端到端视听融合:SDBN与BLSTM在语音识别中的注意力提升
133 浏览量
更新于2024-08-28
收藏 1.43MB PDF 举报
本文主要探讨了一种创新的端到端视听双模态语音识别技术,由宁波大学信息科学与工程学院的研究者王一鸣、陈恳和萨阿卜杜萨拉木·艾海提拉木提出。他们的工作集中在如何利用深度学习方法提升语音识别的准确性和鲁棒性。
首先,研究者采用了深度信念网络(DBN)的瓶颈结构,并引入混合的l1/2范数和l1范数,构建了一种稀疏DBN(SDBN)。这种设计旨在通过稀疏特征提取,有效地降低数据维度,减少冗余信息,提高模型的效率和表达能力。
接着,他们利用双向长短期记忆网络(BLSTM)进行时序建模,这是因为在语音识别中,考虑到语音信号的时间依赖性,BLSTM能够捕捉到长期依赖关系,增强对语音特征序列的理解。通过BLSTM,作者实现了对音频特征的高效处理。
文章的核心创新在于引入了一种注意力机制。这种机制使得算法能够自动对视觉(如嘴唇运动)和听觉(音频输入)信息进行对齐和融合,这意味着算法能够更加精确地结合两种模态的信息,提高了识别的准确性,尤其是在噪声环境下,视觉信息可以作为辅助,帮助模型更好地理解语音内容。
最后,融合后的视听觉信息被送入一个附加了Softmax层的BLSTM进行分类识别。Softmax层用于计算每个类别的概率,从而做出最终的语音类别决策。实验结果显示,这个端到端的视听语音识别算法在同类方法中表现出色,不仅识别率高,而且在处理复杂环境下的鲁棒性也得到了显著提升。
总结来说,这项研究展示了在视听语音识别领域,通过巧妙结合稀疏特征提取、深度神经网络和注意力机制,可以显著改进模型的性能,为未来的多模态语音识别技术提供了有价值的新思路。
·81· 电信科学 2019 年第 12 期
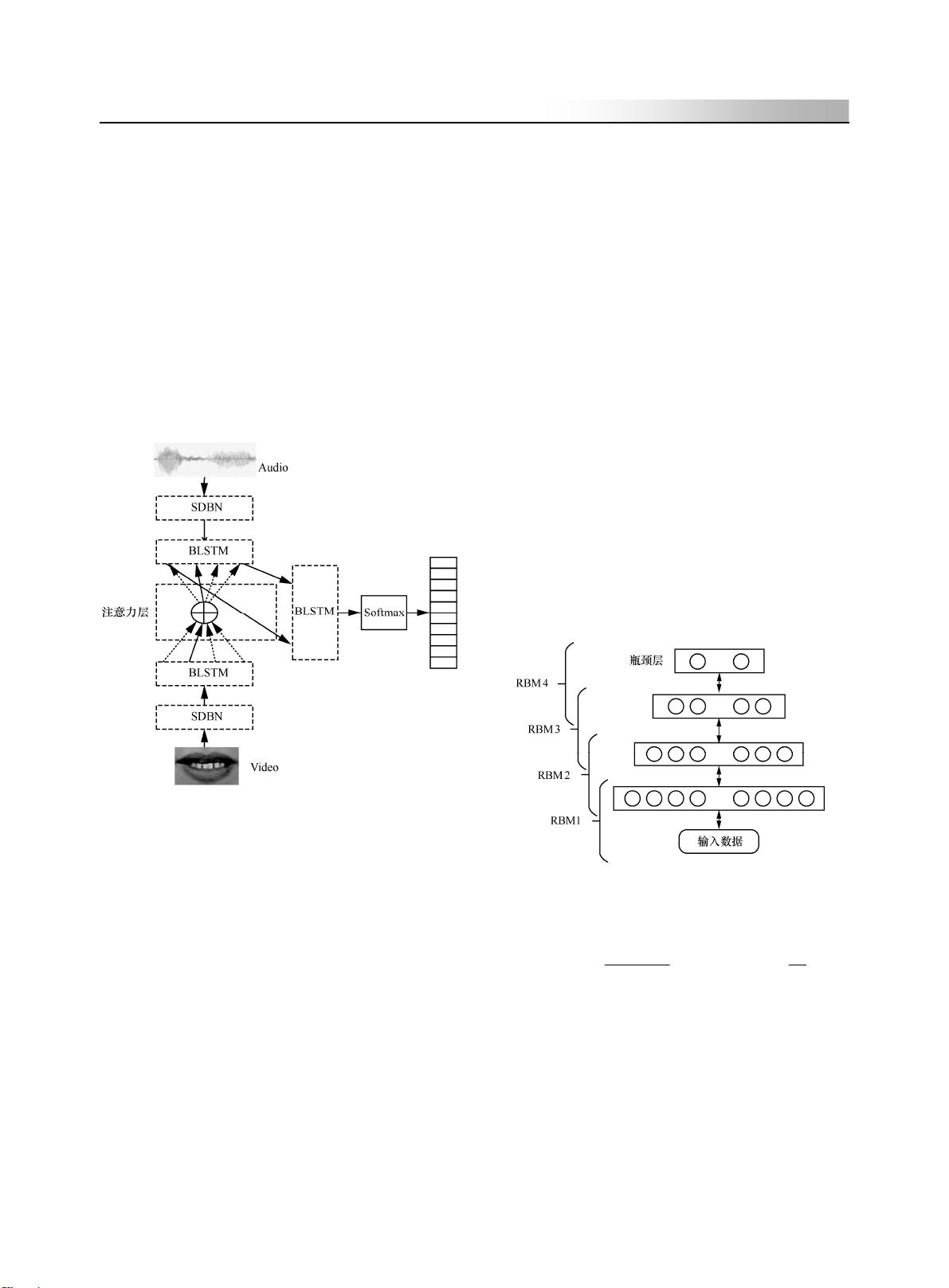
2 算法框架
本文算法框架模型如图 1 所示,主要步骤
如下。
步骤 1 预处理部分。首先对唇部视频帧序
列进行预处理,将视频帧裁剪为合适的统一尺寸,
并对其进行去均值和归一化处理;同时对原始语
音信号进行预加重、分帧、加窗、短时傅里叶变
换得到其声谱图,最后经过 Mel 滤波器组生成 Mel
频谱序列。
图 1 端到端视听双模态语音识别模型
步骤 2 提取稀疏瓶颈特征并进行模态处理。
通过在具有瓶颈结构 DBN 的目标函数中引入混
合的 l
1/2
范数和 l
1
范数来构建 SDBN,分别提取视
听觉信息的稀疏瓶颈特征,之后再各通过一个
BLSTM 在时序上对特征进行模态处理。
步骤 3 对视听觉信息进行融合。为将视听
流 BLSTM 输出的时序不一致的视听双模态向量
序列融合,引入一种注意力机制,通过计算每一
时序上音频流状态向量与所有唇部视觉流输出向
量的匹配度,之后将其与视觉流 BLSTM 的输出
做一种线性组合并与当前音频流 BLSTM 输出的
