语义引导神经网络在骨骼人体动作识别中的创新应用
141 浏览量
更新于2025-01-16
收藏 682KB PDF 举报
"本文介绍了语义引导神经网络(SGN)在基于骨架的人体动作识别中的应用,强调了骨架数据在动作识别中的重要性,并提出了一种新的网络架构,该架构利用关节的高级语义信息增强特征表示能力。SGN包含关节级模块和帧级模块,分别用于处理关节间的相关性和帧间的依赖性。该模型在NTU60、NTU120和SYSU数据集上取得了最先进的性能,同时模型尺寸显著小于大多数大型工程。"
在基于骨架的人体动作识别中,由于骨架数据的易获取和结构化特性,它已经成为一种有效的输入方式。传统的做法常使用深层前馈神经网络来处理关节的三维坐标,但这种做法可能忽视了计算效率。SGN的提出是为了克服这个问题,它不仅考虑了关节的三维坐标,还引入了关节的高级语义信息,如关节类型和帧索引,这些信息有助于网络更好地理解动作的动态过程。
SGN的核心在于其设计的两个模块。关节级模块关注于同一帧内不同关节之间的相关性建模,这对于捕捉局部运动模式至关重要。帧级模块则着眼于整个帧的依赖性,通过将同一帧内的所有关节视为一个整体来捕捉动作的时间连续性,这有助于理解和识别跨时间的动作序列。
在设计上,SGN的模型尺寸显著减小,这意味着它在保持高识别性能的同时,也具备更高的计算效率和内存利用率。这为实际应用提供了可能性,尤其是在资源有限的设备上。图1展示了SGN在NTU60数据集上的精度与参数数量的比较,显示了SGN在模型大小和性能之间的优秀平衡。
实验结果显示,SGN在NTU60、NTU120和SYSU等标准数据集上都达到了最先进的识别性能。这表明,即使模型规模更小,SGN也能有效地捕获复杂的动作模式。这一成就对于推动人体动作识别领域的发展,特别是对于构建更加高效和准确的模型,有着重要的意义。
总结来说,"语义引导神经网络在基于骨架的人体动作识别中的应用"这一研究提出了一种新颖的神经网络架构,通过结合关节的高级语义信息和模块化的建模策略,实现了在保证识别性能的同时,大幅度降低了模型复杂度。这对于未来的研究者来说,提供了一个强有力的基线,可以进一步探索如何在骨骼数据基础上优化动作识别算法,以及如何在资源受限的环境中实现高效的动作识别系统。
1114
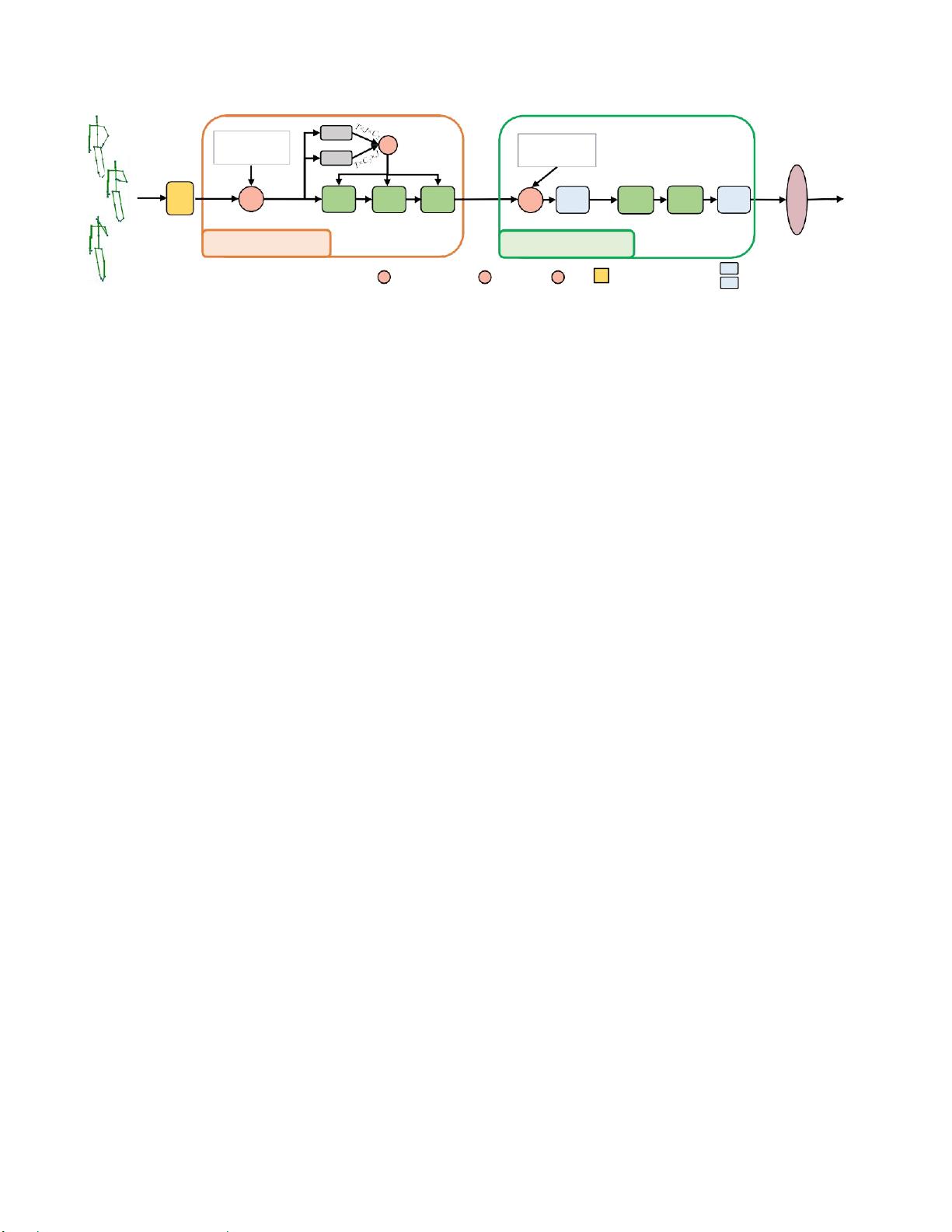
图2:提出的端到端语义引导神经网络(SGN)的框架。它由一个关节级模块和一个框架级模块组成。在DR中,
我们通过融合关节的位置和速度信息来学习关节的动力学表示两种类型的语义,
即
,关节类型和帧索引分别被合
并到关节级模块和帧级模块中。为了在关节级模块中对关节的依赖关系进行建模,我们使用三个GCN层。为了模
拟帧的依赖关系,我们使用两个CNN层。
使用前馈(
即,
,非递归)卷积神经网络用于建模语
音,语言[34,10,53,48]和骨架[18,58,30,51]中
的序列,由于其优越的性能。大多数基于机器学习的
方法将关节的坐标组织到2D地图,并调整
映射到一个尺寸(
例如
,224×224)适合CNN的输入
(
例如
,ResNet50 [12])。其行/列对应于
不同类型的关节/帧索引。在这些方法中[18,58,30,
51],长期依赖性和语义信息预计将被深度网络的大感
受野捕获这似乎是残酷的,通常会导致高模型复杂
性。
直观性、语义信息,
即
关节类型和帧索引对动作识
别非常重要。语义与动态(
即,
3D坐标)揭示了人体
关节的空间和时间配置/结构。我们知道,两个坐标相
同但语义不同的关节将传递非常不同的信息。例如,
对于头部上方的关节,如果该关节是手关节,则动作
可能是
举手
;如果是脚关节,则动作可能是
踢腿
。此
