memcached分布式算法解析
PDF格式 | 191KB |
更新于2024-08-27
| 189 浏览量 | 举报
"memcached全面剖析–4.memcached的分布式算法"
在深入理解memcached的分布式算法之前,首先要明确一点,memcached服务器本身并不具备分布式处理能力,它的核心功能是作为内存存储系统,负责高效地缓存数据。分布式特性是由客户端程序库来实现的,这也是memcached设计的一大特色。当客户端需要将数据存储或检索时,它会根据预设的算法确定数据应该存储在哪个服务器上。
memcached的分布式工作流程可以分为以下几个步骤:
1. **数据存储**:客户端接收到要存储的数据(例如键名为“tokyo”、“kanagawa”等)后,会使用一种算法根据键来选择一个合适的服务器。这个算法确保了相同的键会被始终路由到同一台服务器,以便后续的读取操作能够正确找到数据。
2. **数据获取**:在获取数据时,客户端同样使用相同的算法来决定向哪台服务器发送get请求。由于算法的一致性,可以确保数据将从正确的服务器上被获取。
3. **负载均衡**:随着memcached服务器数量的增加,键值对会被更均匀地分散到各个服务器上。这样做的好处是提高了系统的容错性,即使某一台服务器出现故障,其他服务器上的缓存数据仍然可以正常提供服务,从而维持系统的稳定运行。
对于Perl客户端函数库Cache::Memcached的分布式方法,它是memcached的原始实现,也是最常用的分布式策略之一。该库采用了一种基于余数的计算方法来决定数据应存储在哪个服务器上。具体来说,它将键的哈希值除以服务器的数量,然后取余数,余数对应的服务器就是数据的存储位置。这种方法简单且易于实现,能够有效地在多台服务器间分散负载。
例如,如果有3台服务器(node1, node2, node3),键“tokyo”的哈希值除以3后,余数可能是0、1或2,分别对应node1、node2或node3。由于哈希计算的均匀性,大多数键都会被均匀地分配到各台服务器,从而实现分布式存储。
memcached的分布式机制依赖于客户端的智能选择,通过特定的哈希算法确保数据的分布和一致性。这种设计允许用户灵活地扩展服务器集群,而无需修改服务器端的代码,大大增强了系统的可扩展性和可靠性。
memcached全面剖析全面剖析–4.memcached的分布式算法的分布式算法
