深度学习稀疏编码在CVPR12教程
"CVPR12深度学习稀疏编码教程由百度的余凯老师在CVPR2012上讲解,探讨了将深度学习与稀疏编码应用于计算机视觉识别的前沿技术。"
深度学习与稀疏编码是现代计算机视觉领域的重要组成部分,两者结合能够提升图像识别的准确性和效率。CVPR(Conference on Computer Vision and Pattern Recognition)是计算机视觉领域的顶级会议,而余凯老师的教程则聚焦于如何利用深度学习改进稀疏编码的方法。
稀疏编码是一种机器学习技术,它试图找到一种方式来表示数据,使得数据能够用少数非零系数(即“稀疏”表示)来描述。在图像处理中,这意味着图像特征可以被压缩并高效地存储,同时保留关键信息。这种技术在特征提取和选择过程中发挥着重要作用,尤其是在低级感知和预处理阶段。
传统的计算机视觉系统通常包含四个主要步骤:低级感知、预处理、特征提取、特征选择以及推断(如预测和识别)。其中,特征提取是最关键的准确性因素,也是测试时计算量最大的部分,而且在开发过程中耗时最多。在实践中,这些特征往往是人工设计的,例如SIFT(尺度不变特征转换)、HoG(方向梯度直方图)等。
然而,深度学习通过自动学习特征来改变这一局面,它提出以设计特征学习器取代手工设计特征。深度学习网络,如卷积神经网络(CNN),可以从数据中自动学习到多层次的抽象特征,而稀疏编码则为这种学习提供了一个有效的构建模块。在深度学习框架下,稀疏编码可以用于训练神经网络的权重初始化,或者作为激活函数的一部分,促进特征的稀疏性。
教程可能涵盖了如何使用深度学习模型(如深度信念网络DBN或深度自编码器AE)来优化稀疏编码过程,以及这些方法如何应用于大规模数据集,如Caltech101、PASCAL VOC、80 Million Tiny Images和ImageNet。通过这样的方法,研究者和工程师可以提升模型在复杂视觉识别任务中的性能,例如对象检测、分类和图像理解。
