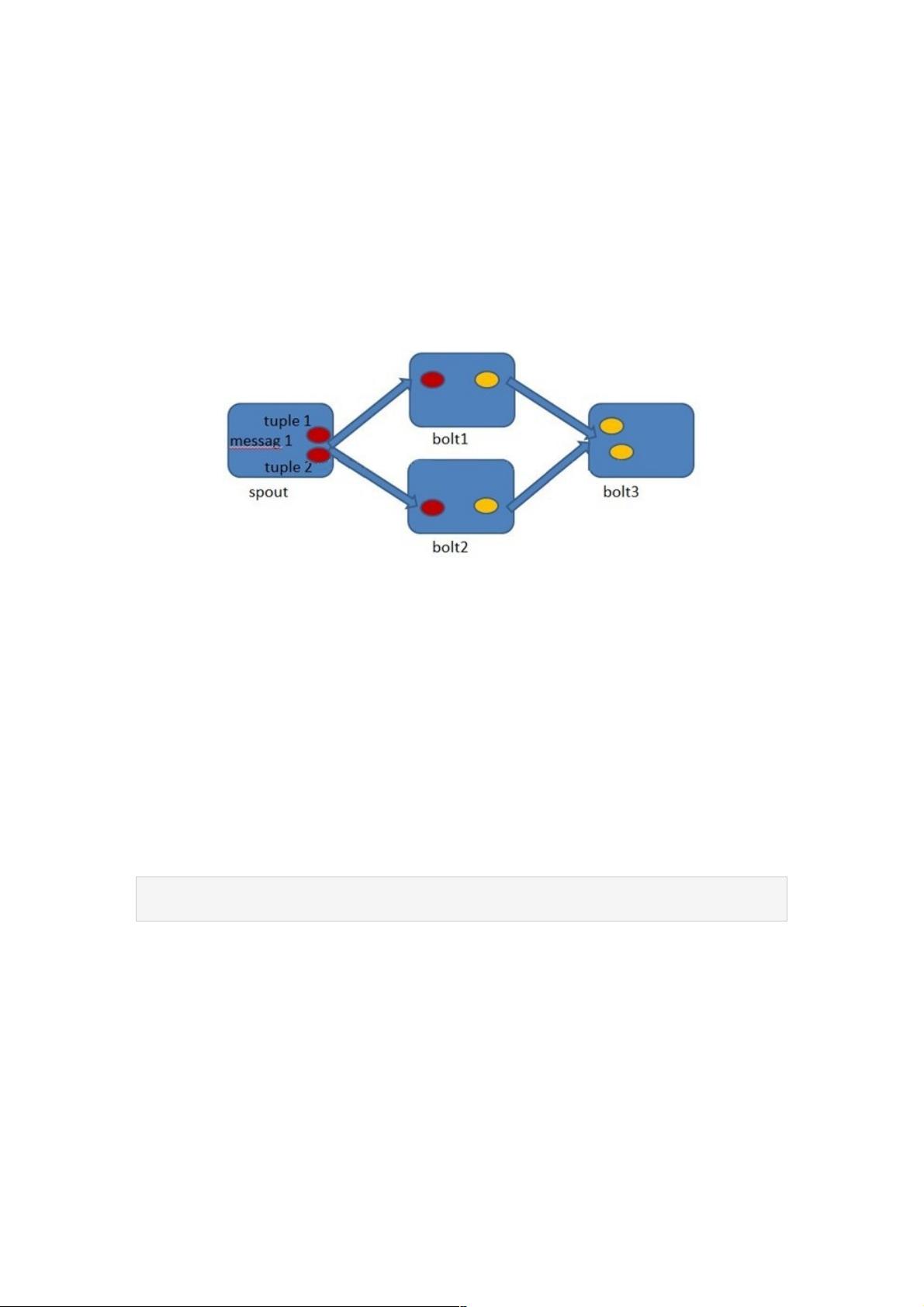
当Spout发射一个新的源Tuple时,可以通过MessageId对其进行标识,MessageId可以是任何Object对象。多个源Tuple可以共享同一个MessageId,表明它们对于用户来说是同一个消息单元,形成一棵tuple树。例如,一个由message1标识的源Tuple产生了tuple1和tuple2,经过bolt1和bolt2的处理后,生成新的Tuple,最后到达bolt3。当bolt3处理完毕,就认为message1已经被完全处理。
四、Acker工作原理
Acker任务是通过追踪每个创建的Tuple的64位ID来实现的。当acker发现一个tuple树处理完成,它会向生成这个tuple的原始task发送一个消息。acker的数量可以通过`Config.TOPOLOGY_ACKERS`配置,默认值为1。对于处理大量tuple的Topology,增加acker的数量可以提高处理效率。
总结起来,Storm的可靠机制通过Acker组件和MessageId确保了数据流的完整性,保证了每个消息单元在指定时间内得到正确处理。这种机制是Storm实时计算的核心组成部分,它提供了容错性,确保了数据处理的正确性和高效性。开发者可以据此构建高度可靠的实时数据处理系统,满足大数据实时分析的需求。
storm-可靠机制可靠机制
一 可靠性简介
Storm的可靠性是指Storm会告知用户每一个消息单元是否在一个指定的时间(timeout)内被完全处理。完全处理的意思是该
MessageId绑定的源Tuple以及由该源Tuple衍生的所有Tuple都经过了Topology中每一个应该到达的Bolt的处理。
注: timetout 可以通过Config.TOPOLOGY_MESSAGE_TIMEOUT_SECS 来指定
Storm中的每一个Topology中都包含有一个Acker组件。Acker组件的任务就是跟踪从某个task中的Spout流出的每一个
messageId所绑定的Tuple树中的所有Tuple的处理情况。如果在用户设置的最大超时时间内这些Tuple没有被完全处理,那么
Acker会告诉Spout该消息处理失败,相反则会告知Spout该消息处理成功,它会分别调用Spout中的fail和ack方法。
Storm允许用户在Spout中发射一个新的源Tuple时为其指定一个MessageId,这个MessageId可以是任意的Object对象。多个
源Tuple可以共用同一个MessageId,表示这多个源Tuple对用户来说是同一个消息单元,它们会被放到同一棵tuple树中,如
下图所示:
Tuple 树
在Spout中由message 1绑定的tuple1和tuple2分别经过bolt1和bolt2的处理,然后生成了两个新的Tuple,并最终流向了
bolt3。当bolt3处理完之后,称message 1被完全处理了。
二 Acker 原理分析
storm里面有一类特殊的task称为acker(acker bolt), 负责跟踪spout发出的每一个tuple的tuple树。当acker发现一个tuple树
已经处理完成了。它会发送一个消息给产生这个tuple的那个task。你可以通过Config.TOPOLOGY_ACKERS来设置一个
topology里面的acker的数量, 默认值是1。 如果你的topology里面的tuple比较多的话, 那么把acker的数量设置多一点,效率
会高一点。
理解storm的可靠性的最好的方法是来看看tuple和tuple树的生命周期, 当一个tuple被创建, 不管是spout还是bolt创建的, 它
