全面解析网络爬虫:自己动手写爬虫抓取网页
"自己动手写网络爬虫"
网络爬虫是一种自动化程序,它遍历互联网,抓取网页信息,以供进一步分析或存储。搜索引擎如百度和Google利用爬虫技术来搜集并更新庞大的网页数据库,以便用户进行快速有效的搜索。在本章中,我们将深入学习网络爬虫的原理和实现,教你如何编写自己的爬虫,从而能够自由抓取互联网上的任意信息。
首先,了解网络爬虫的基础——抓取网页。抓取网页始于URL(统一资源定位符),它是网页的唯一地址,例如http://www.lietu.com。在浏览器中输入URL,实际上是向服务器发送了一个请求,请求服务器将对应的网页内容发送回浏览器进行展示。通过查看浏览器的源代码,可以看到服务器返回的HTML文件。
URL是URI(统一资源标识符)的一个特例,URI用于唯一标识Web上的任何资源。一个URI通常包括三部分:访问资源的方式(如HTTP协议)、存放资源的服务器地址以及资源在服务器上的具体路径。例如,http://www.webmonkey.com.cn/html/h 这个URI表明我们要通过HTTP协议访问webmonkey.com.cn这个域名下的html目录中的某资源。
编写网络爬虫时,你需要掌握如何解析和处理URL,以及如何向服务器发送请求。在Java中,可以使用HttpURLConnection或者HttpClient库来实现HTTP请求。同时,理解HTTP状态码至关重要,因为它们反映了服务器对请求的响应状态,如200表示成功,404则表示请求的资源未找到。
除了基本的URL请求,网络爬虫还需要处理一些进阶问题,如网页的动态加载、登录验证、反爬策略等。对于动态加载的内容,可能需要使用如Selenium这样的工具模拟浏览器行为;对于需要登录的网站,爬虫需要模拟登录过程,可能涉及cookie和session管理;而面对反爬策略,可能需要设置合适的请求间隔,使用代理IP,或者利用User-Agent来模拟不同的用户行为。
此外,网络爬虫还需要处理大量数据的存储和解析。常见的网页解析库有Python的BeautifulSoup和JavaScript的 Cheerio,它们可以帮助我们提取和解析HTML中的结构化数据。数据存储方面,可以选择数据库如MySQL、MongoDB,或者文件系统如HDFS,根据需求选择合适的方式。
