Whale:超大模型分布式训练框架与最佳实践
版权申诉
174 浏览量
更新于2024-07-05
收藏 4.89MB PDF 举报
"2-3+超大模型高效训练的分布式框架Whale.pdf"
随着人工智能技术的快速发展,模型训练的需求和挑战也在不断升级。模型训练的趋势表明,模型的计算需求呈指数级增长,大约每2-3个月就需要翻一番。这主要体现在模型参数量的增加与性能的提升上,如Bert模型的参数规模增大能降低困惑度,Transformer模型的参数规模增大则可以提高翻译质量。这种发展趋势使得传统的单GPU训练方式逐渐无法满足需求。
为了应对这种挑战,训练方式经历了从数据并行到模型并行的转变。数据并行通过将数据集分割,让多个GPU同时处理不同的部分,从而加速训练。然而,随着模型参数的进一步膨胀,单个GPU的显存限制了模型的存储,这就催生了模型并行的策略。模型并行分为流水并行和算子拆分,前者是将模型沿时间轴切分,后者则是将模型的某个计算层拆分到多个GPU上。
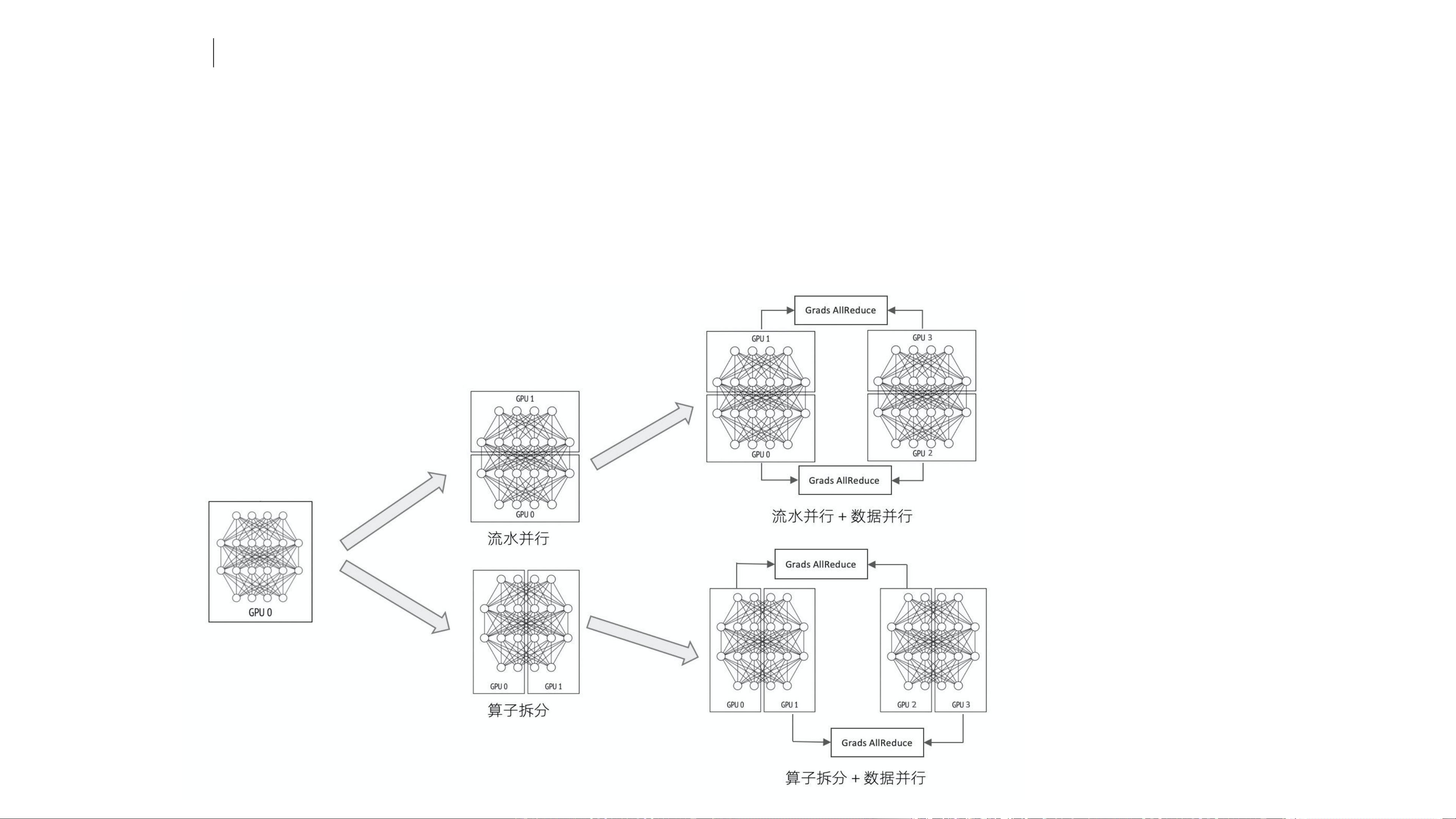
当模型并行和数据并行结合使用时,可以实现更高效的训练。然而,现有的训练框架,如Tensorflow、PyTorch以及基于它们的分布式框架(如Horovod、MeshTensorflow)等,虽然提供了多种并行策略,但仍然存在诸多挑战。比如,迁移不同框架的成本高,学习曲线陡峭,且往往仅支持特定类型的并行策略,如Horovod仅支持数据并行,Gpipe仅支持流水并行,而Mesh仅支持算子拆分。此外,实现复杂的分布式并行模型需要深厚的领域知识,配置并行策略也需要相当的技术功底。
