深度学习中的全局类表示与少数样本学习研究
PDF格式 | 647KB |
更新于2025-01-16
| 191 浏览量 | 举报
"全局类表示学习及少数样本问题的研究"
在当前的深度学习领域,模型的泛化能力受限于大量标注数据的需求,尤其是在处理稀有类别时。为解决这一问题,"全局类表示学习"成为了一个重要的研究方向。该文提出了一种针对"少数拍摄学习"(Few-Shot Learning, FSL)的新方法,旨在利用基础类别的大量样本和新类别的少量样本来学习全局类表示。
文章指出,传统的基于元学习的方法通常在有限的支持集上训练模型,然后在查询集上进行评估。然而,这种方法往往忽视了新类别的训练样本,导致模型在面对新类别时表现不佳。为此,作者提出了一个创新的解决方案:通过计算支持集中每个片段的类均值,并利用注册模块将这些片段与全局表示进行对齐,生成注册的全局类表示。这个过程有助于提高模型对新类别数据的识别能力。
此外,为了解决新类别样本不足的问题,论文还引入了一种有效的样本合成策略。通过生成合成样本,增加了新类别内部的多样性,从而增强模型的学习能力。这种方法不仅适用于标准的FSL场景,还能扩展到更具挑战性的"广义FSL"(Generalized Few-Shot Learning)情况,即测试数据可能包含基类和新类的标签。
实验结果证明,该方法在FSL和广义FSL设置下都表现出优越的性能,展示了其在应对小样本学习问题上的潜力。通过结合基础类和新类的样本进行全局表示学习,模型能够更好地适应和区分不同的类别,提高了识别的准确性和泛化能力。
这篇研究为深度学习模型在处理稀有类别和小样本数据时提供了新的思路,即通过全局类表示学习,增强了模型对未见过类别数据的理解和识别能力,这对于未来人工智能在现实世界中的广泛应用具有重要意义。
9715
使用全局类表示的
李傲雪
1 *
罗
天歌
1 *
陶翔
2
黄蔚然
3
王 立伟
1
1
北京
大学机电工程学院
2
英国萨里大学电气与电子工程系
3
华为诺亚
{lax,luotg,wanglw}@ pku.edu.cn,t.xiang@ surrey.ac.uk,huang. outlook.com
摘要
在本文中,我们提出了解决具有挑战性的少数拍摄
学习(
FSL
)的问题,学习全局类表示使用基础和新
的类训练样本。在每个训练片段中,从支持集计算的
片段类均值经由注册模块与全局表示注册这将产生一
个注册的全局类表示,用于使用查询集计算分类损
失。虽然遵循与现有的基于
Meta
学习的方法类似的情
景训练管道,但我们的方法显着不同,因为从一开始
就涉及新的类训练样本为了弥补新类训练样本的不
足,提出了一种有效的样本合成策略重要的是,通过
联合基础新类训练,我们的方法可以很容易地扩展到
更实用但具有挑战性的
FSL
设置,即,广义
FSL
,其中
测试数据的标签空间扩展到基类和新类。大量的实验
