改进神经机器翻译:掩码标签平滑与词汇共享的融合研究
129 浏览量
更新于2025-01-16
收藏 508KB PDF 举报
本文主要探讨了神经机器翻译(NMT)中的两种关键技术——标签平滑(LS)和词汇共享(VS),以及它们可能存在的冲突和改进方法。作者提出了一个新的机制,称为Masked Label Smoothing (MLS),以解决标签平滑与词汇共享之间的潜在问题,旨在提高翻译质量和模型的校准。
在神经机器翻译中,标签平滑是一种正则化技术,它通过将硬独热标签转换为软标签分布来防止过拟合和过度自信。这种技术将黄金标签的单一概率分配扩散到整个词汇表,从而引入了一定程度的不确定性。然而,简单应用标签平滑可能会导致源端单词和目标端单词的不对等处理,尤其是在目标语言中不存在的源端单词,这可能会使翻译模型产生偏差。
另一方面,词汇共享是一种优化方法,特别是在处理多语言任务时,它允许模型在源语言和目标语言之间共享词汇表的一部分,以减少词汇表大小并促进跨语言的迁移学习。尽管这种方法可以提高效率,但与标签平滑结合使用时可能会出现冲突。
针对这一问题,作者提出了Masked Label Smoothing (MLS)机制。MLS在标签平滑过程中,将源端单词的软标签概率设为零,即对源端单词进行“遮罩”,这样可以确保源端单词不会直接影响目标端的概率分布,从而缓解了源端和目标端处理的不平等性。通过实验,作者证明了MLS在多种数据集上的翻译质量和模型校准上均优于传统的标签平滑方法,尤其是在双语和多语言翻译任务中。
实验结果显示,应用MLS的模型在IWEL2014 DE-EN和IWEL2015 VI-EN数据集上的性能优于仅使用标签平滑或词汇共享的模型。这些结果强调了MLS作为改进NMT性能的有效策略,特别是在结合标签平滑和词汇共享时。
本文对神经机器翻译中的关键技术和潜在问题进行了深入分析,并提出了一种新的解决方案。通过对标签平滑和词汇共享的整合,MLS为提高翻译质量和模型性能提供了新的视角,这对于NMT领域的研究和实践具有重要意义。
+v:mala2277获取更多论
文
†
专注于目标
陈亮,徐润新,常
宝宝
北京大学计算语言学重点实验室,MoE,中国
leo.liang.
outlook.comrunxinxu@gmail.comchbb@
pku.edu.cn
摘要
标签平滑和词汇共享是神经机器翻译模型
中广泛使用的 两 种 技术。然而,我们 认
为,简单地应用这两种技术可能会产生冲
突,甚至导致次优性能。当分配平滑概率
时-
中国日语
S
为圣
C
und der
sch@@
die
.
…
不
下
一 个 理
事 会
ri@@
德语英语
实际上,原始标签平滑将永远不会出现在
目标语言中的源端单词与真实目标端单词
同等对待,这可能使翻译模型产生偏差。
为了解决这个问题,我们建议戴面具的La-
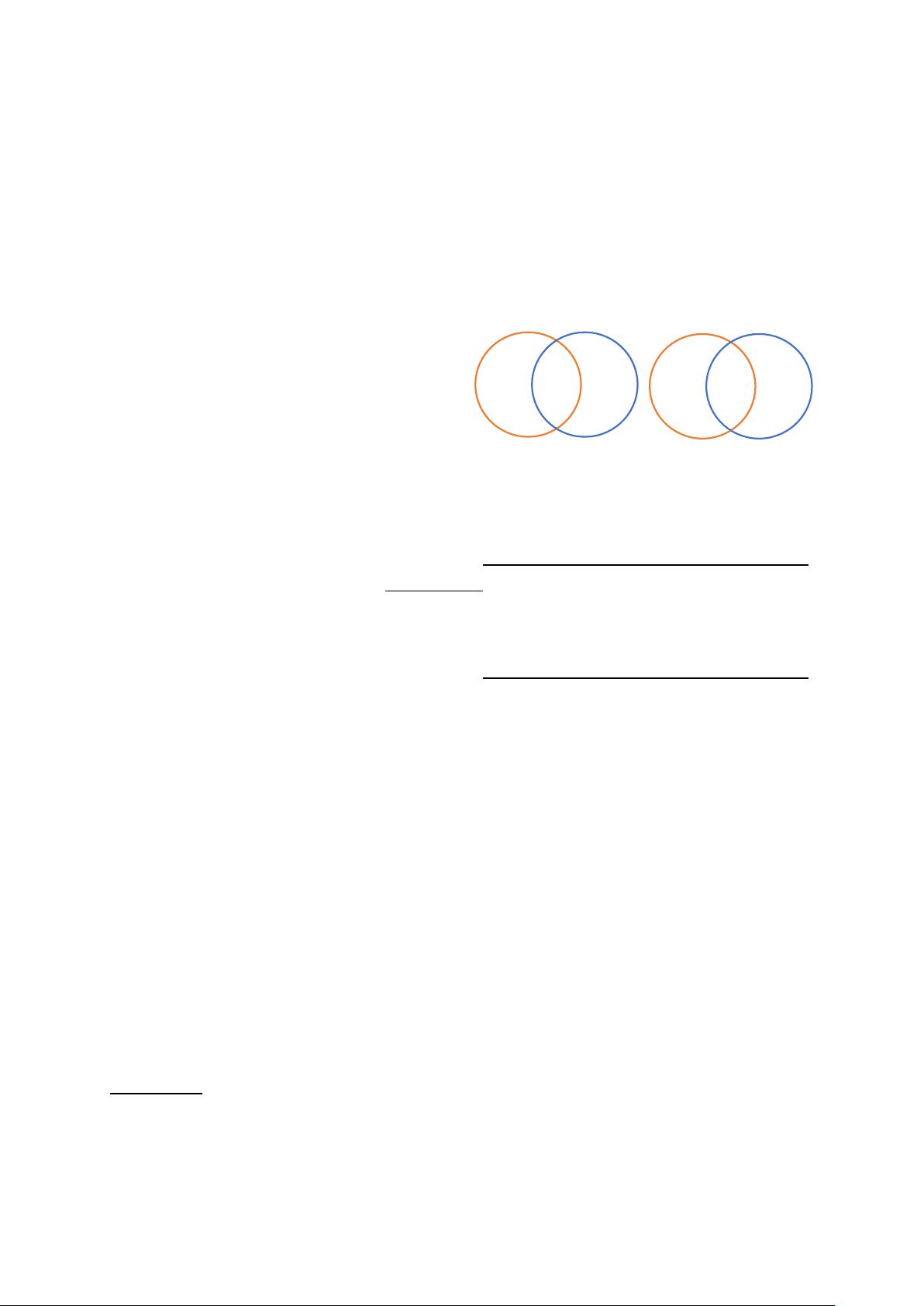
图1:维恩图显示了
共享词汇表,可以分为三个部分:源(S)、公共
(C)和目标(T)。
型号
DE-EN VI-EN
贝尔平滑(MLS),一种新的机制,
将源端单词的软标签概率屏蔽为零。简单
而有效,MLS设法更好地集成标签平滑与
词汇共享。我们广泛的实验表明,MLS在
不同的数据集上,包括从翻译质量和模型
校准的双语和多语言翻译上,始终比原始
标签平滑我们的代码在PKUnlp-icler发布。
1
介绍
