"使用Hadoop在Ubuntu环境下创建实例报告指南"
需积分: 0 135 浏览量
更新于2024-01-30
收藏 2.29MB DOCX 举报
Hadoop 实验报告
本次实验旨在通过使用Hadoop平台来进行数据处理和分析,并在AWS云平台上搭建一个Hadoop集群。以下是我在实验过程中的具体步骤和注意事项。
1. 选择操作系统和实例类型
在开始创建新实例时,我最初选择的是Ubuntu操作系统,但后来发现无法启动实例,于是我改为选择了Linux2操作系统。同样,在选择实例类型时,我最初选择的是micro,但最终我选择了medium类型。由于Hadoop集群通常需要较高的计算和存储资源,medium实例类型更适合本次实验的需求。
2. 选择实例数量和存储卷大小
我选择启动了三台实例,分别将它们命名为master、slaver01和slaver02。在选择存储卷大小时,我最初选择的是15GB,但后来我决定将其减小至8GB。这是因为本次实验的数据量不大,而且存储资源有限,合理配置存储卷大小可以更好地满足实验需求。
3. 创建新的密钥对
由于我使用的是Windows系统,不使用已有密钥对,我选择了创建新的密钥对。我将生成的密钥对文件命名为myrsa.pem。这样,我就可以使用该密钥对来进行后续步骤中的连接。
4. 使用PuTTY连接实例
由于我使用的是Windows系统,需要使用PuTTY来连接到实例。为了能够成功连接,我先使用PuTTY Generator工具将.pem文件转换为.ppk文件。然后,我使用PuTTY进行连接,输入用户名ec2-user,并成功进入了欢迎界面。
5. 安装和配置Hadoop集群
在成功连接到实例之后,我执行了Linux命令以创建一个名为hadoop的用户,并切换到hadoop用户。由于我没有使用Ubuntu系统,因此无法使用apt-get命令进行软件安装,所以我选择使用yum命令来代替。接下来,我下载了Java 1.8版本。我从官方网站上找到了Java的安装包,并按照官方指南进行了安装。
6. 下载和配置Hadoop
完成Java的安装后,我下载了Hadoop的安装包,并按照官方文档进行了配置。我修改了Hadoop的配置文件,包括core-site.xml、hdfs-site.xml和yarn-site.xml等,以便适应我的实验需求。