会被赋予一个64位的id,而acker就是利用这个id去跟踪所有的tuple的。每个tuple知道它的祖宗的id(从spout发出来的那个
tuple的id), 每当你新发射一个tuple, 它的祖宗id都会传给这个新的tuple。所以当一个tuple被ack的时候,它会发一个消息给
acker,告诉它这个tuple树发生了怎么样的变化。具体来说就是它告诉acker: 我已经完成了, 我有这些儿子tuple, 你跟踪一下
他们吧。
(spout-tuple-id, tmp-ack-val)
tmp-ark-val = tuple-id ^ (child-tuple-id1 ^ child-tuple-id2 ... )
tmp-ack-val是要ack的tuple的id与由它新创建的所有的tuple的id异或的结果
当一个tuple需要ack的时候,它到底选择哪个acker来发送这个信息呢?
storm使用一致性哈希来把一个spout-tuple-id对应到acker, 因为每一个tuple知道它所有的祖宗的tuple-id, 所以它自然可以算
出要通知哪个acker来ack。
注:一个tuple可能存在于多个tuple树,所有可能存在多个祖宗的tuple-id
acker是怎么知道每一个spout tuple应该交给哪个task来处理?
当一个spout发射一个新的tuple, 它会简单的发一个消息给一个合适的acker,并且告诉acker它自己的id(taskid), 这样storm
就有了taskid-tupleid的对应关系。 当acker发现一个树完成处理了, 它知道给哪个task发送成功的消息。
Acker的高效性
acker task并不显式的跟踪tuple树。对于那些有成千上万个节点的tuple树,把这么多的tuple信息都跟踪起来会耗费太多的内
存。相反, acker用了一种不同的方式, 使得对于每个spout tuple所需要的内存量是恒定的(20 bytes) . 这个跟踪算法是
storm如何工作的关键,并且也是它的主要突破。
下载后可阅读完整内容,剩余4页未读,立即下载
2019-08-08 上传
2019-08-06 上传
2018-04-12 上传
2013-09-05 上传
2021-06-20 上传
2017-09-05 上传
2018-02-24 上传
2020-11-13 上传
2021-11-04 上传

weixin_38747025
- 粉丝: 129
- 资源: 1108
 我的内容管理
展开
我的内容管理
展开







最新资源
- Angular实现MarcHayek简历展示应用教程
- Crossbow Spot最新更新 - 获取Chrome扩展新闻
- 量子管道网络优化与Python实现
- Debian系统中APT缓存维护工具的使用方法与实践
- Python模块AccessControl的Windows64位安装文件介绍
- 掌握最新*** Fisher资讯,使用Google Chrome扩展
- Ember应用程序开发流程与环境配置指南
- EZPCOpenSDK_v5.1.2_build***版本更新详情
- Postcode-Finder:利用JavaScript和Google Geocode API实现
- AWS商业交易监控器:航线行为分析与营销策略制定
- AccessControl-4.0b6压缩包详细使用教程
- Python编程实践与技巧汇总
- 使用Sikuli和Python打造颜色求解器项目
- .Net基础视频教程:掌握GDI绘图技术
- 深入理解数据结构与JavaScript实践项目
- 双子座在线裁判系统:提高编程竞赛效率
