Uber大规模数据处理:Presto在千万亿字节级的交互式查询
版权申诉
78 浏览量
更新于2024-07-06
收藏 618KB PDF 举报
Presto在优步(Uber)的应用案例展示了其在处理大规模交互式查询中的卓越性能。作为数据平台的核心组件,Presto在Uber的使命——提供如同自来水般可靠且普及的交通服务中发挥了关键作用。Uber的全球扩张使其数据需求急剧增长,涉及400多个城市和69个国家,数据量达到了千万亿字节(PB)级别。
在2015年,Uber的数据生态系统主要包括以下几个方面:
1. **数据平台架构**:基于Kafka进行实时数据流处理,采用无模式(schema-less)的设计,确保了数据的灵活性和高效存储。
2. **SQL on Hadoop**:为了应对PB级数据,Uber引入了SQL查询能力到Hadoop上,通过Hadoop Distributed File System (HDFS)执行批处理任务,同时也支持交互式查询。
3. **Presto**:Presto作为关键的查询引擎,它设计用于处理大规模数据集,提供了快速的查询性能,使得数据即使在海量存储中也能得到实时响应。Presto的优势在于其并行处理能力和对列式存储格式如Parquet的支持,这些特性极大地提高了查询效率。
4. **数据存储格式**:Parquet是一种高效的列式存储格式,适用于大数据处理,有助于减少数据读取时间。
5. **基础设施**:优步构建了一个包含数百个节点的Hadoop集群,每天能处理大约10TB的数据摄入,并将数据存储在HDFS中,形成PB级的数据仓库。
然而,Presto的应用也面临了一些挑战:
- **商业数据库局限性**:非实时的数据必须等到被加载到商业数据库后才能进行查询,这导致了数据延迟。
- **扩展性限制**:单一的商业数据库集群受限于约32个节点,无法满足大规模数据处理的需求。
- **数据分布**:商业数据库中的数据量远小于HDFS中的数据,这影响了数据访问效率。
- **查询性能问题**:传统的Hive在处理PB级数据时,查询速度明显较慢,这促使Uber转向更高效的数据查询工具。
为了克服这些痛点,Uber开发了Presto Janus,这是一个与Hive兼容的接口,允许用户在Hadoop上运行Presto查询,从而解决了数据延迟和查询性能瓶颈。此外,Presto的引入还促进了其他应用的发展,如Kafka的消息处理和机器学习任务的负载。
总结来说,Presto在Uber的成功案例揭示了如何通过优化数据平台、采用列式存储、扩展查询性能以及开发定制解决方案来应对大数据时代的挑战。这对于其他企业来说,是理解和借鉴大规模交互式查询处理的重要参考。
