矩阵乘法性能优化:多线程+AVX256与Cache策略的实战报告
 已收录资源合集
已收录资源合集
需积分: 0 54 浏览量
更新于2024-08-05
收藏 438KB PDF 举报
本报告针对矩阵乘法性能优化进行深入研究,实验在Intel Core i5-4590处理器上进行,配备Windows 10专业版操作系统,使用Microsoft Visual Studio 2015 Enterprise作为开发环境。实验主要关注了以下几个关键性能提升策略:
1. **Cache利用优化**:通过将大矩阵划分为多个小块,利用L1、L2和L3级缓存(分别为256KB、1MB和6MB,每个级别有8个通道),先按块进行处理,然后折叠这些块到连续内存空间,减少内存访问次数,提高数据局部性,降低延迟。
2. **多线程并行计算**:采用四线程并行处理,通过合理分配任务负载,充分利用CPU核心,同时处理不同的矩阵部分,提高整体计算效率。
3. **AVX256指令集**:利用Intel CPU支持的高级矢量扩展指令集(AVX256),一次能够处理八个浮点数,极大地提升了单次操作的性能。
4. **边缘处理与矩阵转换**:对于边缘处理和矩阵转换等特殊情况,进行了针对性优化,以减少不必要的计算,进一步节省时间。
在实验中,当数据规模从1024维增长到10240维时,可以看到显著的性能提升。在小规模数据下,加速比并不稳定,但随着规模增大,加速比趋于稳定并接近30倍。例如,在1024维的矩阵乘法中,老师的程序运行时间为4.359秒,而优化后的程序只需0.137秒,加速比达到31.82。在更大的规模如10240维时,加速比更是达到了33.30。
图1显示了不同规模矩阵下的加速比趋势,表明在高维矩阵乘法中,优化效果更为明显。然而,由于运行时间过长,加速比记录并未做多次平均,实际效果可能更优。
通过对硬件参数的分析,特别是利用AVX指令集和多线程,以及巧妙地利用缓存,作者成功实现了矩阵乘法性能的显著提升。这种性能优化方法对于处理大规模矩阵运算在实际应用中具有重要意义,尤其是在科学计算、数据分析等领域,能够显著减少计算时间和内存占用。
矩阵乘法性能优化实验
一、实验配置
【平台】:Intel(R) Core(TM) i5-4590 CPU @ 3.30GHz、Windows10 专业版
【IDE】:Microsoft Visual Studio 2015 Enterprise
二、优化性能展示
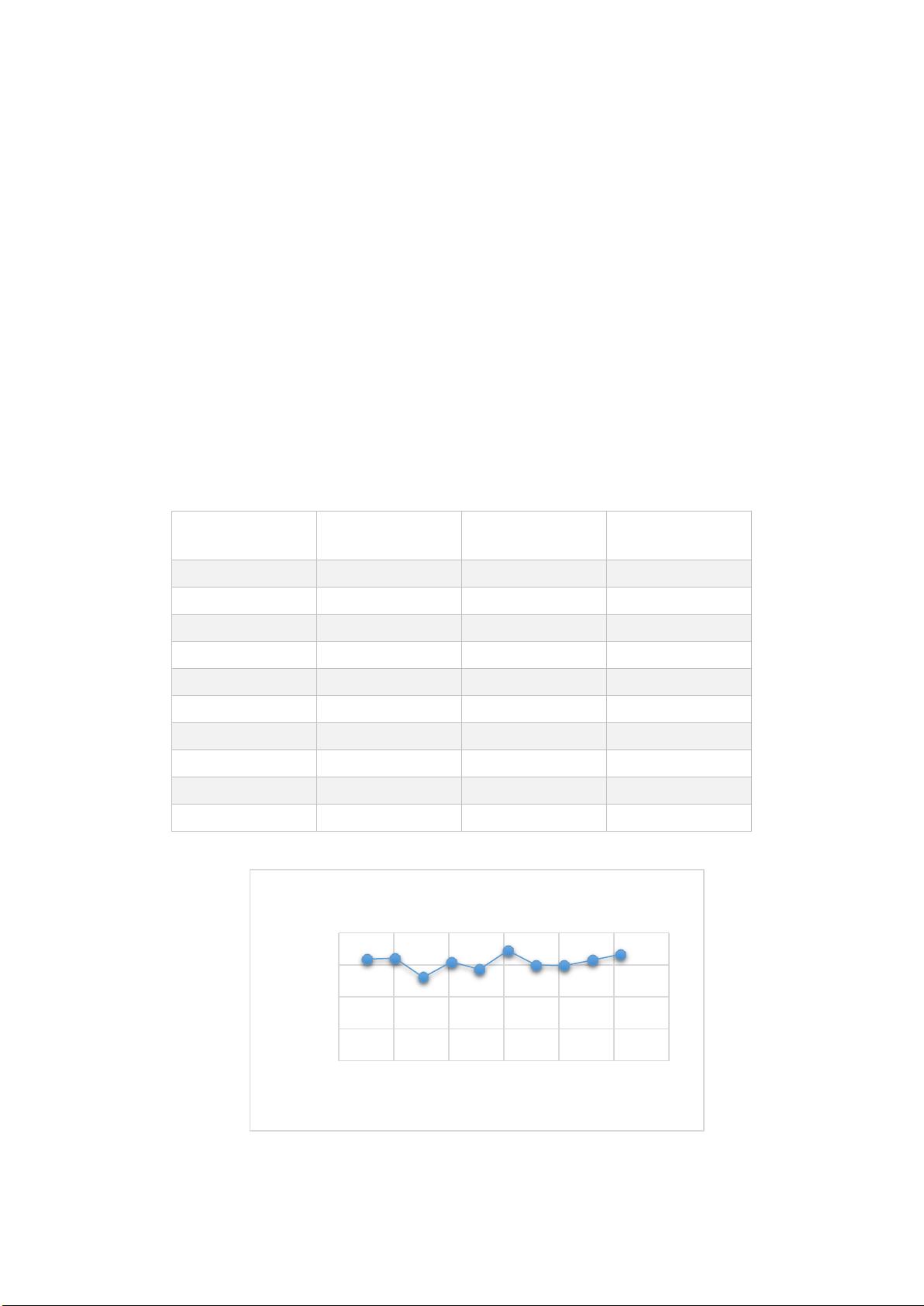
数据规模较小时,加速比不稳定,当数据规模增大到 2000 维以上时,可达到接近 30