外,时间信息对动作识别也很重要以
坐下
和
站起来
这
两个动作为例,它们只是在帧的出现顺序上有所不
同。然而,大多数方法[11,47]都忽略了语义信息的
重要性,并对其进行了充分的探索.
为了解决当前方法的上述局限性,我们提出了一种
语义引导神经网络(SGN),它明确地利用语义和动
态来实现高效的基于语义的动作识别。图2示出了总体
框架。我们建立了一个层次化的网络,依次探索关节
级和帧级的依赖关系的骨架序列。为了更好地进行联
合级相关性建模,除了动力学之外,
ICS中,我们将联合类型的语义(e.
例如,在一
个实施
例中, 为了更好的帧级相关建模,我们将时态帧索引
的语义纳入网络。 特别地,我们对同一帧内的关节的
所有特征执行空间最大池化(SMP)操作以获得帧级
特征表示。结合嵌入的帧索引信息,使用两个时间卷
积神经网络层来学习用于分类的特征表示。此外,我
们开发了一个强大的基线,这是高性能和效率.由于语
义信息的有效探索,层次化建模和强大的基线,我们
提出的SGN实现了最先进的性能与少得多的参数。
我们总结了我们的三个主要贡献如下:
•
我们建议显式地探索联合语义(帧索引和联合类
型),以实现高效的基于图像的动作识别。以前的
作品忽略了重要的-
语义和依赖于深度网络具有高复杂性的动作识别。
•
我们提出了一个语义引导的神经网络(SGN),以
利用空间和时间的相关性,在联合水平
和帧级分层。
•
我们开发了一个轻量级的强大的基线,这是比大多
数以前的方法更强大。我们希望
强基线将有助于基于骨架的动作识别的研究。
通过上述技术贡献,我们获得了一个高性能的基于
机器人的动作识别模型,具有较高的计算效率。广泛
的消融研究证明了所提出的模型设计的有效性。三大
基准
FC
层
接头类型
:
头,
...
,脚
θ
:
1
×
1
φ:1×
×
G
帧索引
:
1
、
2
、
.
、
T
公司
简介
博
士
速度
位置
T×J
×C
1
C
T×J ×2C
1
GCN
GCN
GCN
T×J
×C
3
+
SMP CNN
T×1×C
3
CNN
TMP
1× 1×
C
4
类标
签
关节级模块
帧级模块
SMP
空间最大池化
C
n
:尺寸 T:帧编号
J
:
关节数
×
矩阵乘法
C
级联
+
Sum DR
动态表示
TMP
时间最大池化
…
剩余10页未读,继续阅读
2021-09-26 上传
290 浏览量
383 浏览量
2024-12-27 上传
2025-02-24 上传
2024-11-07 上传
2025-01-06 上传
2025-01-16 上传
2025-01-23 上传

cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- ITween插件实用教程:路径运动与应用案例
- React三纤维动态渐变背景应用程序开发指南
- 使用Office组件实现WinForm下Word文档合并功能
- RS232串口驱动:Z-TEK转接头兼容性验证
- 昆仑通态MCGS西门子CP443-1以太网驱动详解
- 同步流密码实验研究报告与实现分析
- Android高级应用开发教程与实践案例解析
- 深入解读ISO-26262汽车电子功能安全国标版
- Udemy Rails课程实践:开发财务跟踪器应用
- BIG-IP LTM配置详解及虚拟服务器管理手册
- BB FlashBack Pro 2.7.6软件深度体验分享
- Java版Google Map Api调用样例程序演示
- 探索设计工具与材料弹性特性:模量与泊松比
- JAGS-PHP:一款PHP实现的Gemini协议服务器
- 自定义线性布局WidgetDemo简易教程
- 奥迪A5双门轿跑SolidWorks模型下载