基于transformer的最新进展(Vaswaniet al. ,
2017
)模型在神经机器翻译(
NMT
)中取得
了 显 着 的 成 功 。 对 于 大 多 数 NMT 研 究
(
Vaswani et al.
,
2017; Songet al.
,
2019; Lin
et al. ,2020; Pan等人,2021),有两种广泛
使 用 的 技 术 来 提 高 翻 译 质 量 : 标 签 平 滑
( LS ) 和 词 汇 共 享 ( VS ) 。 标 签 平 滑
(
Pereyra
等人,
2017
)将
硬
独热标签变成黄
金标签和整个词汇表上的均匀分布的软加权混
合物,其用作有效的正则化技术以防止过度拟
合和过度置信(Müller等人,2017)。2019
年)的模型。此外,词汇共享(Xia et al. ,
2019
年)是另一种常用的技术,
*
通讯作者
Transformer 33.54 29.95
- 带标签平滑(LS)34.76 30.73
- w/词汇共享(VS)33.83 29.36
- 带LS+VS
†
34.56 30.41
表1:IWEL 2014 DE-EN和IWEL 2015 VI-EN数据
集的结果 表示一致设置为(Vaswaniet al. ,2017
年)。联合采用标签平滑和向量共享技术不能实现
进一步的改进,但会导致次优性能。
源语言和目标语言的词汇合并成一个完整的词
汇,因此词汇是共享的。该方法增强了两种语
言之间的语义相关性,减少了嵌入矩阵的总参
数数。
然而,在本文中,我们认为,同时采用标签
平滑和词汇共享技术可能是冲突的,并导致次
优性能。具体来说,对于词汇表共享,共享词
汇表可以分为三个部分,如图
1
所示。但是通
过标签平滑,软标签仍然会考虑源端不可能出
现在目标端的单词。这会误导翻译模式,影响
翻译效果.如表1所示,虽然单独引入标签平滑
或词汇表共享可以改进普通
Transformer
,
S CT
然, 政,然然,然然,
然,然,然然,然,然然,然,
然
arXiv
:
2203.02889v1 [cs.CL] 2022
年
3
下载后可阅读完整内容,剩余6页未读,立即下载
2025-03-06 上传
2025-03-06 上传
2025-03-06 上传
2025-03-06 上传

cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- ITween插件实用教程:路径运动与应用案例
- React三纤维动态渐变背景应用程序开发指南
- 使用Office组件实现WinForm下Word文档合并功能
- RS232串口驱动:Z-TEK转接头兼容性验证
- 昆仑通态MCGS西门子CP443-1以太网驱动详解
- 同步流密码实验研究报告与实现分析
- Android高级应用开发教程与实践案例解析
- 深入解读ISO-26262汽车电子功能安全国标版
- Udemy Rails课程实践:开发财务跟踪器应用
- BIG-IP LTM配置详解及虚拟服务器管理手册
- BB FlashBack Pro 2.7.6软件深度体验分享
- Java版Google Map Api调用样例程序演示
- 探索设计工具与材料弹性特性:模量与泊松比
- JAGS-PHP:一款PHP实现的Gemini协议服务器
- 自定义线性布局WidgetDemo简易教程
- 奥迪A5双门轿跑SolidWorks模型下载