"CVPR12 Tutorial on Deep Learning Sparse Coding"深入讨论了如何结合深度学习与稀疏编码,以解决计算机视觉中的关键问题,推动了机器视觉感知能力的不断提升。这个教程对于理解和掌握这一先进技术具有极高的价值。
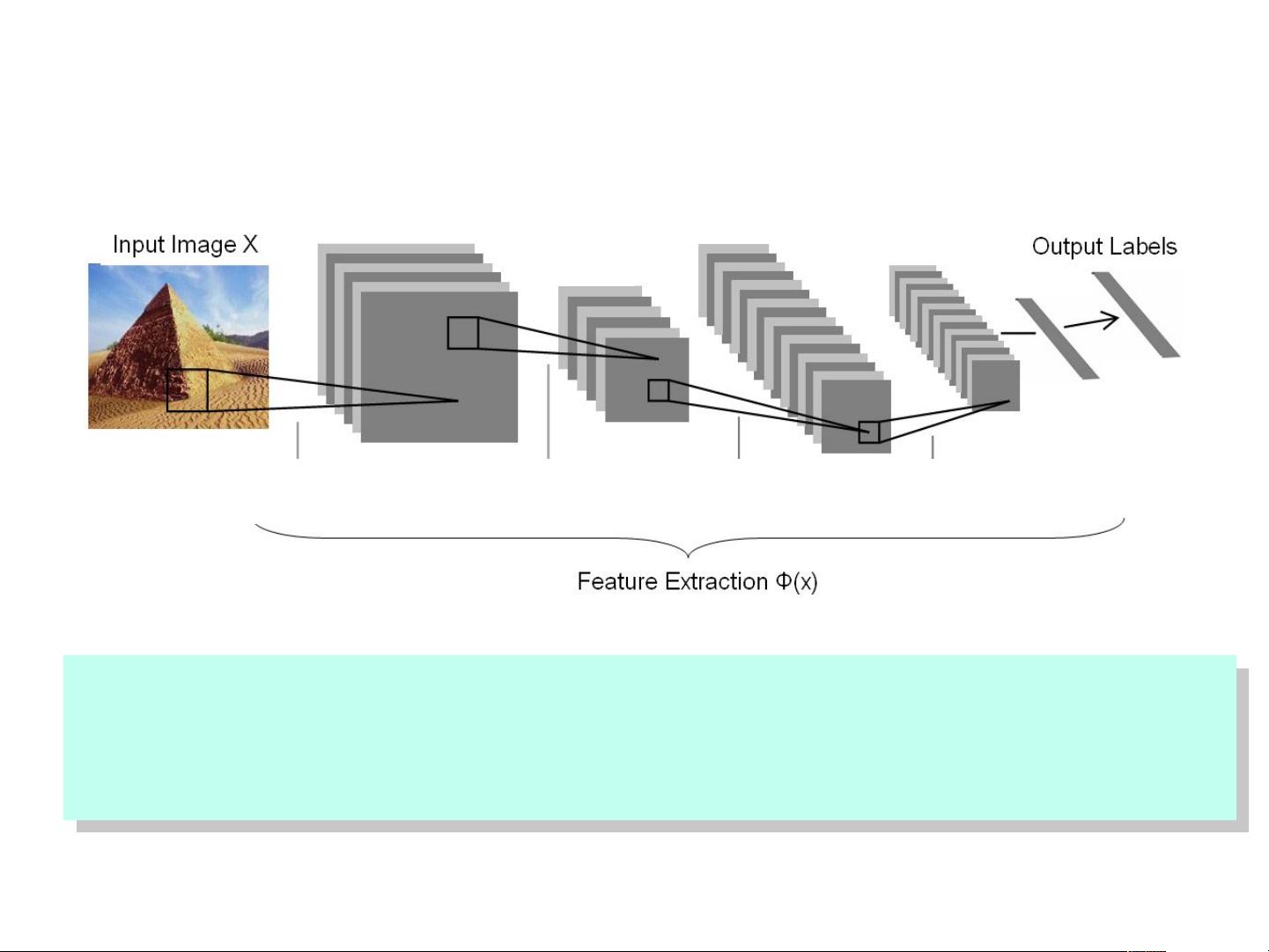
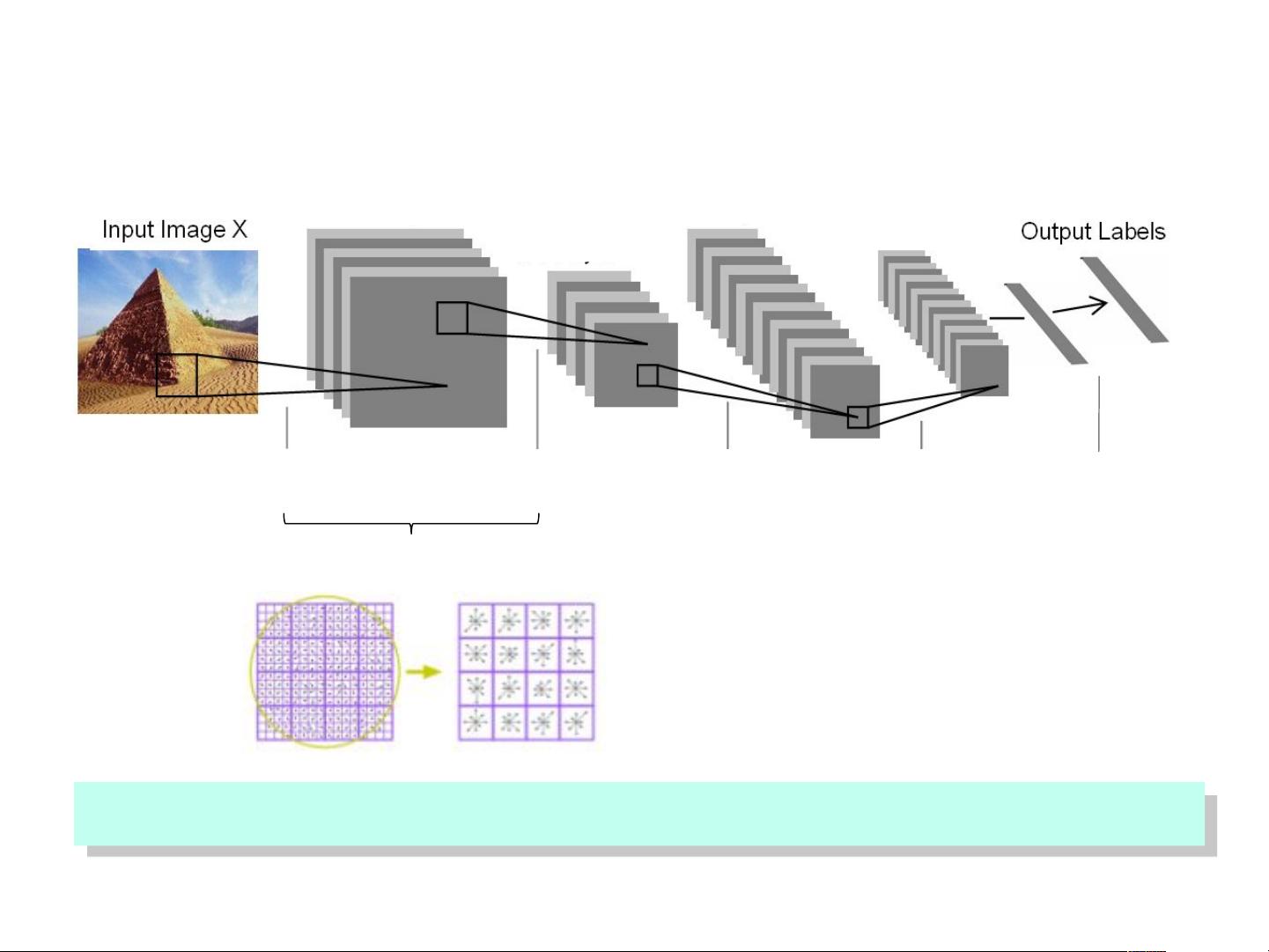
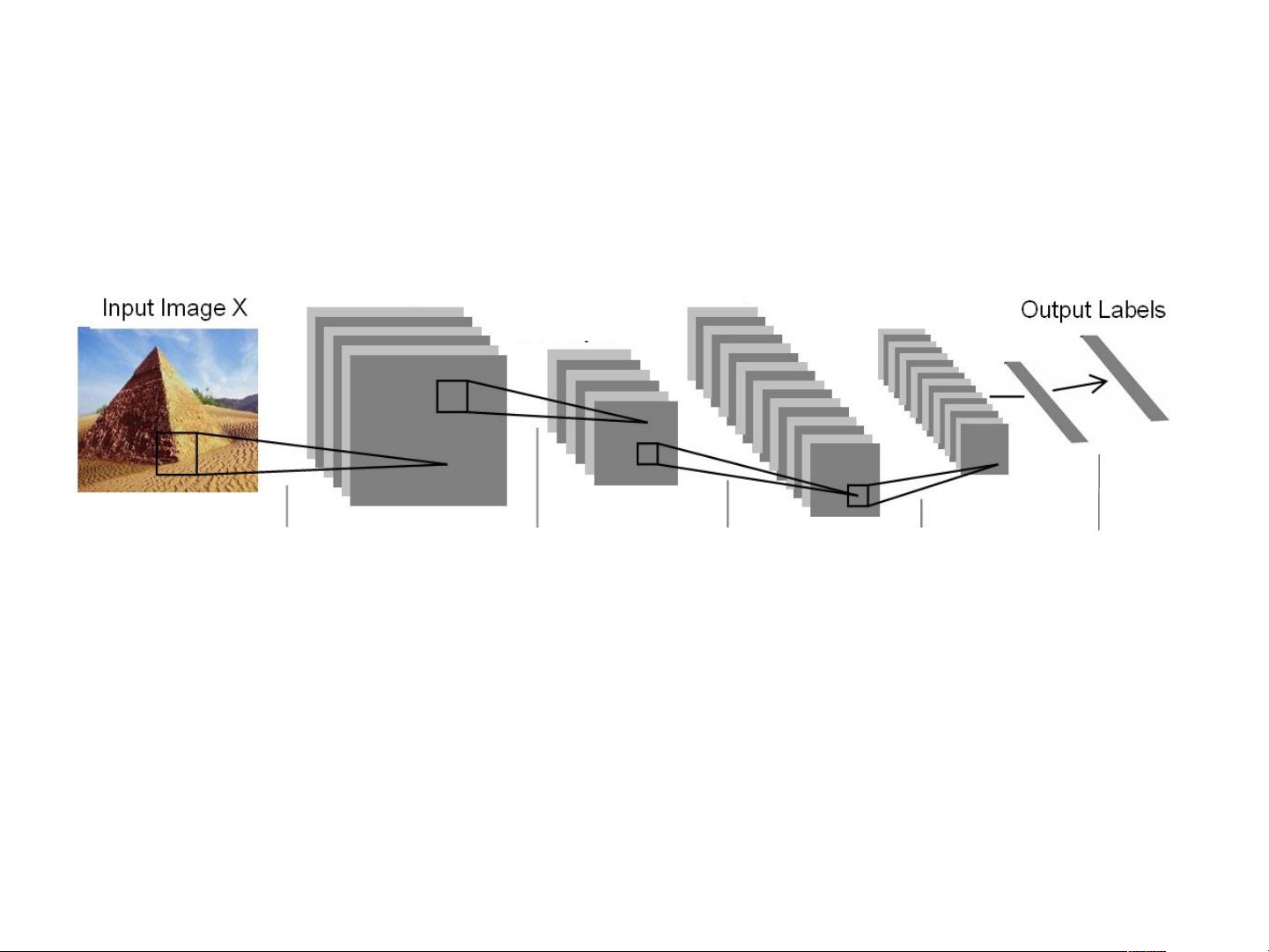
The Architecture of “Coding + Pooling”
11
•
e.g., convolutional neural net, HMAX, BoW, …
Coding Pooling Coding Pooling
剩余63页未读,继续阅读
2015-05-16 上传
2009-07-30 上传
2010-01-06 上传
2017-12-22 上传
2021-06-26 上传
2023-02-04 上传
2022-07-15 上传
2014-11-23 上传

Qinrui_Yan
- 粉丝: 105
- 资源: 5
 我的内容管理
展开
我的内容管理
展开







最新资源
- MATLAB实现小波阈值去噪:Visushrink硬软算法对比
- 易语言实现画板图像缩放功能教程
- 大模型推荐系统: 优化算法与模型压缩技术
- Stancy: 静态文件驱动的简单RESTful API与前端框架集成
- 掌握Java全文搜索:深入Apache Lucene开源系统
- 19计应19田超的Python7-1试题整理
- 易语言实现多线程网络时间同步源码解析
- 人工智能大模型学习与实践指南
- 掌握Markdown:从基础到高级技巧解析
- JS-PizzaStore: JS应用程序模拟披萨递送服务
- CAMV开源XML编辑器:编辑、验证、设计及架构工具集
- 医学免疫学情景化自动生成考题系统
- 易语言实现多语言界面编程教程
- MATLAB实现16种回归算法在数据挖掘中的应用
- ***内容构建指南:深入HTML与LaTeX
- Python实现维基百科“历史上的今天”数据抓取教程