memcached的分布式
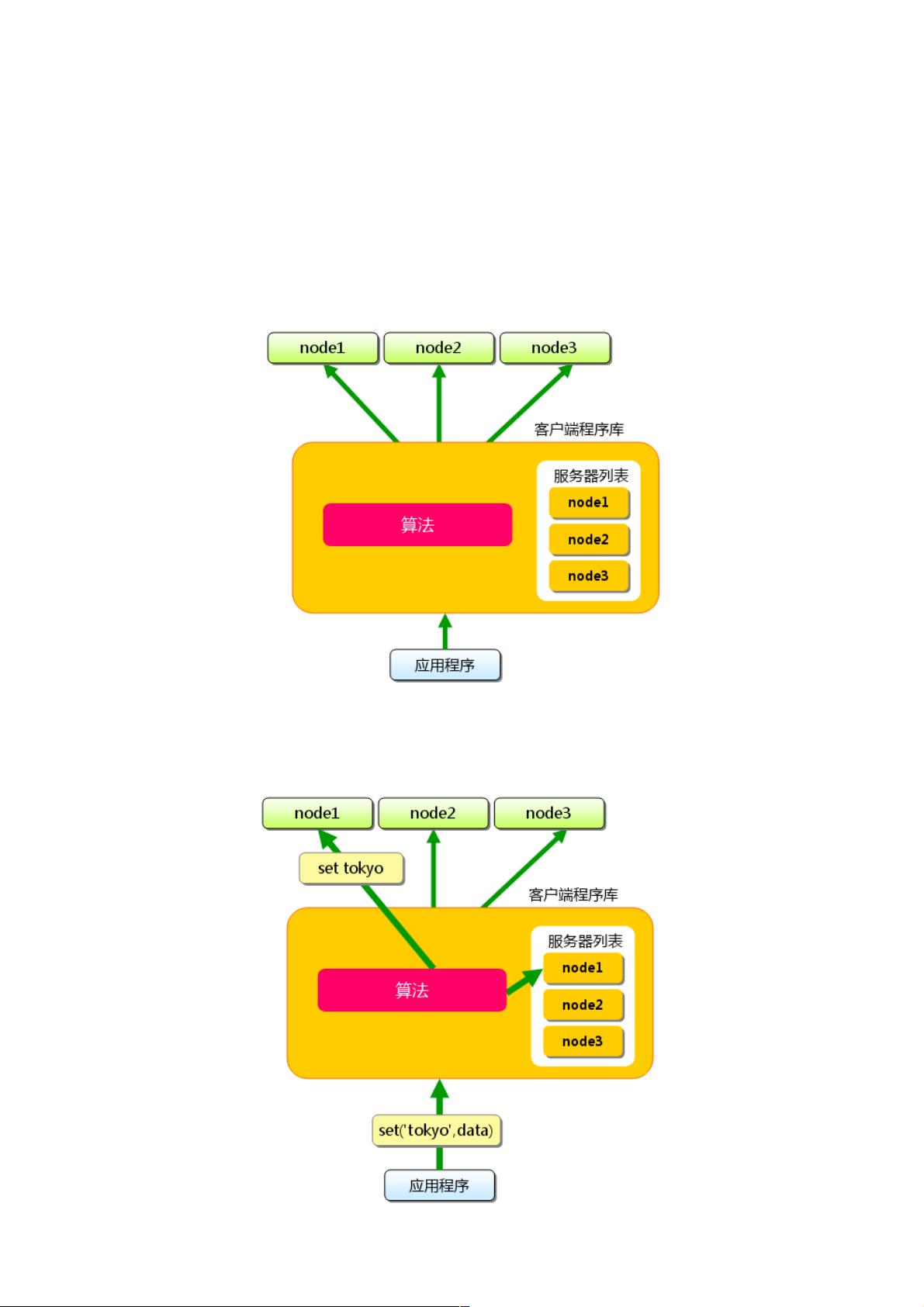
正如第1次中介绍的那样,memcached虽然称为“分布式”缓存服务器,但服务器端并没有“分布式”功能。 服务器端仅包括 第2
次、 第3次 前坂介绍的内存存储功能,其实现非常简单。 至于memcached的分布式,则是完全由客户端程序库实现的。 这种
分布式是memcached的最大特点。
memcached的分布式是什么意思?
这里多次使用了“分布式”这个词,但并未做详细解释。 现在开始简单地介绍一下其原理,各个客户端的实现基本相同。
下面假设memcached服务器有node1~node3三台, 应用程序要保存键名为“tokyo”“kanagawa”“chiba”“saitama”“gunma” 的数
据。
图1 分布式简介:准备
首先向memcached中添加“tokyo”。将“tokyo”传给客户端程序库后, 客户端实现的算法就会根据“键”来决定保存数据的
memcached服务器。 服务器选定后,即命令它保存“tokyo”及其值。
图2 分布式简介:添加时
下载后可阅读完整内容,剩余4页未读,立即下载
相关推荐





weixin_38537968
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- 微信小程序开发教程源码解析
- Step7 v5.4仿真软件:s7-300最新版本特性和下载
- OC与HTML页面间交互实现案例解析
- 泛微OA官方WSDL开发文档及调用实例解析
- 实现C#控制佳能相机USB拍照及存储解决方案
- codecourse.com视频下载器使用说明
- Axis2-1.6.2框架使用指南及下载资源
- CISCO路由器数据可视化监控:SNMP消息的应用与解析
- 白河子成绩查询系统2.0升级版发布
- Flutter克隆Linktree:打造Web应用实例教程
- STM32F103基础之MS5单片机系统应用详解
- 跨平台分布式Minecraft服务端:dotnet-MineCase开发解析
- FileZilla FTP服务器搭建与使用指南
- VB洗浴中心管理系统SQL版功能介绍与源码分析
- Java环境下的meu-grupo-social-api虚拟机配置
- 绿色免安装虚拟IE6浏览器兼容Win7/Win8