序列用一连接层融合,这样来自动对齐不同模态
的视听觉信息并融合,以提取出更高级的融合向
量序列,便于后续分类识别。
步骤 4 分类模型的设计。使用附加了
Softmax 层并与步骤 2 具有相同结构的 BLSTM 对
融合的序列信息进行分类识别。
3 基于 SDBN 和 BLSTM 注意力融合的视
听觉语音识别
3.1 稀疏深度信念网络
3.1.1 DBN
深度信念网络(deep belief network,DBN)
是由 Hinton 等人
[11]
提出的,它是由多个受限玻尔
兹曼机(restricted Boltzmann machine,RBM)堆
叠而成,每个 RBM 又分为显层和隐层。整个 DBN
自下而上呈瓶颈结构,顶层(瓶颈层)神经元最
少,其输出的特征又叫瓶颈特征(bottleneck
feature)
[12]
。典型的 DBN 结构图如图 2 所示。
图 2 典型的 DBN 结构示意
对于一个典型的 RBM,能量函数定义如下:
2
2
1111
1
()
(, | )
2
i
IJIJ
i
i
j
jjij
ijij
i
v
v
Evh bh hw
α
θ
σσ
====
−
=− − −
∑∑∑∑
(1)
其中,v
i
和 h
i
分别表示显层神经元和隐层神经元,
θ
{W, b, a}是一种模型连接参数(可看作权重 w
和偏置量 a
、
b 的一种组合),σ 为一种高斯噪声标
准差。
由 RBM 的能量函数可得显层与隐层神经元
2019290-3
剩余10页未读,继续阅读
2021-09-20 上传
2018-05-04 上传
2024-09-24 上传
2024-11-24 上传
2024-11-24 上传
2024-11-24 上传

weixin_38646914
- 粉丝: 1
- 资源: 938
 我的内容管理
展开
我的内容管理
展开







最新资源
- 俄罗斯RTSD数据集实现交通标志实时检测
- 易语言开发的文件批量改名工具使用Ex_Dui美化界面
- 爱心援助动态网页教程:前端开发实战指南
- 复旦微电子数字电路课件4章同步时序电路详解
- Dylan Manley的编程投资组合登录页面设计介绍
- Python实现H3K4me3与H3K27ac表观遗传标记域长度分析
- 易语言开源播放器项目:简易界面与强大的音频支持
- 介绍rxtx2.2全系统环境下的Java版本使用
- ZStack-CC2530 半开源协议栈使用与安装指南
- 易语言实现的八斗平台与淘宝评论采集软件开发
- Christiano响应式网站项目设计与技术特点
- QT图形框架中QGraphicRectItem的插入与缩放技术
- 组合逻辑电路深入解析与习题教程
- Vue+ECharts实现中国地图3D展示与交互功能
- MiSTer_MAME_SCRIPTS:自动下载MAME与HBMAME脚本指南
- 前端技术精髓:构建响应式盆栽展示网站