表明,我们的方法是有效的两个
FSL
设置。
1.
介绍
深度学习在各种识别任务中取得了巨大成功[32,
31]。然而,由于参数数量庞大,深度神经网络需要每
个类的大量标记数据来进行模型训练。这严重限制了
它们的可扩展性-对于许多罕见的类,收集大量的训练
样本是不可行的,甚至是不可能的。相比之下,人类
可以很容易地识别一个新的对象类后,只看到它一
次。受人类的少次学习能力的启发,最近对少次学习
(FSL)的兴趣越来越大[8,12,21,7,23,19,
28,22]。在FSL问题中,我们提供了一组基本类,每
个类都有足够的训练样本,以及一组只有几个的新类
*
同等缴款。
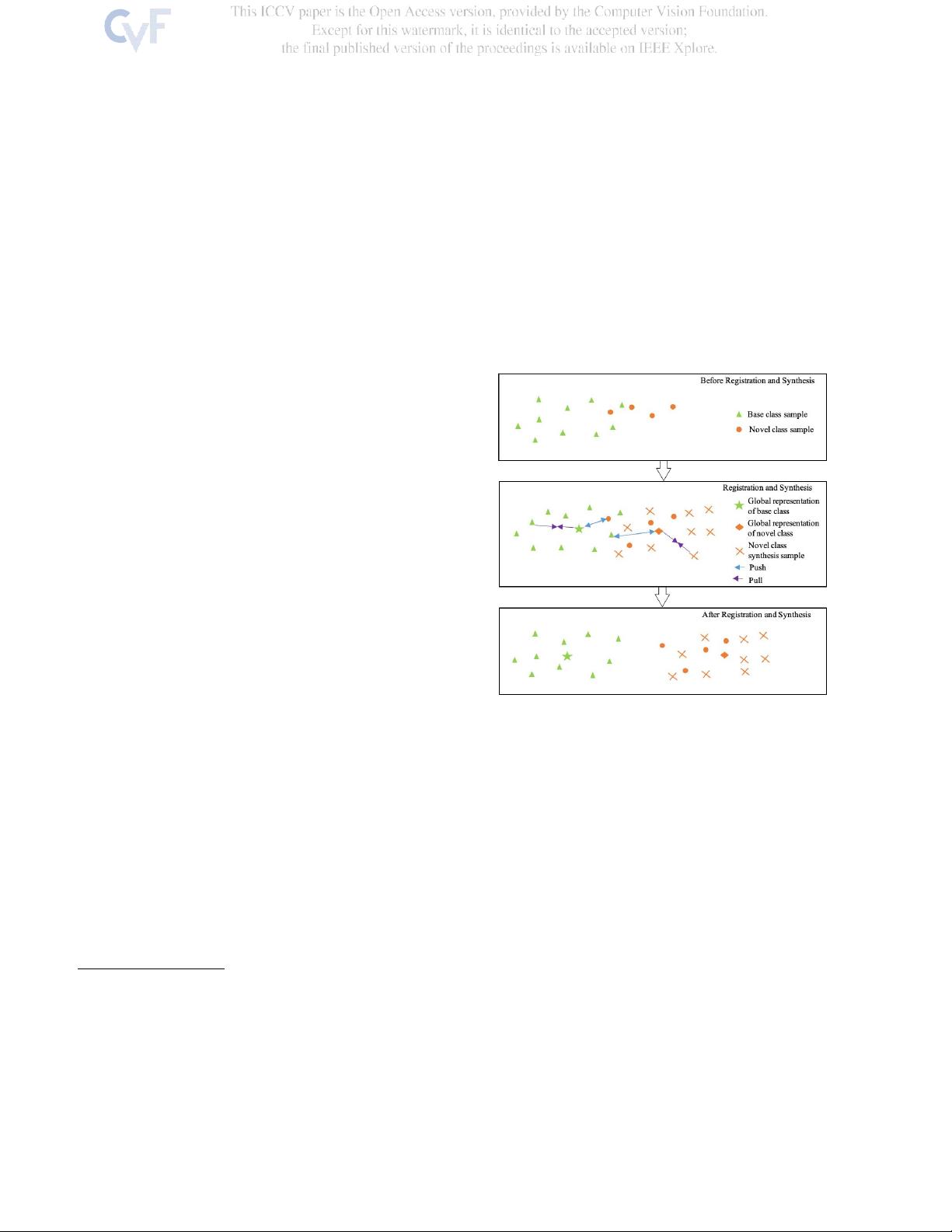
图
1.
我们的方法的一个例证。第一个块显示了嵌入空间中的
基类和新类基类包含足够的标记数据,而新类只有少量的标
记数据。这两个类有交集,我们的目标是学习用于重新识别
测试数据的每个类的全局表示。第二块说明了所提出的模型
的两个关键组成部分。首先,我们生成新的样本(橙色交
叉),以增加新类的类内方差。第二,注册模块,建议鼓励
样本
“
拉
”
其全球代表自己和
“
推
”
其他全球代表了。同样,全
局表示也会影响样本。最后一个块显示了使用基础和新类样
本联合学习全局表示后的结果。这两个类变得更加可分离,
并且全局表示更加可区分。
每个类别的标记样本(镜头)。FSL的目标是通过从
基本类中转移知识来学习用于具有较少镜头的新颖类
的类指示符。
大多数现有的FSL方法是基于Meta学习。在Meta学
习阶段,对基本类进行采样,以模拟新类的少量学习
条件。可转移的知识是从
下载后可阅读完整内容,剩余9页未读,立即下载
相关推荐





cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- Openaea:Unity下开源fanmad-aea游戏开发
- Eclipse中实用的Maven3插件指南
- 批量查询软件发布:轻松掌握搜索引擎下拉关键词
- 《C#技术内幕》源代码解析与学习指南
- Carmon广义切比雪夫滤波器综合与耦合矩阵分析
- C++在MFC框架下实时采集Kinect深度及彩色图像
- 代码研究员的Markdown阅读笔记解析
- 基于TCP/UDP的数据采集与端口监听系统
- 探索CDirDialog:高效的文件路径选择对话框
- PIC24单片机开发全攻略:原理与编程指南
- 实现文字焦点切换特效与滤镜滚动效果的JavaScript代码
- Flask API入门教程:快速设置与运行
- Matlab实现的说话人识别和确认系统
- 全面操作OpenFlight格式的API安装指南
- 基于C++的书店管理系统课程设计与源码解析
- Apache Tomcat 7.0.42版本压缩包发布
