强化学习与机器人:Policy Gradient详解及实践
版权申诉
117 浏览量
更新于2024-06-19
收藏 4.97MB PDF 举报
"机器学习与机器人_38"
这篇资源主要涵盖了多个关于机器学习和机器人领域的主题,特别是强化学习的深度探讨。强化学习是人工智能的一个关键分支,它通过与环境的交互来学习最优策略,以最大化长期奖励。下面将详细讨论资源中的主要内容。
1. **强化学习的基本概念**
- **On-Policy与Off-Policy的区别**:在强化学习中,On-Policy是指在学习过程中使用的是当前策略来选择行动,而Off-Policy则是根据不同的策略(可能是以前学习到的或固定的策略)来收集经验数据。这两种方法各有优缺点,On-Policy通常更稳定,但可能探索性不足,Off-Policy则允许更灵活的数据利用。
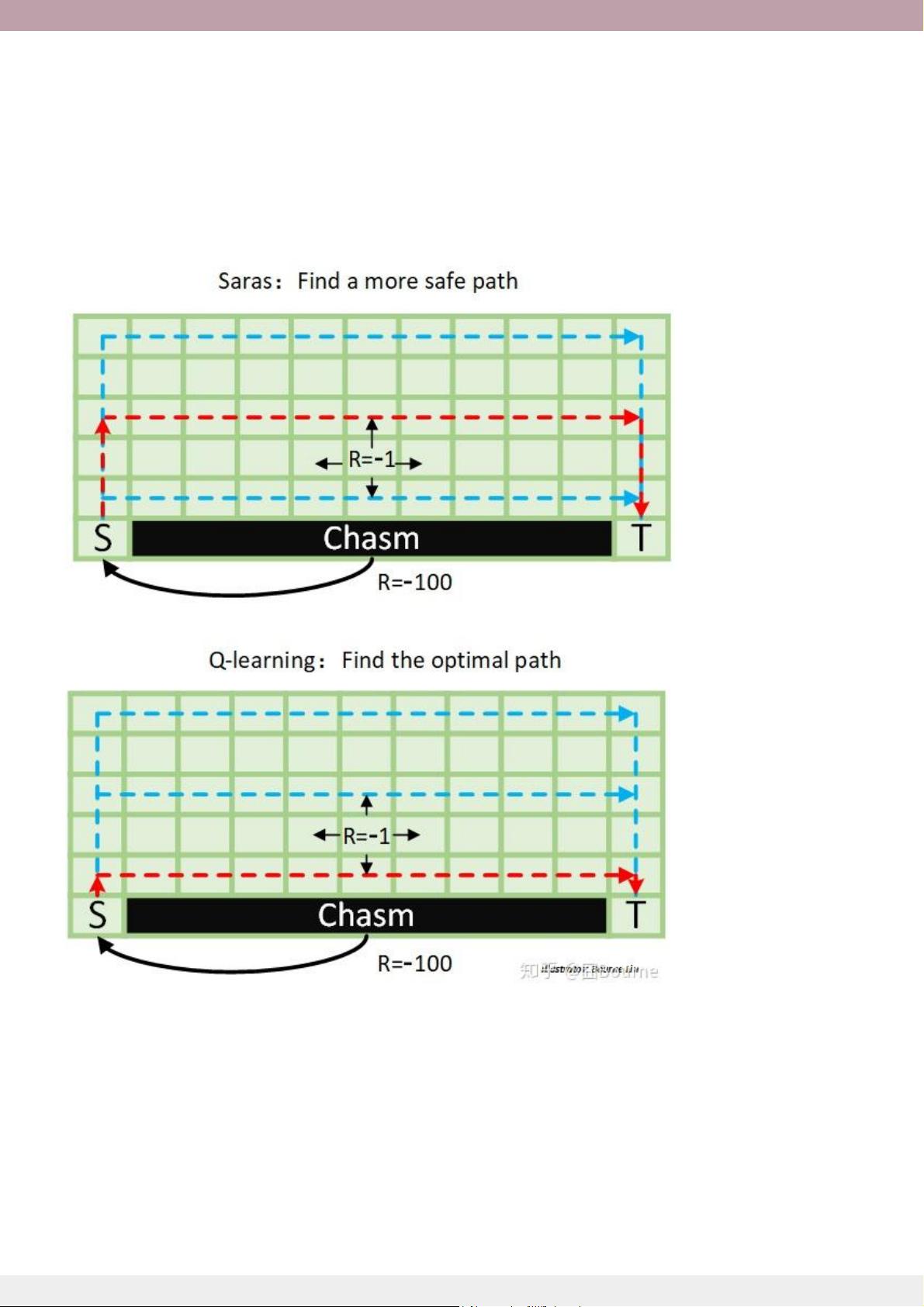
2. **Q-learning与Sarsa**
- Q-learning是一种离策略的强化学习算法,它通过更新Q值表来预测每个状态动作对的未来奖励。Sarsa是一种在线的On-Policy算法,它更新的是实际执行的动作的Q值。两者的核心区别在于对未来的估计方式和策略的更新机制。
3. **Policy Gradient方法**
- Policy Gradient是一种直接优化策略函数的方法,分为上、中、下三个部分详细讲解,旨在帮助读者理解其背后的思路和数学推导。
4. **基于人类演示和强化学习的夹爪训练**
- BAIR项目展示了如何使用人类演示和强化学习结合来训练夹爪机器人,强调了这种方法的高效性、通用性和低成本。
5. **Python与Matlab Engine的集成**
- 在Ubuntu 18.04中,介绍了如何在Python的虚拟环境中使用Matlab Engine,这对于数据处理和科学计算很有帮助。
6. **CUDA和PyTorch的安装**
- 提供了在Ubuntu 18.04上安装NVIDIA驱动、CUDA 10.2以及PyTorch的详细步骤,这对深度学习的实践者至关重要。
7. **强化学习算法的实践**
- 包含了DQN(Deep Q-Network)的简易代码实现分析,以及Udacity的深度强化学习课程笔记和项目报告,这些都是实际应用强化学习的实例。
8. **PPO算法的介绍**
- PPO(Proximal Policy Optimization)是强化学习中的一种先进算法,它在优化策略时平衡了探索与利用,避免了策略更新的剧烈波动。
9. **机器人环境的搭建**
- 展示了如何使用PyBullet、Gym和Stable Baselines3库创建机器人(如机械臂)的强化学习环境,这对于研究和实验是基础步骤。
10. **双臂机器人双手任务**
- 讨论了如何通过仿真学习让新型双臂机器人执行复杂的双手任务,这涉及到了多智能体和协调学习的问题。
这些内容为学习者提供了强化学习的理论基础,实践经验以及机器人应用的综合指导,适合于有一定背景知识的开发者或研究人员深入学习。