针对这些问题,阿里云的PAI团队推出了Whale分布式框架,它旨在解决上述挑战,提供更加灵活、高效和易用的超大模型训练解决方案。Whale可能包含了对各种并行策略的支持,包括数据并行、模型并行中的流水并行和算子拆分,以及可能的混合并行策略,使得用户无需深入理解底层细节就能方便地切换并行策略。这降低了用户的迁移成本和学习成本,使得更广泛的开发者能够利用Whale进行大规模模型的训练。
以多模态预训练模型M6为例,其发展历程展示了模型规模的迅速扩大。从2020年6月的base-3亿参数规模,到2021年1月,模型参数量已经达到了惊人的规模。这样的模型需要更强大的分布式框架来支撑其训练,Whale在此背景下应运而生,为应对超大模型训练提供了有效的工具和平台。
Whale分布式框架是为了解决日益增长的超大模型训练需求和现有框架的局限性而设计的。它提供了一种统一的接口,简化了模型并行和数据并行的配置,降低了学习和迁移成本,为AI研究者和工程师提供了更高效、更便捷的模型训练环境。在未来,Whale有望成为超大规模模型训练的重要推动力,推动AI领域的创新和发展。
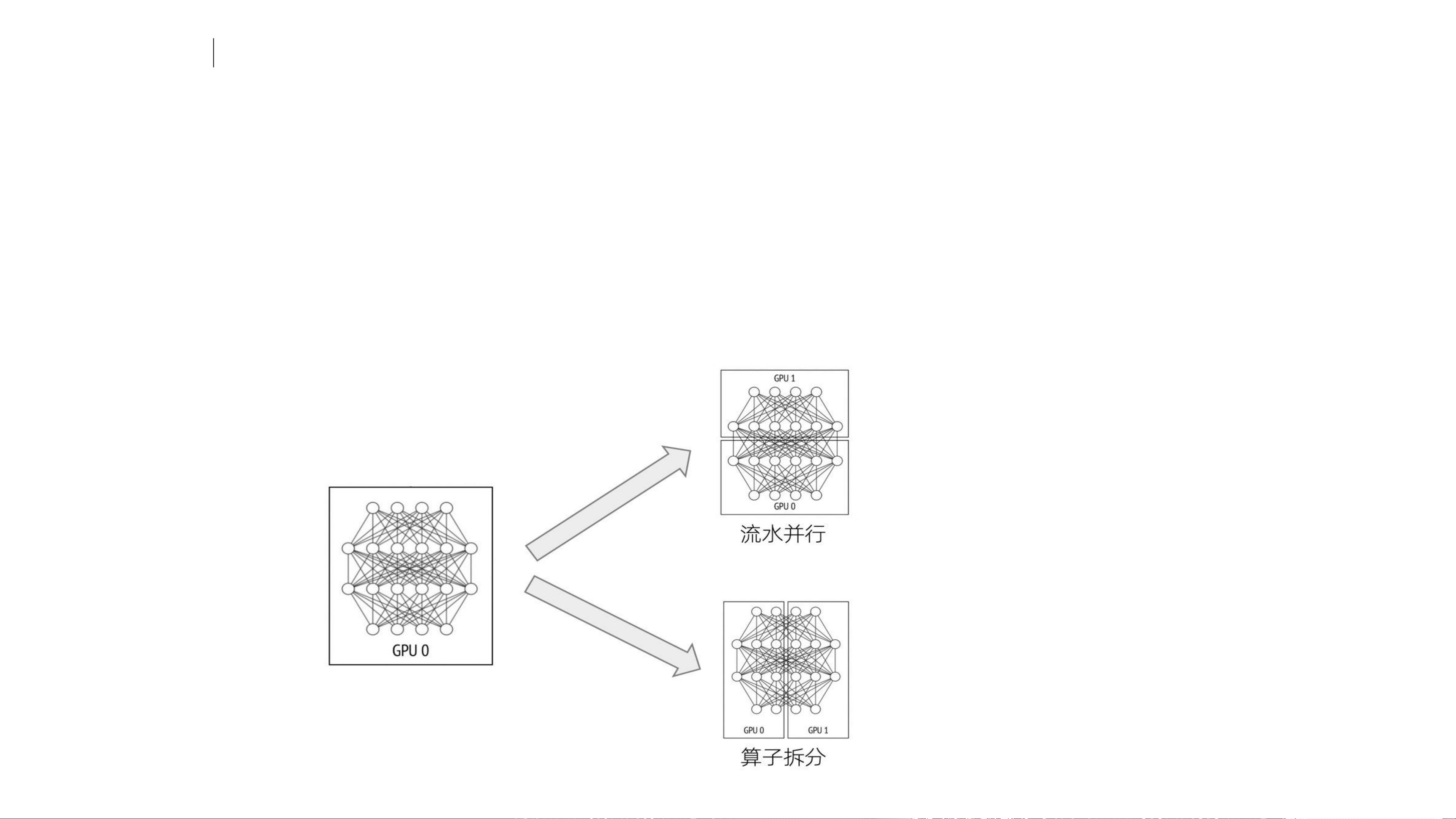
训练方式变迁
• 模型参数规模进一步扩大,单GPU显存已经不能存放模型副本;