7. 启动和测试Hadoop集群
完成Hadoop的配置后,我启动了Hadoop集群。我首先启动了HDFS和YARN,并检查了它们的状态。然后,我通过执行一些简单的MapReduce作业来测试Hadoop集群的功能。
通过以上步骤,我成功地搭建了一个Hadoop集群,并进行了一些简单的数据处理和分析。在整个实验过程中,我遇到了一些问题,但通过查找官方文档和借助互联网资源,我成功地解决了这些问题。
总结起来,本次实验让我对Hadoop平台有了更深入的了解,并且熟悉了在AWS云平台上搭建Hadoop集群的步骤和流程。通过实际操作和测试,我对Hadoop的基本概念和功能有了更加直观的理解。这对于我将来在大数据处理和分析领域的学习和工作中将会非常有帮助。
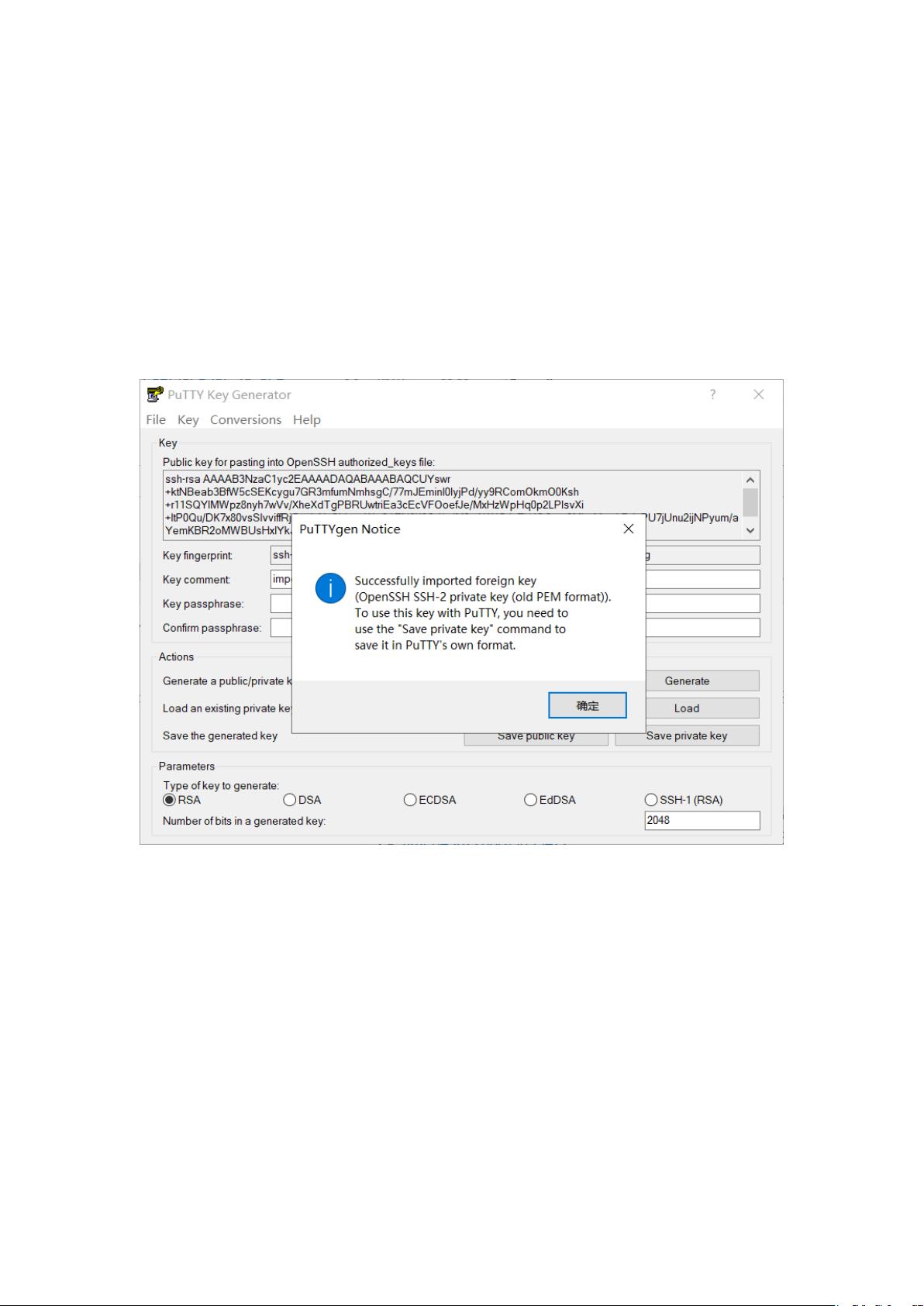
因为是 windows 系统,所以我要用 putty
进行连接。因此还要先用 putty generator
将 pem 文件进行格式转换,转换成.ppk 文
件。
剩余24页未读,继续阅读
2022-08-08 上传
点击了解资源详情
122 浏览量
2008-08-23 上传
121 浏览量

thebestuzi
- 粉丝: 37
- 资源: 311
 我的内容管理
展开
我的内容管理
展开







最新资源
- 周立功 RS485通讯 51单片机
- 网络编程 Web编程
- MC9S08AC60单片机数据手册(英文)
- java2d教材 .
- C#完全手册.pdf
- CRC算法原理及C语言实现.pdf
- BGP.Internet.Routing.Architectures.2nd.Edition.2000
- S3C44B0试验配置
- 自地球诞生以来最全的C语言笔试面试题!将近有250页的word文档!
- VC&MFC讲解教材
- 高质量C-C++编程指南
- XMPP核心(PDF)
- struts入门详解(初学者)
- 索尼(SONY)DSR-190P 数码摄像机说明书
- 学习ASP.NET的最优顺序(好的计划等于效率的提高)
- 关于智能手机的学习资料《智能手机》