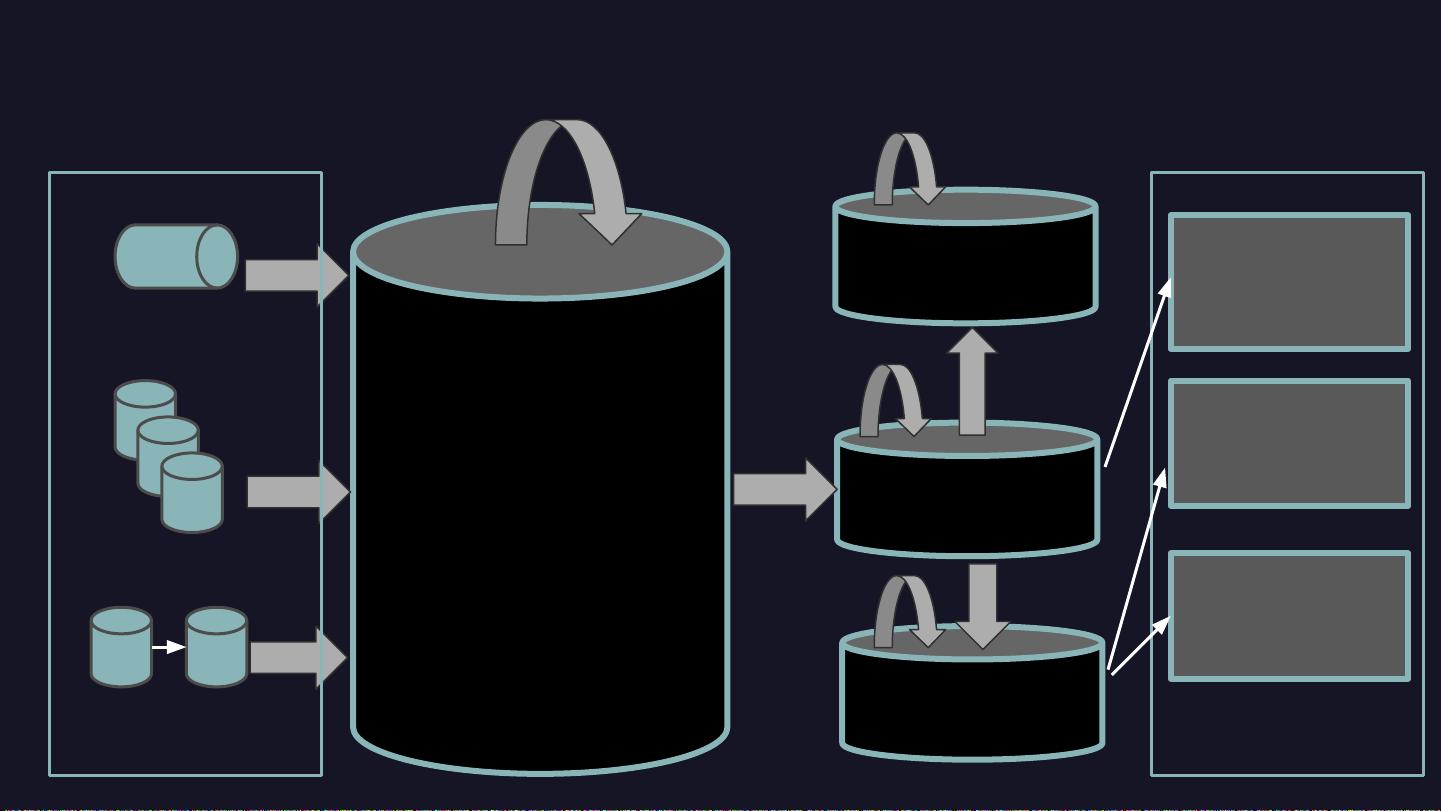
Data@Uber in 2015
Kafka
Schemaless
MySQL, Postgres
Data Producers
Hadoop Distributed File
System (HDFS)
Commercial
Database
Commercial
Database
Commercial
Database
ETL Jobs
ETL Jobs
ETL Jobs
ETL Jobs
Data Consumers
Load
Load
Ad Hoc Queries
Reports
Machine
Learning Jobs
Load
剩余19页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2016-08-10 上传
2022-03-18 上传
2019-09-17 上传
2021-03-23 上传
2021-05-18 上传
2021-05-11 上传

行业报告
- 粉丝: 4
- 资源: 6234
 我的内容管理
展开
我的内容管理
展开







最新资源
- reddit_clone:基于 RubyRails、HTML5CSS3 和 Bootstrap 框架的 Reddit 克隆网站
- postman32/64位安装包下载
- senior-project:我在高中最后一个学期为我的高级项目制作的游戏
- gs-web-admin:GS 的同构网络管理实验
- 材质101:使有用的东西-项目开发
- flyteidl:Flyte的核心是声明性,类型安全的语言,用于声明任意计算单元之间的数据依存关系。 该存储库以协议缓冲区的形式包含该语言的核心规范
- SamaSecurityPortal:Al Sama Security Company使用的一种系统,可简化其操作并管理其客户
- matlab_永磁同步电机的直接转矩控制_通过磁链和转矩估计,达到对转矩的直接控制。
- 0.96OLED音乐频谱.zip
- tasks
- V5-403_RTX实验_任务优先级修改.7z
- websockets-spring
- lingualeo-smart-tv-app:测试智能电视应用
- 参考手册STM32F101xx 和 STM32F103xx ARM 内核 32 位高性能微控制器-综合文档
- remly:小型python库和CLI脚本,允许在LAN上远程运行计算机
- Project
