Spark RDD实战:核心特性与内存计算优势
需积分: 25 9 浏览量
更新于2024-07-06
收藏 550KB DOCX 举报
Spark RDD 实战,基本语法
Spark 是一个强大的大数据处理框架,以其高可伸缩性、高容错性和内存计算的高效性而闻名。它作为伯利克分析栈(BDAS)的一部分,与Hadoop的生态系统相辅相成。Hadoop包括了MapReduce、HDFS、HBase、Hive等一系列组件,而BDAS则包含Spark、Shark(Hive的内存优化版本)、BlinkDB以及SparkStreaming等实时处理框架。
Spark相对于MapReduce的优势在于它的中间结果存储在内存中,这使得在进行迭代计算时性能显著提高。此外,Spark避免了MapReduce中的不必要的排序步骤,提高了处理效率。Spark的工作原理基于有向无环图(DAG),这允许对计算任务进行优化。
Spark提供了多种编程接口,包括Scala、Python和Java,使得不同背景的开发者都能方便地使用。它可以运行在Local模式(适用于测试和开发)、Standalone模式(独立集群)、Spark on YARN(在YARN上运行)以及Spark on Mesos(在Mesos上运行)。
在运行时,Spark的Driver程序启动多个Worker节点,每个Worker负责从文件系统加载数据并创建RDD。RDD,即弹性分布式数据集,是Spark的核心数据结构,它是只读的、分区的记录集合。RDD可以通过以下几种方式创建:
1. 集合转换:从现有的数据结构(如Scala或Java集合)创建RDD。
2. 从文件系统读取:如本地文件、HDFS或HBase等分布式存储系统。
3. 从父RDD转换:这种方式保证了容错性,因为如果某个分区丢失,可以通过父RDD重新计算。
RDD的计算主要分为两种类型:
1. Transformation:这些操作创建新的RDD,但并不立即执行。它们被延迟,直到遇到Action操作时才触发实际的计算。
2. Action:这类操作会触发Spark作业的提交,执行Transformation操作并产生最终结果。例如,collect、save等Action会将结果返回给驱动程序或写入外部存储。
与Hadoop的MapReduce相比,Spark的这种计算模型大大减少了数据处理的延迟,提升了整体性能。Spark的这种设计使得它在机器学习、图形处理和实时流处理等需要频繁迭代或交互的任务中表现优异。