倍的加速比。表 1 中展示的是从 1024 维到 10240 维的矩阵乘法运算的时间记录。
表 1 不同矩阵规模下的加速比
矩阵规模
老师的程序运行时间
T1(秒)
我的程序运行时间
T2(秒)
加速比(T1/T2)
1024
4.359
0.137
31.82
2048
34.67
1.08
32.10
3072
118.697
4.546
26.11
4096
276.356
8.935
30.93
5120
536.452
18.73
28.64
6144
962.734
27.905
34.50
7168
1471.89
49.167
29.94
8192
2288.99
76.873
29.78
9216
3226.3
102.493
31.48
10240
4289.64
128.812
33.30
注:由于运行时间太久,表中加速比只是一次运行的结果,没有多次执行求平均。
图 1 不同规模下的矩阵乘法加速比
从上图 1 中可以看出,矩阵规模 1024 维以上的时候,加速比在 30 附近徘徊。
0.00
10.00
20.00
30.00
40.00
0 2000 4000 6000 8000 10000 12000
加速比(
T1 / T2
)
矩阵规模
不同规模下的矩阵乘法加速比
下载后可阅读完整内容,剩余3页未读,立即下载
点击了解资源详情
311 浏览量
161 浏览量
2025-01-08 上传
2025-01-08 上传
2025-01-08 上传

光与火花
- 粉丝: 27
- 资源: 335
 我的内容管理
展开
我的内容管理
展开







最新资源
- 行业文档-设计装置-一种具有储存功能的杯子.zip
- caidata:收集,存储和提供CAI Bot的Planetside 2 CensusEvent数据
- MUNI-FI-PA179:MUNI-FI:PA179 20182019
- 宇泰 UT-8811 USB转RS232驱动程序.zip
- nsis打包工具教程集合
- rust-music-theory —锈音乐理论库-Rust开发
- XYCMS养老院建站系统 v3.5
- moveit-next
- Demolito:UCI国际象棋引擎
- 任务栏:产品定义和项目管理文件
- 03_gpio_key.rar
- part_2b_decoding_vectorized.zip
- java-mail-lib
- 全景图爬取程序Pano
- isahc-有趣的实用HTTP客户端-Rust开发
- 宇泰 UT-860 USB TO RS-232驱动.zip