• 采用模型并行的策略来拆分模型进行纵向扩展;
• 模型并行又包括流水并行和算子拆分:
剩余30页未读,继续阅读
2024-09-09 上传
288 浏览量
2025-01-28 上传
2025-01-23 上传
142 浏览量
244 浏览量
159 浏览量
175 浏览量

普通网友
- 粉丝: 13w+
 我的内容管理
展开
我的内容管理
展开







最新资源
- 32位instantclient_11_2使用指南及配置教程
- kWSL在WSL上轻松安装KDE Neon 5.20无需额外软件
- phpwebsite 1.6.2完整项目源码及使用教程下载
- 实现UITableViewController完整截图的Swift技术
- 兼容Android 6.0+手机敏感信息获取技术解析
- 掌握apk破解必备工具:dex2jar转换技术
- 十天掌握DIV+CSS:WEB标准实践教程
- Python编程基础视频教程及配套源码分享
- img-optimize脚本:一键压缩jpg与png图像
- 基于Android的WiFi局域网即时通讯技术实现
- Android实用工具库:RecyclerView分段适配器的使用
- ColorPrefUtil:Android主题与颜色自定义工具
- 实现软件自动更新的VC源码教程
- C#环境下CS与BS模式文件路径获取与上传教程
- 学习多种技术领域的二手电子产品交易平台源码
- 深入浅出Dubbo:JAVA分布式服务框架详解