在实际应用中,网络爬虫可能用于构建数据仓库,提供多维度的数据展示,也可以作为数据挖掘的原始数据来源。例如,对于金融投资者,可以编写爬虫抓取股票市场信息,进行数据分析和预测。无论是在大型互联网公司还是个人项目,网络爬虫都有其广泛的应用场景。
掌握网络爬虫技术不仅能够帮助我们更好地理解互联网的工作机制,还能为我们提供获取和分析数据的强大工具。通过学习和实践,你将能够编写出高效、稳定的爬虫程序,实现定制化的信息获取需求。现在,让我们开始这段网络爬虫的探索之旅吧!
12
1
的遍历的方式对互联网这个超级大 “ 图 ” 进行访问。图的遍历通常可分为宽度优先遍历和
深度优先遍历两种方式。但是深度优先遍历可能会在深度上过 “ 深 ” 地遍历或者陷入 “ 黑
洞 ” ,大多数爬虫都不采用这种方式。另一方面,在爬取的时候,有时候也不能完全按照
宽度优先遍历的方式 , 而是给待遍历的网页赋予一定的优先级 , 根据这个优先级进行遍历
,
这种方法称为带偏好的遍历。本小节会分别介绍宽度优先遍历和带偏好的遍历。
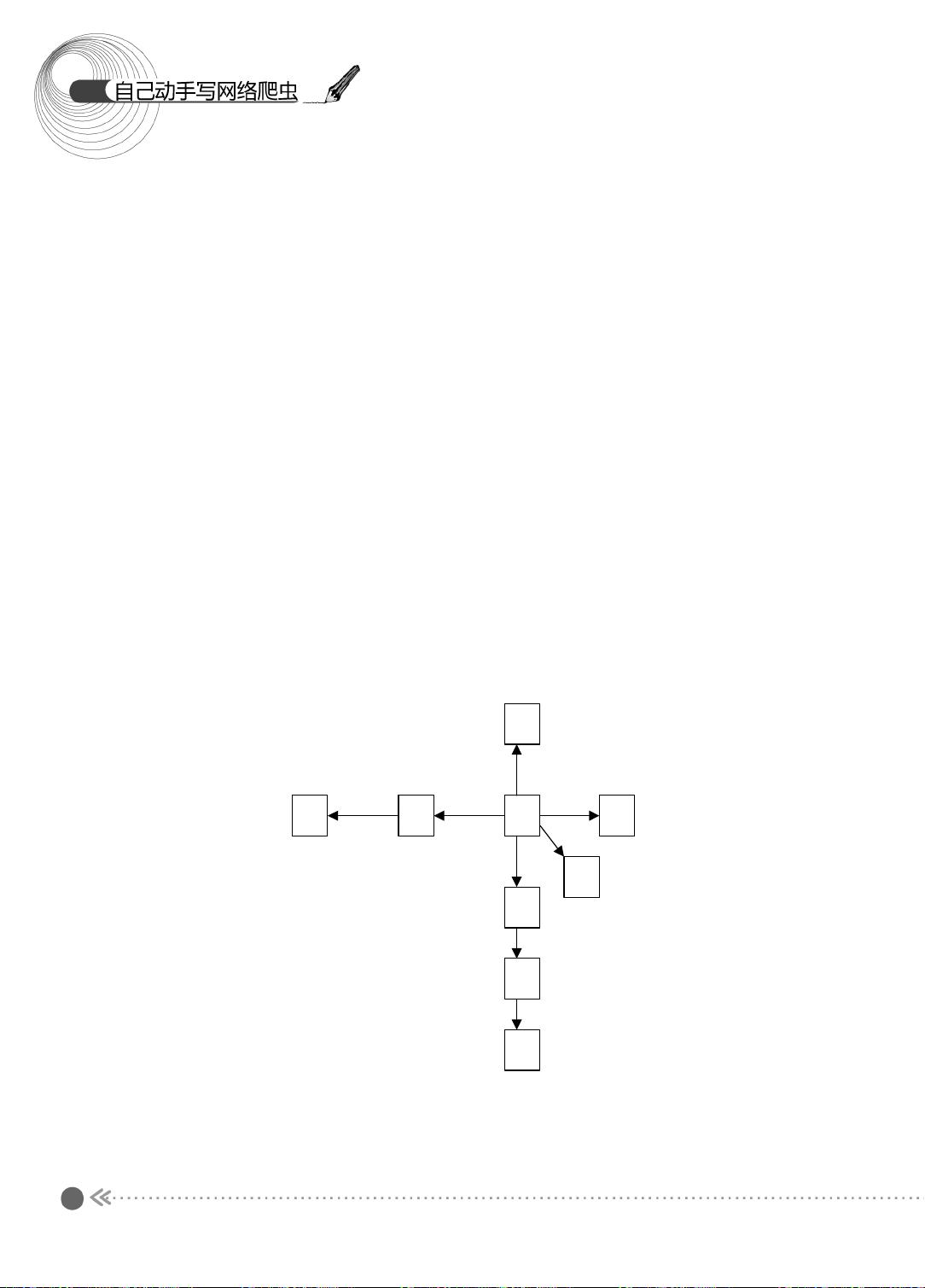
1.2.1 图的宽度优先遍历
下面先来看看图的宽度优先遍历过程 。 图的宽度优先遍历 (BFS) 算法是一个分层搜索的
过程,和树的层序遍历算法相同。在图中选中一个节点,作为起始节点,然后按照层次遍
历的方式,一层一层地进行访问。
图的宽度优先遍历需要一个队列作为保存当前节点的子节点的数据结构。具体的算法
如下所示:
(1) 顶点 V 入队列。
(2) 当队列非空时继续执行,否则算法为空。
(3) 出队列,获得队头节点 V ,访问顶点 V 并标记 V 已经被访问。
(4) 查找顶点 V 的第一个邻接顶点 col 。
(5) 若 V 的邻接顶点 col 未被访问过,则 col 进队列。
(6) 继续查找 V 的其他邻接顶点 col ,转到步骤 (5) ,若 V 的所有邻接顶点都已经被访
问过,则转到步骤 (2) 。
下面,我们以图示的方式介绍宽度优先遍历的过程,如图 1.3 所示。
G
B
A
C
D
F
E
I
H
图 1.3 宽度优先遍历过程

剩余67页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
2024-12-24 上传
2024-12-25 上传