() ,-:延迟执行,一个 通过该操作产生的新的
时不会立即执行,只有等到 操作才会真正执行。
*) :提交 作业,当 时,,- 类型
的操作才会真正执行计算操作,然后产生最终结果输出。
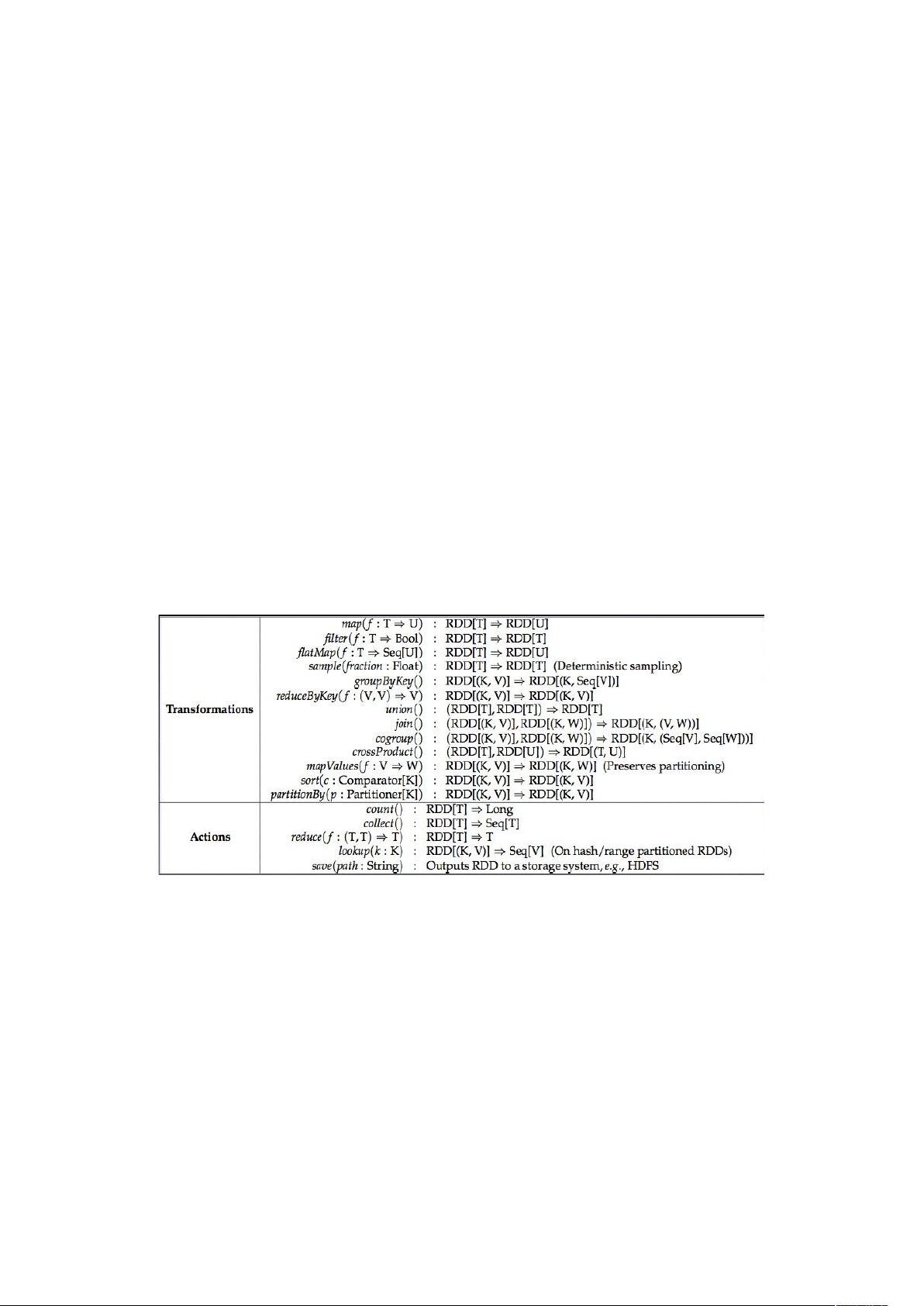
+) 提供处理的数据接口有 和 ,而 提供
的不仅仅有 和 还有更多对数据处理的接口,如图下
所示:
8. 容错 Lineage
1) 容错基本概念
每个 都会记录自己所依赖的父 ,一旦出现某个 的某些
丢失,可以通过并行计算迅速恢复
剩余22页未读,继续阅读
2019-01-02 上传
2018-04-08 上传
2016-03-18 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
2015-11-09 上传

bruce_wang_janet
- 粉丝: 65
- 资源: 17
 我的内容管理
展开
我的内容管理
展开







最新资源
- sweet_smoke_lp
- SPWM.rar_单片机开发_Windows_Unix_
- GMSMapView-Additions:自定义GMSMapView“我的位置”按钮
- Django_Network:Django社交网络
- ImageLab-Initial:ImageLab是一个独立工具,可让用户使用其GUI玩OpenCV
- Teste-oo1:用StackBlitz创建:high_voltage:
- Web应用程序和服务的集中式和分布式日志记录,扩展了System.Diagnostics和Essential.Diagnostics,提供了结构化的跟踪和日志记录,无需更改应用程序代码的1行-JavaScript开发
- torch_sparse-0.6.9-cp36-cp36m-macosx_10_9_x86_64whl.zip
- yukimryh.zip_matlab例程_matlab_
- TeTsuYa IRC Bot-开源
- qa_guru_4_10_owner_xt4k:草稿
- Assembla Mentions-crx插件
- 点击:简单的React useState钩子示例
- 参考资料-中国的书法艺术和技巧.蓝铁.zip
- 一个无主题的Web组件,用于根据表单字段值过滤可见的子元素。-JavaScript开发
- arduino-volume2:Arduino tone()-仅使用扬声器即可实现多种波形和8位音量控制!