图a,假设已知黄色状态下只有两个动作可选:灰动作和黑动作,并且在第k-1次更新 Q
时,( 通过人为设置获取,不纳入更新迭代次数k),已知灰动(S=yellow,A) Q_{1}(S_t,a_t)
作价值比黑动作大,即有
Q_{m}(yellow,gray)>Q_{n}(yellow,black )
其中m,n为对应动作价值已迭代更新的次数,k为 更新的次数,所以有Q_{k}(yellow,action)
m+n= k。
图b,在某个回合(episode)中,在时间步为t的时候(time step = t),所处状态为黄色,又
已知灰动作价值比黑动作大,即基于 ε-greedy的行为策略选择动作,会出现情况①或②:
① 有 的可能性选择当前最大价值Q的灰动作 :(1- ε )+ ε /2=1- ε /2 a_n Q_{m+1}(s_t,
a_t)=Q_m(s_t,a_t)+\alpha[R_{t+1}+maxQ_i(s_{t+1},A_{t+1})-Q_m(s_t,a_t)]
而另一黑动作没有更新。
其中, 。s_t=yellow
② 有 的可能性选择当前较小价值Q的黑动作 :ε /2 a_n'
Q_{n+1}(s_t,a_t')=Q_n(s_t,a_t')+\alpha[R_{t+1}+maxQ_j(s_{t+1}',A_{t+1}')-Q_n(s_t,
a_t')]
而另一灰动作没有更新
其中, 。s_t=yellow
在此假设图b发生②的情况,则 。s_{t+1}'=green
图c通过选取 下的最大价值动作 来更新图f的目标策略。green a_j(red)
在第k+1次更新中,我们通过取最大值(即greedy思想),选取Q值最大的动作来更新目标策略
(target policy):\pi
Q_{k+1}^{\pi}(S=yellow,A)=max\left \{Q_{m}(S,gray),Q_{n+1}(S,black)\right \}
比如,基于上述已发生的,再发生图f的情况,则在下一次更新 时,Q_{k+1}^{\pi}(S=yellow,A)
黄色状态下的黑动作变为最优动作(颠覆了灰色动作有最大Q值的地位)。
(实际上无论发生情况①或是②,黄色状态下的灰动作与黑动作的价值的大小关系都可能发生变
化!!)
四、另一个栗子
强化学习2:Q-learning与Saras?流程图逐步解释
第 14 页 /共
124 页


剩余125页未读,继续阅读
2022-07-15 上传
2022-07-14 上传
2021-10-03 上传
2022-09-23 上传
2022-09-14 上传
2021-09-29 上传
2022-09-21 上传
2021-09-29 上传
2022-09-19 上传

北极象
- 粉丝: 1w+
- 资源: 401
 我的内容管理
展开
我的内容管理
展开







最新资源
- Angular程序高效加载与展示海量Excel数据技巧
- Argos客户端开发流程及Vue配置指南
- 基于源码的PHP Webshell审查工具介绍
- Mina任务部署Rpush教程与实践指南
- 密歇根大学主题新标签页壁纸与多功能扩展
- Golang编程入门:基础代码学习教程
- Aplysia吸引子分析MATLAB代码套件解读
- 程序性竞争问题解决实践指南
- lyra: Rust语言实现的特征提取POC功能
- Chrome扩展:NBA全明星新标签壁纸
- 探索通用Lisp用户空间文件系统clufs_0.7
- dheap: Haxe实现的高效D-ary堆算法
- 利用BladeRF实现简易VNA频率响应分析工具
- 深度解析Amazon SQS在C#中的应用实践
- 正义联盟计划管理系统:udemy-heroes-demo-09
- JavaScript语法jsonpointer替代实现介绍
